验证码识别之模型构建
Keras函数式API
之前学习使用的神经网络都是用Sequential模型实现的,网络只有一个输入和一个输出,而且网络是层的线性堆叠,这种网络配置非常常见,只使用Sequential模型类就能够涵盖许多主题和实际应用,但是有些情况下这种假设过于死板,有些网络需要多个独立的输入,有些网络则需要多个输出,而有些网络在层与层之间具有内部分支,这使得网络看起来像是层构成的图(graph),而不是层的线性堆叠。
也就是针对类似多输入模型、多输出模型和类图模型的使用案例,只用Keras中的Sequentail模型是无法实现的,但是还有另一种更加更加通用、更加灵活的使用keras的方式,就是函数式API。
有机会我会在之外的文章中记录这方面更详细的内容,这里先简单了解下就好。
构建模型
对于验证码识别来说,一般是多输出模型,所以我们需要使用函数式API来构建模型
1 | import keras |
这里定义了一个两层的神经网络,按照我测试的情况,像一般几千张的图片,两层的网络基本就可以了,层数多了反而准确度提升很慢,如果训练数据量很大,可以尝试增加网络层数;
之后全连接展开之后,定义了一个256维空间的隐藏层,这个大小实际上一般取决于输出空间的维度大小,这里是36(共36个验证码字符分类),隐藏层的维度大小至少要比输出空间的维度大(个人意见),否则太小可能无法学会区分这么多类别,这种维度较小的层可能成为信息瓶颈,永久地丢失信息。
因为每张验证码图片是4个字符,所以网络是4个输出,并且每个输出是36个分类中的一个,所以使用 softmax 激活,这样可以输出在 N 个输出类别上的概率分布。
model.summary()可以控制台打印我们的网络结构;
代码中的两个优化器,我都有测试,差别甚微,像这种验证码识别的项目其实属于比较简单地项目,无论哪种优化器应该都可以胜任,只是效果上有一些差距。
loss_weight:用来计算总的loss 的权重。默认为1,多个输出时,可以设置不同输出loss的权重来决定训练过程。因为这里是多输出,训练时每个输出都有一个损失值,此外还有一个总的损失值,这里设置每个损失值的权重相同,表示每个输出地位相同,为其降低损失值的优先级是相同的。
加载数据
上面已经完成了神经网络构建,只要调用model.fit就可以进行训练了,但是这里有一个重点需要注意,因为我们的网络是多输出(这里是4个输出),所以在将训练标签传入fit方法时要注意传入形式,标准的传入形式为
1 | model.fit(x_train, [y1, y2, y3, y4]) |
y1指的是每张验证码图片4个字符的第一个字符,其自身也是一个二维数组,第一维是训练集样本数量,与x_train的长度保持一致,第二维是一个长度为36的数组,只有其代表的字符所在的索引的值为1,其余为0(one-hot编码,前面文章有具体讲过数据处理过程,这里不详细讲了)。
我们先加载数据,然后看如何将数据传入到fit函数。
1 | x_train = np.load("x_train.npy") # shape: (3000, 40, 120, 1) |
y_train是3000个样本,然后每个样本是一个4x36的二维数组,我们要把这4个字符拆分开
1 | # 将y_train,y_val作为参数传入该函数 |
然后调用fit函数进行训练
1 | early_stopping = EarlyStopping(monitor='loss', patience=10) |
EarlyStopping是用于提前停止训练的callbacks,如当某些指标(损失值,准确率等)在经过一定次数的epoch后,没有得到improvement就提前停止训练,可以在一定程度上避免过拟合(当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差)。
这里使用的参数含义
- monitor:监控的数据接口,有
acc,val_acc,loss,val_loss等等。正常情况下如果有验证集,就用val_acc或者val_loss。 - patience:能够容忍多少个epoch内都没有improvement。这个设置其实是在抖动和真正的准确率下降之间做
tradeoff。如果patience设的大,那么最终得到的准确率要略低于模型可以达到的最高准确率。如果patience设的小,那么模型很可能在前期抖动,还在全图搜索的阶段就停止了,准确率一般很差。patience的大小和learning rate直接相关。在learning rate设定的情况下,前期先训练几次观察抖动的epoch number,比其稍大些设置patience。在learning rate变化的情况下,建议要略小于最大的抖动epoch number。
一般是在model.fit函数中调用callbacks,fit函数中有一个参数为callbacks。注意这里需要输入的是list类型的数据,所以通常情况只用EarlyStopping的话也要是[EarlyStopping()]。
利用History作图
因为这里是多输出,history的key和以前不太一样,我们可以打印其key值看看:
1 | history_dict = history.history |
可以看到,这里损失值分为总的损失值和各个输出的损失值,准确率没有总的准确率,只有各个输出的准确率,实际上我们在作图时,损失值的变化情况看总的就可以了(主要是看变化情况),准确率的话可以看任一输出的,因为我们在调整网络参数时,针对每个输出都是一样的,一般不会单独调整某一个验证码字符。
1 | loss_values = history_dict["loss"] # 训练数据的损失(总损失) |
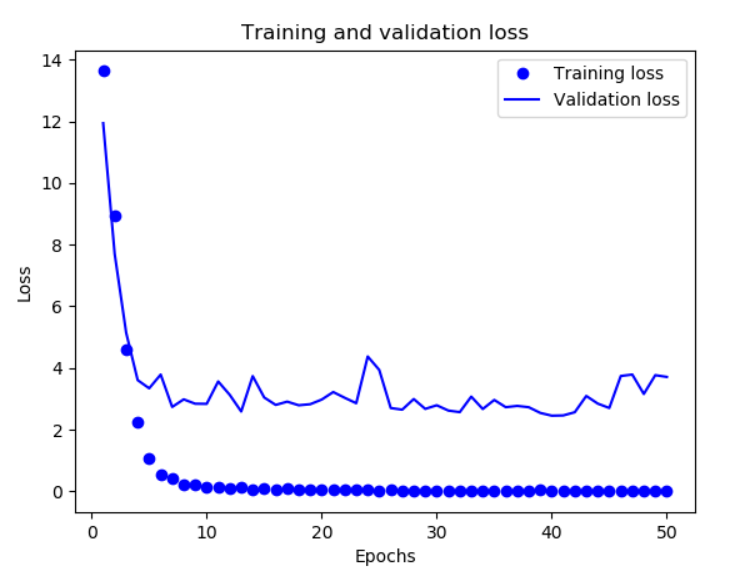
损失图像:
准确率图像:
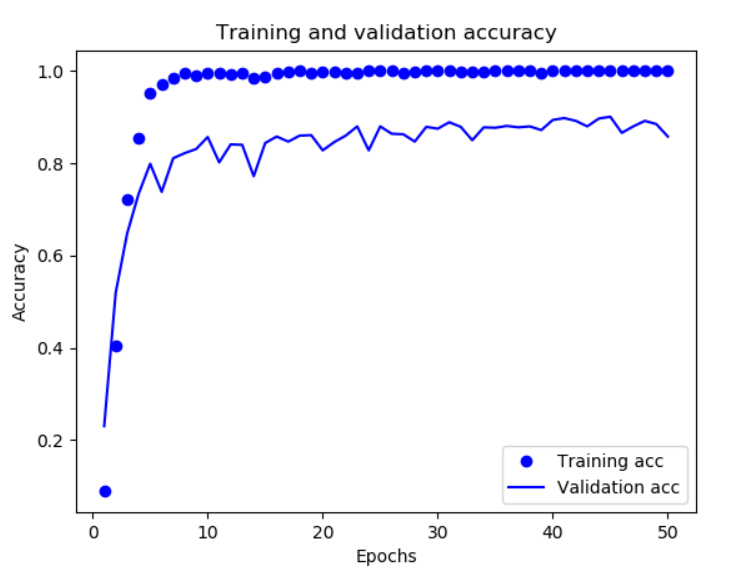
由图像可以粗略看到,基本在epochs达到40左右时,验证的损失和准确率基本已经达到了峰值,无法再通过增加轮数来提升(再增加过多的epochs,可能会出现准确率下降的情况),只能通过调整参数来提升,这也是一个避免过拟合的方式(类似人工earlystopping)。
记录一个坑
因为这里是多输出,所以fit函数参数的传入形式有特别的要求(上面我们已经介绍过了),但是我们将数据加载好后,实际上我们的训练/验证标签集的shape是(samples, 4, 36),一开始我想的比较简单,直接利用了numpy的reshape方法:
1 | y_train = np.load("y_train.npy") # shape: (3000, 4, 36) |
之后我无论怎么训练,训练集数据的正确率能提升至百分十八九十,而验证数据的准确率都极低(小于0.1),曾上网查过可能导致此类问题的原因,1、过拟合(一般原因:训练数据过少,网络过于复杂);2、没有将数据规格化(如图片,img/255);3、没有在分验证集之前打乱数据;4、数据和标签没有对上;5、网络结构有问题。
针对以上问题,我进行了一一排查,首先第2点我肯定是做了img/255规格化操作,其次网络结构如果有问题,那么我的训练集准备率也不可能提升至百分之八九十,所以首先排除了2和5;其实第3点“没有在分验证集之前打乱数据”,我确实犯了这个错误,并且后续做了调整,但是验证集的准确率依然没有得到提升,而且仔细思考,如果仅仅存在这个问题,验证集的准确率不会极低(小于0.1),只会和训练集相比低很多,如训练集0.9,验证集0.3;那么会不会是过拟合呢,这个不是特别好判断,理论上讲我的训练数据3000张,网络也只有两层,不应该出现过拟合的问题,于是我进一步进行了验证,先保存训练的模型,然后利用model.predict方法对训练集进行了准确率测试,发现准确率是0,这说明不是过拟合(过拟合训练的模型至少对训练集数据还是很准确的),而是训练模型时数据和标签没有对上。
最后经过进一步排查和思考,发现就是reshape操作导致数据和标签没有对上,我一开始是想当然的认为reshape操作可以达到我想要的变化,实际上reshape操作是先将整个数组(不管几维)按顺序展开成一维,然后再按照你设定的shape做变化,所以完全打乱了标签的顺序,因此在训练时,图片和标签就无法对应上,自然训练的模型是有问题的。
测试模型
当我们训练完一个模型后,一般会先测试下其在新的数据集上的准确率(如测试集),如果觉得其准确率可以满足需求,就可以将其应用到实际项目中。我们一般使用model.predict方法测试新的数据(单张验证码图片),具体方法如下:
1 | from keras.models import load_model |
可以看到,predict方法返回一个(4, 1, 36)的三维数组,其值是一个浮点数,表示概率;我们只要分别取出4个(1, 36)的二维数组中的值最大的下标值,然后找出该下标在alphanumeric中对应哪个字符即可。
这里需要用到np.argmax方法,可以较快速地找到相应的下标(当然也可以自己遍历数组,一层层找出),该方法的主要作用就是在张量中找出最大值所对应的索引。针对一维张量,没有任何疑问;针对二维张量,若不设置axis参数,默认就是将张量展开成一维张量,然后找出索引,axis=0表示按列搜索,axis=1表示按行搜索;对于三维张量,比较复杂,很难简单地表述清楚,这里仅简要说明(具体内容可以查询相关资料),设置axis=2表示在每个矩阵内部按行搜索,例如:
1 | print(np.argmax(y, axis=2)) |
上面是一个完整地拿训练好的模型测试新的数据的过程,我们可以写个循环,将所有的测试集图片都预测一遍,并且我们是知道每张验证码真实的答案的,所以可以将预测值和真实值进行比较,计算出准确率,如:
1 | path = 'D:/captcha/test/' |
除利用上面的方法之外,其实还有一个计算测试集准确率的方法,model.evaluate,该方法的调用方式与fit方法类似,也就是把数据先预处理后直接传入,直接帮我们计算出准确率。这里假设我们已经将测试集数据预处理过了:
1 | x_test = np.load("x_test.npy") |
如果是单输出的模型,model.evaluate的返回值,第一个是损失值,第二个是准确率;这里是多输出,所以可以将返回值的标签打印出来看一下,一共是9个返回值。而且这里得到的准确率一般比我们上面那种主动循环使用predict的方法看上去高,实际上这里有个隐藏的问题,这里只给出了每给字符的准确率,如0.8左右,而实际上我们predict后和真实值比较时,是4个字符同时比较的,那么准确率其实就是0.8x0.8x0.8x0.8,准确率约等于0.4,可能实际会比0.4稍高一些,但是明显比我们训练完的单个字符准确率低很多。
补充
以上基本是一个完整地搭建神经网络的过程,这里要补充的一点是利用model.fit_generator方法分批将数据加载入内存,以降低内存的占用,我们在使用fit方法时,训练数据是被完整地加载进内存的(其实训练过程是分批进行的),如果我们数据量很大,无法将数据一次性全部载入内存,这时,使用model.fit_generator就很方便。
1 | from keras.preprocessing.image import ImageDataGenerator |
之前有用到过ImageDataGenerator,当时是用来做数据增强的,这里不设置任何参数,就是没有去使用它的数据增强的功能,仅把它当做一个分批加载数据的方法。
model.fit_generator的第一个参数要求为一个生成器,生成器的输出应该为以下之一:
- 一个(inputs, targets)元组
- 一个(inputs, targets, sample_weights)元组
所以这里写了一个data_generator方法,用来分批生成数据,shuffle参数表示是否随机打乱顺序,fit方法也是有该参数的,默认为True。
其他参数:
- steps_per_epoch: 在声明一个 epoch 完成并开始下一个 epoch 之前从
generator产生的总步数(批次样本)。 它通常应该等于你的数据集的样本数量除以批量大小; - verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行;
- validation_data: 与第一个参数格式相同, 在每个 epoch 结束时评估损失和任何模型指标。该模型不会对此数据进行训练;
- validation_steps: 仅当
validation_data是一个生成器时才可用。 在停止前generator生成的总步数(样本批数)。