Discover
Filtering with the time picker
可以利用time picker(时间选择工具)实现按时间筛选数据;
也可以通过直方图来过滤,直接单击某一个直方图或者单击并拖动以查看特定的时间跨度;
Searching Your Data
在Kibana上搜索数据时,可以使用Kibana Query Language(KQL)(也就是Kibana的标准查询语言)或者直接使用Lucene query syntax(即Lucene 查询语法,KQL本身也是基于Lucene的)。
每次查询的结果获取的满足条件的数据条数会在左上角显示,会默认显示500条Documents(总条数大于500时),数据会在鼠标不断下滑的过程中自动加载,并且默认是按照时间排序的,时间最新的在最上面。
点一下Time旁边的小三角号就可以切换排序方式,每条数据都可以点开以JSON格式查看
Kibana Query Language语法
response:200will match documents where the response field matches the value 200,通俗地讲就是要求我们的document中有一个字段名为response,其值为“200”。
message:"Quick brown fox"will search for the phrase “quick brown fox” in the message field,其道理跟上面是一样的,这里重点在加不加引号的区别。如果加了引号就是精确匹配,若不加引号,则会匹配”quick brown fox”,也会匹配”quick fox brown”,也就是会忽略他们的顺序。
多个查询条件必须以布尔运算符分隔,Lucene会默认使用or分隔多个查询条件。
如response:200 extension:php 会被转换为 response:200 or extension:php
布尔运算符不区分大小写,and比or优先级更高
可以使用括号简单地实现一个字段对应多值情况的查询,如response:(200 or 404),tags:(success and info and security)
可以在条件前面加上not实现反转,如not response:200,response:200 and not (extension:php or extension:css)
范围查询与Lucene相似,但是语法有一点区别
在这里使用bytes > 1000代替bytes :> 1000,>, >=, <, <=都是有效的范围运算符。
通配符*的使用
response:* 匹配所有response字段存在的文档(无论其值为多少)
machine.os:win*匹配machine.os字段的值以win开头的情况,例如可以匹配window7和window10
使用通配符也可以实现同时查询多个字段的情况,假设我们有machine.os和machine.os.keyword字段,我们想检索这两个字段中值都为windows 10的数据,我们可以这样做:machine.os*:windows 10。
最后,还可以采用不指定字段,直接使用值的查询,如输入200进行查询,将会查询到任何字段值包含200的所有文档。
Lucene Query syntax
输入safari将会查询到任何字段值包含safari的所有文档;
输入status:200将会查询到任何status字段值为200的文档;
搜索范围值可以使用中括号语法,[START_VALUE TO END_VALUE],例如,status:[400 TO 499]
还可以使用AND、OR、NOT等布尔运算符实现复杂条件查询。
Saving and Opening Searches
可以点击Save按钮保存搜索,点击Open打开搜索。
Filtering by field
从字段列表添加过滤器
在选择索引的下面有
Selected fields和Available fields,Available fields下面有一系列的字段,点击任一字段可以看到该字段值出现频率最高的五个,并且显示出现的百分比,在百分比上面有一个”+”和一个”-“,点击”+”表示添加一个过滤器,要求该字段的值必须为这个值,点击”-“则正相反,要求该字段的值不能为这个值。从文档表添加过滤器
在时间轴下方最显眼的区域是我们推到es的数据,展开某条数据,每个字段的前面也有”+”和”-“的符号,其作用与上面一样;不过有一点需要注意的是最后面有个”*”标记,点击的作用就是选择含有这个字段的所有文档。
直接通过
+Add filter添加过滤器点击之后,选择你要筛选的字段,然后选择操作符(如
is,is not, is one of等),再添加值就可以了。或者你可以选择Edit as Query DSL,这时就会使用Elasticsearch基于JSON提供的查询语言来定以查询,感兴趣的话可以了解学习。
我们在Filters的位置可以看到已添加的过滤器,可以修改或者删除相应的过滤器。而且对于很多简单的过滤器其实在搜索框中输入相应的搜索条件也可以达到目的。
Visualize
这部分是利用已有数据做各种统计图,点击Create new visualization可以看到所有的图形类型。
因为我也是初学者,这里记录几种常见的作图方式。
Metrics
此类图适合将数据分类,且类别较多的情况。
我这里选择按照字段值统计数量,在
Metrics里面的Aggregation选择Count,在Buckets里面的Aggregation选择Filters,之后根据需求添加过滤器,还可以为每个过滤器添加标签名。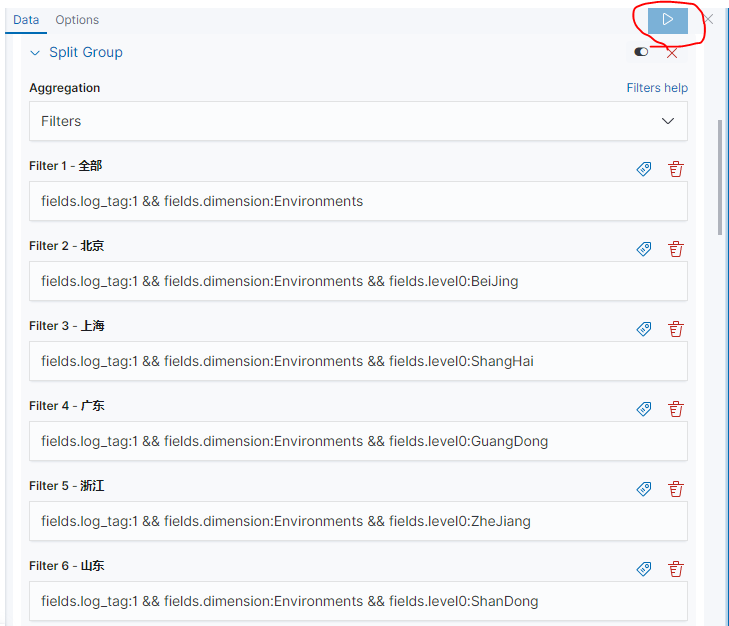
每次进行改动之后右上角的三角号将会变成可点击状态,点击运行将会对本次修改进行聚合,当然右上角的时间范围可以随时更改,生成的结果是基于你指定的时间范围内的数据。
还可以通过
Options设置颜色形状等图形外观。利用以上方式不仅可以做
Metrics图,也可以做其他图形。Vertical Bar
再作一个柱状图,比较特别的一点是先基于时间再进行分类。
同样地,在
Metrics里面的Aggregation选择Count,不过下面的Buckets里面先选择Date Histogram,Fields选择@timestamp,间隔的话根据你的需求选择,比如我这里想看每日的统计量,就选择Daily。之后我们可以选择
Add sub-buckets,然后选择Filters,其余操作同上。Pie
饼图,这里对某个整型的字段进行范围划分,如
count的取值范围可能是[0:1000],想统计[0:100]、[100:200]和[200:1000]的取值各占比多少,可以按照下述方式作图统计:选择
Split Slices,aggregation选择Range: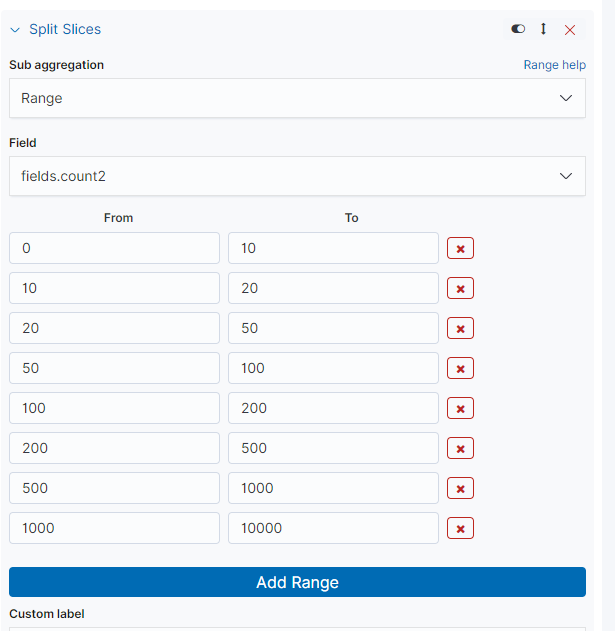
选择运行可以生成类似下面这样的图:
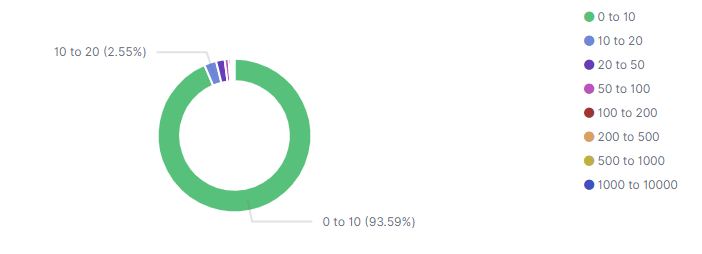
Options里有一些设置可以修改图形的显示方式,如show labels可以直接在图中帮我们直接展示比例(否则我们需要把鼠标放上去才看得到,但是实践证明帮我们直接标出的也是部分”块”)Split Chart的作用:使用
Split Chart可以生成多个饼图,如果我们这里面的数据有很多分类,想按类别统计count范围值的比例,那就可以使用Split Chart,使用时先选择Filters,然后填写过滤条件划分类别,划分几类就会生成几个饼图。注意:这里生成统计图的过程中,是先进行
Split Chart再进行Split Slices的
Aggregation中不仅有Count,还有Max、average、Unique Count等,其中Unique Count与数据库的distinct查询类似,去除重复值后的个数。
关于作图其实蛮复杂的,但是掌握以上方法基本可以做一些简单的统计需求了,当遇到具体的需求时边学习边实践把。
当我们向某一索引内发送了具有不同字段名的数据时,在Discover和Visualize可能找不到,这时候需要去Management中刷新该索引,Management中还可以看到每个字段的实际类型。
Dashboard
Dashboard其实就是将你做好的多个可视化图放在一起方便观察,新建一个Dashboard然后选择Add,选择相应的Visualize添加到该Dashboard即可,保存Dashboard的时候可以保存一个时间范围,下次打开的时候自动对该时间范围进行计算生成统计图。
在Dashboard中选择edit,可以随意拖动每个图,大小和位置都可以调整。