Python深度学习
注:本文章摘自《Python深度学习》书籍
第一部分:深度学习基础
第一章:什么是深度学习
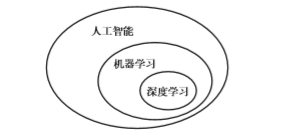
人工智能、机器学习与深度学习的关系
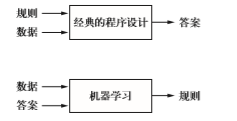
符号主义人工智能(symbolic AI):
人们输入的是规则(即程序)和需要根据这些规则进行处理的数据,系统输出的是答案。
机器学习:
人们输入的是数据和从这些数据中预期得到的答案,系统输出的是 规则。这些规则随后可应用于新的数据,并使计算机自主生成答案。
机器学习的三要素
- 输入数据点
- 预期输出的示例
- 衡量算法结果好坏的方法
机器学习技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
深度学习:它是从数据中学习表示的一种新方法,强调从连续的层中进行学习,这些层对应于越来越有意义的表示。“深度”指的并不是利用这种方法所获取的更深层次的理解,而是指一系列连续的表示层。
深度是指数据模型中包含的层数,这些分层表示几乎总是通过叫做神经网络(neural network)的模型学习得到。
注:这里所谓的神经网络与人类大脑神经等无关
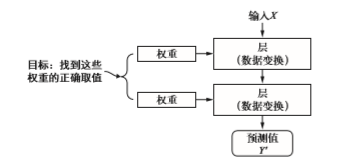
深度学习的工作原理
学习的意思是为神经网络的所有层找到一组权重值,使得该网络能够将每个示例输入与其目标正确地一一对应。
想要控制神经网络的输出,就需要能够衡量该输出与预期值之间的距离。这是神经网络损失函数(loss function)的任务,该函数也叫目标函数(objective function)。损失函数的输入是网络预测值与真实目标值(即你希望网络输出的结果),然后计算一个距离值,衡量该网络在这个示例上的效果好坏。
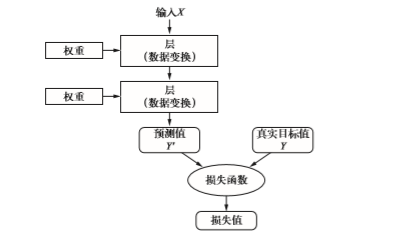
深度学习的基本技巧是利用这个距离值作为反馈信号来对权重值进行微调,以降低当前示 例对应的损失值。这种调节由优化器(optimizer)来完成,它实现了所谓的反向传播(backpropagation)算法,这是深度学习的核心算法。
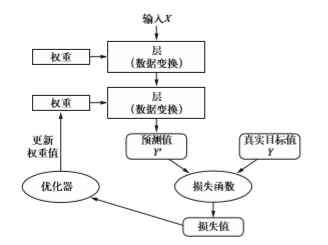
深度学习的特点
- 特征工程自动化:对于机器学习,人们必须竭尽全力让初始输入数据更适合处理,所以必须手动为数据设计好的表示层,这叫做特征工程。而深度学习完全将这个步骤自动化,利用深度学习,可以一次性学习所有特征,无须手动设计,这极大地简化了机器学习工作流程。
- 贪婪学习:深度学习模型可以在同一时间学习所有表示层,而不是依次连续学习。
机器学习简史
概率建模
- 朴素贝叶斯算法:基于应用贝叶斯定理的机器学习分类器;
- logistic回归:分类算法
早期神经网络
反向传播算法——利用梯度下降优化来训练一系列参数化运算链的方法;贝尔实验室将神经网络的早期思想与反向传播算法相结合,应用于手写数字分类,得到名为LeNet网络。
核方法 kernel method
核方法是一组分类算法,其中最有名的是支持向量机(SVM,support vector machine),SVM的目标是通过在属于两个不同类别的两组数据点之间找到良好的决策边界(decision boundary)来解决分类问题。
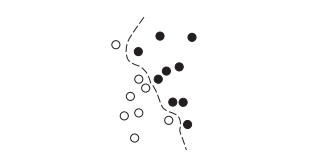
SVM很难扩展到大型数据集,并且在图像分类等感知问题上的效果也不好。
决策树、随机森林与梯度提升机
决策树是类似于流程图的结构,可以对输入数据点进行分类或根据给定输入来预测输出值。
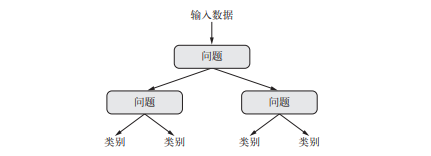
随机森林算法即构建许多决策树,然后将他们的输出集成到一起,对任何浅层机器学习任务来说,它几乎总是第二好的算法。
梯度提升机(gradient boosting machine)也是将弱预测模型(通常是决策树)集成的机器学习技术。它使用了梯度提升方法,通过迭代地训练新模型来专门解决 之前模型的弱点,从而改进任何机器学习模型的效果。将梯度提升技术应用于决策树时,得到的模型与随机森林具有相似的性质,但在绝大多数情况下效果都比随机森林要好。
回到神经网络
自2012年以来,深度卷积神经网络convnet已成为所有计算机视觉任务的首选算法,与此同时,在自然语言处理领域也得到应用,它已经在大量应用中完全取代了SVM与决策树。
机器学习现状
- 梯度提升机:用于处理结构化数据的问题,用于浅层学习问题,使用
XGBoost库; - 深度学习:用于图像分类等感知问题,使用
Keras库。
三种技术力量在推动着机器学习(深度学习)的进步:
- 硬件
- 数据集和基准
- 算法上的改进
第二章 神经网络的数学基础
数据点叫做样本(sample),某个样本对应的类叫做标签(label)
层(layer):是神经网络的核心组件,它是一种数据处理模块,你可以将它看成数据过滤器,进去一些数据,出来的数据变得更加有用。
张量(tensor):它是一个数据容器,它包含的数据几乎总是数值数据,当前所有机器学习系统都使用张量作为基本数据结构。
张量的维度(dimension)通常叫做轴(axis)
张量的分类
标量:仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、
0D张量)。向量:数字组成的数组叫作向量(vector)或一维张量(
1D张量),一维张量只有一个轴。这个向量有5 个元素,所以被称为
5D向量。不要把5D向量和5D张量弄混!5D向量只 有一个轴,沿着轴有5 个维度,而5D张量有5 个轴(沿着每个轴可能有任意个维度)。矩阵:向量组成的数组叫作矩阵(matrix)或二维张量(
2D张量)。矩阵有 2 个轴(通常叫作行和列)3D张量与更高维张量 :将多个矩阵组合成一个新的数组,可以得到一个3D张量,你可以将其直观地理解为数字 组成的立方体。将多个
3D张量组合成一个数组,可以创建一个4D张量,以此类推。深度学习处理的一般 是0D到4D的张量,但处理视频数据时可能会遇到5D张量。
注:可以利用ndim属性来查看一个Numpy张量的轴的个数
张量的关键属性
轴的个数(阶):例如,
3D张量有3 个轴,矩阵有2 个轴。这在Numpy等 Python 库中 也叫张量的ndim。形状:这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。
例如:
1
2
3x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])形状为:(3, 5)
1
2
3
4
5
6
7
8
9x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])形状为:(3, 3, 5)
数据类型:(在Python 库中通常叫作
dtype),这是张量中所包含数据的类型,例如,张量的类型可以是float32、uint8、float64等。
数据批量的概念
通常来说,深度学习中所有数据张量的第一个轴(0轴,因为索引从0开始)都是样本轴(samples axis,有时也叫样本维度)。
此外,深度学习模型不会同时处理整个数据集,而是将数据拆分成小批量。具体来看,下面是MNIST数据集的一个批量,批量大小为128。
1 | batch = train_images[:128] |
对于这种批量张量,第一个轴(0轴)叫做批量轴(batch axis)或批量维度(batch dimension)。
现实世界中的数据张量
- 向量数据:
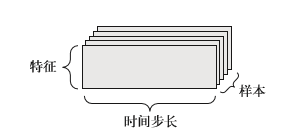
2D张量,形状为(samples,features) - 时间序列数据或序列数据:
3D张量,形状为(samples,timesteps,features) - 图像:
4D张量,形状为(samples,height,width,channels)或(samples,channels,height,width) - 视频:
5D张量,形状为(samples,frames,height,width,channels)或(samples,frames,channels,height,width)
注:这里数据张量比实际多一个轴,如向量本身是1D,图像是3D,视频是4D,但是这里面多了一个样本轴,所以普遍多1D
例如:
向量数据:人口统计数据集,其中包括每个人的年龄、邮编和收入。每个人可以表示为包含3个值的向量,而整个数据集包含100000个人,因此可以存储在形状为(100000, 3)的2D张量中。
时间序列数据或序列数据:股票价格数据集,每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟 的最低价格保存下来。因此每分钟被编码为一个3D 向量(注意是向量),整个交易日被编码为一个形状为 (390, 3) 的 2D 张量(一个交易日有 390 分钟),而 250 天的数据则可以保存在一 个形状为 (250, 390, 3) 的 3D 张量中。这里每个样本是一天的股票数据。
图像数据:图像通常具有三个维度:高度、宽度和颜色深度。虽然灰度图像(比如MNIST 数字图像) 只有一个颜色通道,因此可以保存在2D 张量中,但按照惯例,图像张量始终都是3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为256×256,那么128 张灰度图像组成的批 量可以保存在一个形状为 (128, 256, 256, 1) 的张量中,而128 张彩色图像组成的批量则可以保存在一个形状为(128, 256, 256, 3)的张量中。
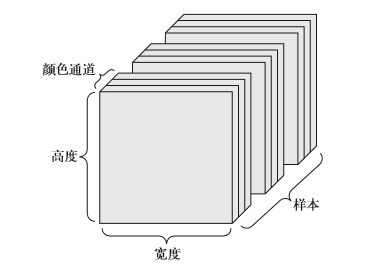
视频数据:视频可以看作一系列帧, 每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为 (height, width, color_ depth) 的 3D 张量中,因此一系列帧可以保存在一个形状为(frames, height, width, color_depth) 的4D张量中,而不同视频组成的批量则可以保存在一个5D张量中,其形状为 (samples, frames, height, width, color_depth)。
这里省略的比较复杂的张量运算,包括逐元素运算、广播、点积和变形。
第三章 神经网络入门
训练神经网络主要围绕以下方面
- 层,多个层组合成网络(或模型);
- 输入数据和相应的目标;
- 损失函数,即用于学习的反馈信号;
- 优化器,决定学习过程如何进行。
前面深度学习原理部分的图展示了这四者的关系
层:深度学习的基础组件
层是一个数据处理模块,将一个 或多个输入张量转换为一个或多个输出张量,不同的张量格式与不同的数据处理类型需要用到不同的层。
密集连接层[
densely connected layer]:也叫全连接层(fully connected layer)或密集层(dense layer),对应于Keras的Dense类。通常适用于保存在形状为(samples, features)的2D张量中的向量数据。循环层 [
recurrent layer]:对应于Keras的LSTM层,通常用来处理保存在形状为(samples, timestamp, features)的3D张量中的序列数据。- 二维卷积层:对应于
Keras的Conv2D,通常用来处理保存在4D张量中的图像数据。
模型:层构成的网络
深度学习模型是层构成的有向无环图。
损失函数与优化器
- 损失函数(目标函数):在训练过程中需要将其最小化,它能够衡量当前任务是否已 成功完成。
- 优化器:决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降(
SGD) 的某个变体。
对于分类、回归、序列预测等常见问题,你可以遵循一些简单的指导原则来选 择正确的损失函数。
- 对于二分类问题,你可以使用二元交叉熵(
binary crossentropy)损失函数; - 对于多分类问题,可以用分类交叉熵(
categorical crossentropy)损失函数; - 对于回归问题,可以用均方误差(
mean-squared error)损失函数; - 对于序列学习问题,可以用联结主义时序分类(
CTC,connectionist temporal classification)损失函数。
使用Keras开发
工作流程
- 定义训练数据:输入张量和目标张量。
- 定义层组成的网络(或模型),将输入映射到目标。
- 配置学习过程:选择损失函数、优化器和需要监控的指标。
- 调用模型的 fit 方法在训练数据上进行迭代。
定义模型有两种方法:
- 是使用 Sequential 类(仅用于层的线性堆叠,这是目前最常见的网络架构);
- 是函数式
API(functional API,用于层组成的有向无环图,让你可以构建任意形式的架构)