本文章参考《python深度学习》
电影评论分类:二分类问题
IMDB数据集
它包含来自互联网电影数据库(IMDB)的50 000 条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试 集都包含 50% 的正面评论和 50% 的负面评论。
IMDB 数据集内置于Keras库。它已经过预处理:评论(单词序列) 已经被转换为整数序列,其中每个整数代表字典中的某个单词。
1 | from keras.datasets import imdb |
参数num_words=10000的意思是仅保留训练数据中前10 000 个最常出现的单词。低频单词将被舍弃,这样得到的向量数据不会太大,便于处理。
train_data 和 test_data 这两个变量都是评论组成的列表,每条评论又是单词索引组成 的列表(表示一系列单词)。train_labels 和 test_labels 都是0 和1组成的列表,其中0 代表负面(negative), 1 代表正面(positive)。
1 | train_data[0] |
举例子理解具体某条评论:
某条评论为:[15, 16, 89, 77],其中15代表字典中的I、16代表love、89代表this、77代表movie,那么这条评论为I love this moive。
下面这段代码就可以将某条评论迅速解码为英文单词:
1 | from keras.datasets import imdb |
上述评论的数字和英文单词对应关系纯粹为了帮助理解,非真实情况
注意,实际将评论解码会将索引减去3,如reverse_word_index.get(i-3, '?'), 因为0、1、2 是为“padding”(填充)、“ start of sequence”(序列开始)、“unknown”(未知词)分别保留的索引
准备数据
不能将整数序列直接输入神经网络,需要将列表转换为张量。
具体方法:对列表进行 one-hot 编码,将其转换为 0 和 1 组成的向量。
举个例子,序列 [3, 5] 将会 被转换为10 000 维向量,只有索引为3 和 5 的元素是1,其余元素都是0。然后网络第 一层可以用 Dense 层,它能够处理浮点数向量数据。
我们可以手动实现这一方法:
1 | def vectorize_sequences(sequences, dimension=10000): |
实际上,keras.utils.to_categorical()方法具有类似vectorize_sequences的功能,但是其只能接受一个向量作为参数,无法接受二维数组(2D张量)。
当向vectorize_sequences传入2D张量时:
1 | a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
完整地数据处理过程
1 | import keras |
构建网络
输入数据是向量,而标签是标量(1 和 0),这是最简单的情况,有一类网络在这种问题上表现很好,就是带有relu 激活的全连接层(Dense)的简单堆叠,比如 Dense(16, activation='relu')。
对于这种 Dense 层的堆叠,你需要确定以下两个关键架构:
- 网络有多少层;
- 每层有多少个隐藏单元。
这里采用两个中间层,每层都有 16 个隐藏单元; 第三层输出一个标量,预测当前评论的情感。
中间层使用 relu作为激活函数,最后一层使用 sigmoid 激活以输出一个 0~1 范围内的概率值(表示样本的目标值等于1 的可能性,即评论为正面的可能性)。
1 | from keras import models |
最后,你需要选择损失函数和优化器。由于你面对的是一个二分类问题,网络输出是一 个概率值(网络最后一层使用sigmoid 激活函数,仅包含一个单元),那么最好使用 binary_ crossentropy(二元交叉熵)损失。
下面的步骤是用rmsprop优化器和 binary_crossentropy 损失函数来配置模型。注意, 我们还在训练过程中监控精度。
1 | model.compile(optimizer='rmsprop', |
有时你可能希望配置自定义优化器的参数,或者传入自定义的损失函数或指标函数。前者可通过向 optimizer 参数传入一个优化器类实例来实现,后者可通过向loss和 metrics参数传入函数对象来实现。
1 | from keras import losses from keras import metrics |
验证方法
为了在训练过程中监控模型在前所未见的数据上的精度,你需要将原始训练数据留出 10000 个样本作为验证集。
1 | x_val = x_train[:10000] |
调用 model.fit() 返回了一个 History 对象。这个对象有一个成员 history,它是一个字典,包含训练过程中的所有数据。
1 | history_dict = history.history |
注意:当设置metrics=[‘acc‘]时,
history_dict的key为dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
我们可以利用这四个指标的数据绘图,从而更直观的看到训练的过程。
1 | import matplotlib.pylab as plt |
生成的图像如下:
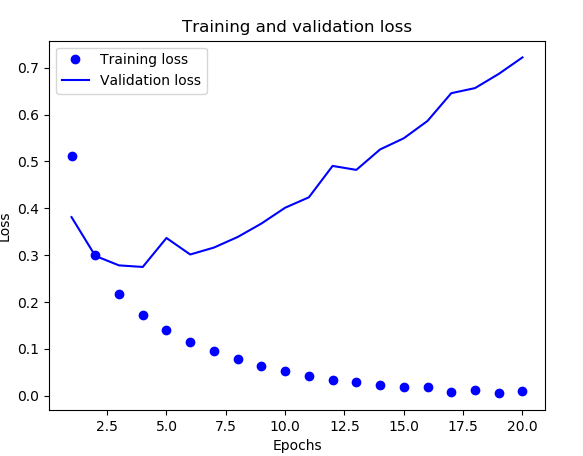
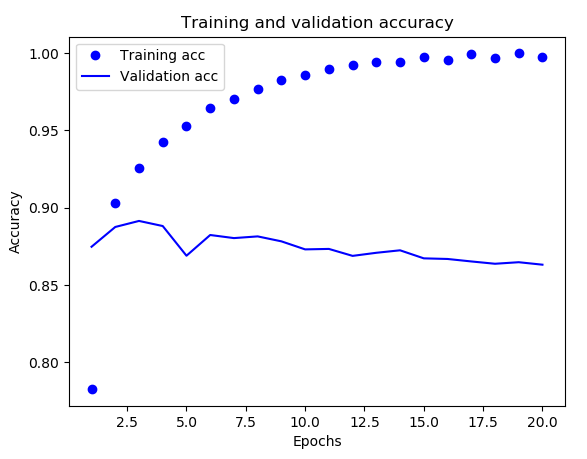
如你所见,训练损失每轮都在降低,训练精度每轮都在提升。这就是梯度下降优化的预期 结果——你想要最小化的量随着每次迭代越来越小。但验证损失和验证精度并非如此:它们似 乎在第四轮达到最佳值。这就是我们之前警告过的一种情况:模型在训练数据上的表现越来越好, 但在前所未见的数据上不一定表现得越来越好。准确地说,你看到的是过拟合(overfit):在第二轮之后,你对训练数据过度优化,最终学到的表示仅针对于训练数据,无法泛化到训练集之 外的数据。 在这种情况下,为了防止过拟合,你可以在3 轮之后停止训练,这样就可以获取比训练20轮还高的精度。
测试与预测
当训练好网络之后,我们可以先使用测试集来测试准确度
1 | results = model.evaluate(x_test, y_test) |
第一个是测试集的损失值,第二个是测试集的准确率。
当测试的准确率达到我们的需求时,我们可以用这一网络来预测新数据
1 | results = model.predict(x_test) |
前面说过结果输出一个 0~1 范围内的概率值(表示样本的目标值等于1 的可能性,即评论为正面的可能性)。网络对某些样本的结果非常确信(大于等于 0.99,或小于等于 0.01),但对其他结果却不那么确信(0.6 或 0.4)。
改进与总结
改进(应该说是试验):
前面使用了两个隐藏层。你可以尝试使用一个或三个隐藏层,然后观察对验证精度和测 试精度的影响
尝试使用更多或更少的隐藏单元,比如 32 个、64 个等
- 尝试使用
mse损失函数代替binary_crossentropy - 尝试使用
tanh激活(这种激活在神经网络早期非常流行)代替relu
总结:
- 通常需要对原始数据进行大量预处理,以便将其转换为张量输入到神经网络中。单词序 列可以编码为二进制向量,但也有其他编码方式。
带有
relu激活的 Dense 层堆叠,可以解决很多种问题(包括情感分类),你可能会经常用到这种模型。对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用 sigmoid 激活的 Dense 层,网络输出应该是 0~1 范围内的标量,表示概率值。
- 对于二分类问题的 sigmoid 标量输出,你应该使用
binary_crossentropy损失函数。 - 无论你的问题是什么,
rmsprop优化器通常都是足够好的选择。这一点你无须担心。 - 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据 上得到越来越差的结果。一定要一直监控模型在训练集之外的数据上的性能。