网站三的反爬破解
1、请求url,查看数据情况
首先我们请求想要爬取的页面url,根据页面元素提取重要信息,发现请求返回的数据如下:
莘器规奉网医卫生录红霉素眼膏到院次设六柒莘器规奉网医卫生录红霉素眼膏到院到院机局聊城利筑药国集团元重六有dCc2TW6qweCe/4qu5++U7OyM68vQ6MvbrM6VgvOf/umNtruC8dGU9dCP4O2O+uyjyMgHX3fe5rSBz8qy0POnlfuL/f+wrNHU6+7Hx9vU0+aK4d6C/cDVsOeg39+52cqq48vSztOj9M+o5vq3q9uGjryi+oa64cCz+Z/Q1fd+SnNXBAFDVw==
仔细观察发现返回的内容和我们在浏览器中看到的不同,我们在浏览器中看到的内容为:
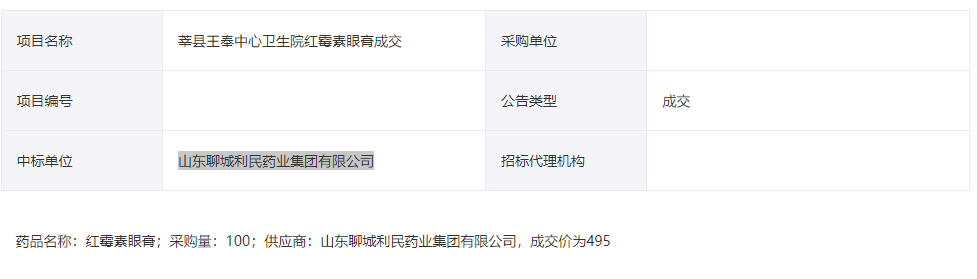
接着查看网页源代码,发现数据确实是被处理过的。先看下面的那串字符串,对应“药品名称:……”,猜想是js加密,上一篇文章中讲了,寻找加密的js函数有两个方法,一是在页面元素中加断点调试,二是查看请求调用。第二种方式在本网站行不通,因为它没有调用栈。
2、寻找js加密函数
我们在“药品名称:……”这部分内容之前加个断点,然后刷新网页,浏览器页面如下所示:
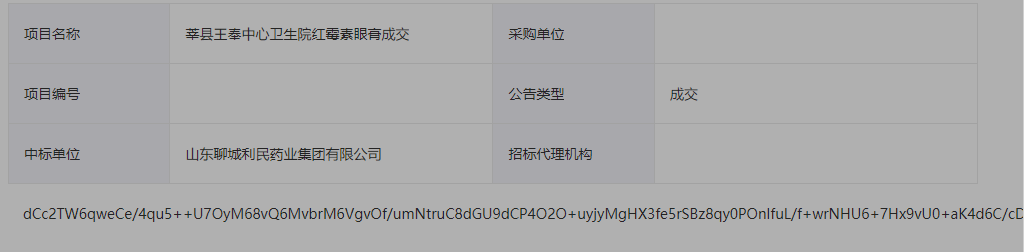
接下来我们要找出控制内容从加密的字符串转变成正常的文字的相关方法,观察Sources区域:
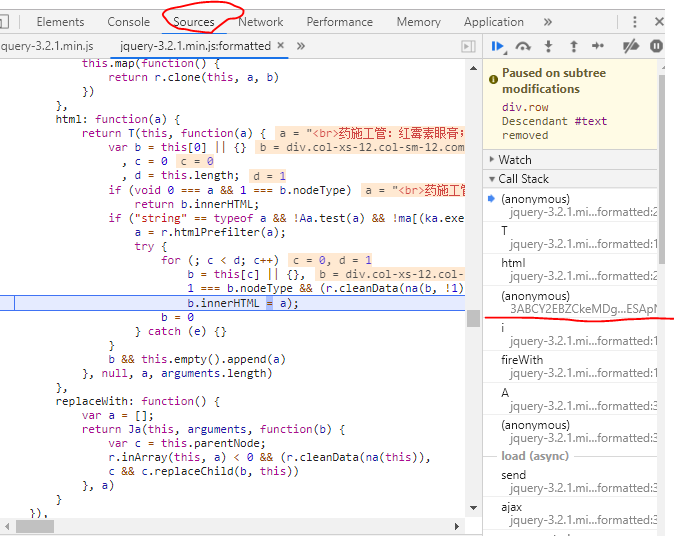
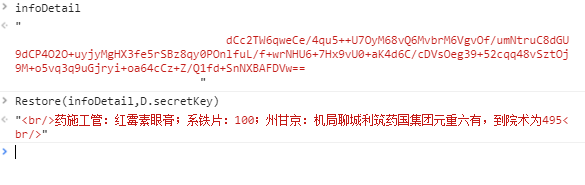
我们发现a已经为正常的文字,那证明我们还需要向前面的调用进行追溯,所以我们看右边的callback,选择图中画横线的调用,点进去内容如下:
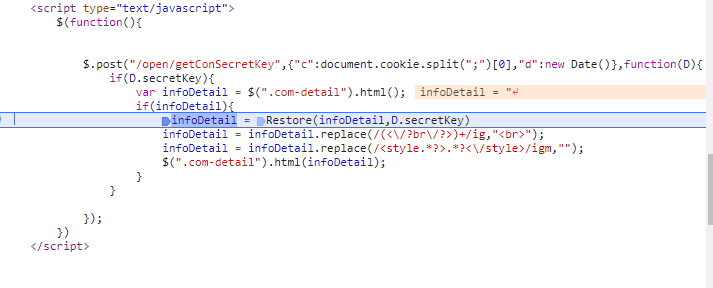
将鼠标放到infoDetail上,发现其值就是我们在重点关注的文字,我们猜想它是通过Restore函数从字符串转变而来,于是我们在该段代码前加断点,然后刷新网页,发现这个时候infoDetail值的确为那串加密字符串,接下来我们可以在console中验证猜想:
3、将加密函数修改为可执行的方法,并布置为js服务
所以现在我们只要抠出Restore函数就可以了,它还调用了其他函数,所以一并抠出来:
1 |
|
上面代码中涉及window.atob,上网查询发现其用于解码使用base-64编码的字符串,可以通过导入atob模块来直接使用,即将上述代码中的str = stringToBytes(window.atob(str))替换为str = stringToBytes(atob(str))就行了,不过要先导入atob模块const atob = require('atob'),如果没有该模块,还要先安装npm install atob,最后我们将其布置为js服务,供我们程序调用(尝试过直接使用python来执行js函数,但是总是报错,可能是调用方法不对)。
接着,我们发现Restore函数有两个参数,一个是需要解密的字符串,另一个是secret_key,其实仔细观察我们在调用Restore函数的地方已经看到,secret_key是通过一个异步请求返回的值,其请求的url='https://api.jianyu360.com/open/getConSecretKey',请求方式为POST,body为{"c":document.cookie.split(";")[0],"d":new Date()},其实一个就是cookie的一部分,另一个是时间,我们通过测试发现,不加body也可以成功请求,但是必须在请求头中写Referer。
下面是完整的请求代码:
1 | import requests |
4、字体解密
现在所有能获取的内容全部都是文字了,但是发现看起来非常怪异,而且我们再也找不到相关的加密方法了,不过再经过观察css发现了非常重要的内容:
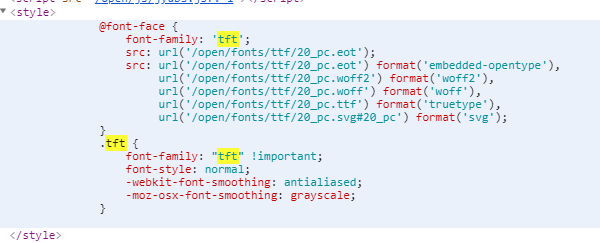
由此推测出这是使用了字体加密,于是我们百度爬虫字体加密找到了python的fontTools
FontTools
- 安装:pip install fontTools
- 加载字体文件:font = TTFont(‘maoyan.woff’)
- 转为xml文件:font.saveXML(‘maoyan.xml’)
- 各节点名称:font.keys()
- 按序获取GlyphOrder节点name值:
font.getGlyphOrder() 或 font[‘cmap’].tables[0].ttFont.getGlyphOrder() - 获取cmap节点code与name值映射:font.getBestCmap()
- 获取字体坐标信息:font[‘glyf’][i].coordinates
- 获取坐标的0或1:font[‘glyf’][i].flags 注: 0表示弧形区域 1表示矩形
破解字体加密的主要步骤如下:
- 获取被加密的 html 文档。
- 获取被加密的 html 文档对应的字体文件,有时它被以 base64 编码写在 html 文档中。
- 解析网页字体文件,获得加密编码到字体图片的映射。
- 通过种种途径,在本地准备一个标准字体文件,即标准编码到字体图片的映射。
- 设计匹配算法,生成网页字体文件的字体图片到标准字体文件的字体图片的映射。
- 最终,链接三个映射,获得网页加密编码到标准编码的映射,即解密字典。
- 利用解密字典,将被加密的 html 文档中的所有加密编码,替换为标准编码。
理论知识准备完毕,接下来看具体怎么破解剑鱼标讯的字体加密,上面有说要先找到被加密的html文档对应的字体文件,于是我们查看请求中的font类型:
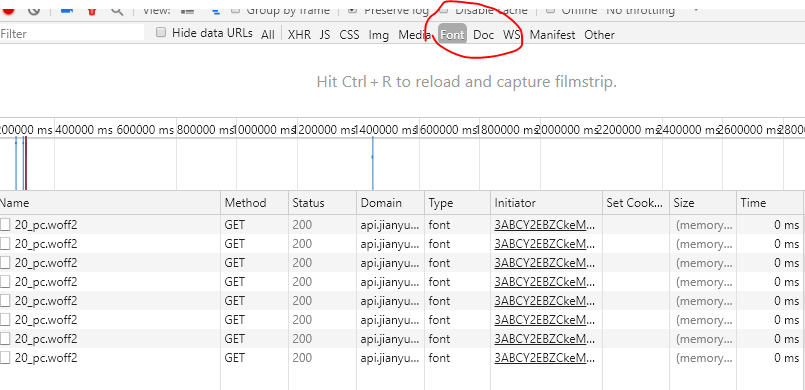
还真的有!可以把该文件保存到本地或者每次需要时请求都可以:
1 | from fontTools.ttLib import TTFont |
上面TTFont(文件名)orTTFont(BytesIO(二进制流))都可以读取字体数据,中间可能会报no modules named brotli,我们只要安装一下就可以了pip install brotli,如果不确定该模块存不存在,可以先查找看下pip search brotli。
上面origin_map的形式为:
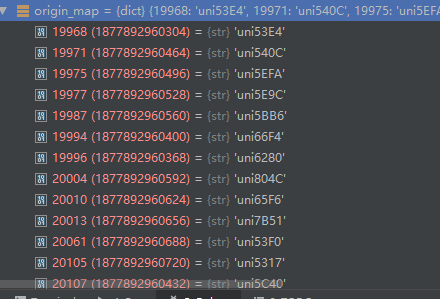
我们拿出任意一个value值:
'uni53E4'.replace('uni', r'\u').encode().decode('unicode_escape'),得到“古”字。
所以可以这样来构建我们的字体字典:
1 | for key, value in origin_map.items(): |
接着上面的content(药施工管:红霉素眼膏;系铁片:100;州甘京:机局聊城利筑药国集团元重六有,到院术为495),我们可以这样来解密字体(我也不会啊,在网上查来的)
1 | text = '' |
解决!但是大佬指点,上面的代码可能用一个函数一句搞定print(content.translate(font_map)),只能膜拜了。
其实一开始我们可能就会发现字体很奇怪,也可以先对其他部分内容进行字体解密;之后再进行js解密。
破解的过程可能并不是一帆风顺,其中需要一定的经验和技巧,才能快速破解;并且要能会具体问题具体分析,并不一定要按照特定步骤按部就班。