Python的PIL库
python imaging library是Python平台的图像处理标准库,我们在图像处理时不仅可以使用opencv,PIL也是可以的。
1 | from PIL import Image |
PIL还可以做图片剪裁,模糊等其他操作,并且PIL还可以打开opencv打不开的图片;
我曾遇到过使用opencv打开为None,而使用PIL可以打开的图片,但是使用PIL保存会提示:cannot write mode P as JPEG。
后查资料发现,PIL模块打开图片分为以下模式:
1 | 1 1位像素,黑和白,存成8位的像素 |
可以先将模式为P的图片先转化为RGB模式再保存。
1 | # 查看模式 |
因为PIL在处理像素方面比较方便,而opencv在模糊处理等方面更为便捷,所以经常可能需要两者联合使用,这里记录一种两种对象互相转换的方式(不用保存文件做中转)
PILImage直接读取二进制流1
2
3
4
5from PIL import Image
from io import BytesIO
# image_content是图片的二进制流
img = Image.open(BytesIO(image_content))OpenCV cv2直接读取二进制流1
2
3
4import cv2
import numpy as np
img = cv2.imdecode(np.frombuffer(image_content, np.uint8), cv2.IMREAD_COLOR)将Image对象转换为二进制流
1
2
3
4
5
6
7from PIL import Image
from io import BytesIO
out = BytesIO()
# img是Image对象
img.save(out, format="JPEG")
image_content = out.getvalue()将
cv2对象转换为二进制流1
2
3
4import cv2
res, out = cv2.imencode('.jpg', img)
image_content = out.tobytes()
掌握了上面四种技巧,就可以直接将任一种对象转换为二进制流,再以二进制流的形式读取即可。
验证码数据增强
通常在使用神经网络识别图像时,可以对图片进行翻转、平移、缩放、旋转等一系列操作以达到扩充数据集的目的,虽然对于验证码也可以使用类似的方式来扩充数据集,但是具体操作方式与普通图像有一定的区别,一般图像可能是识别一整个物体之类的,而验证码需要识别其中的数个字符(一般为4~6个),首先翻转平移之类的操作就不适合验证码,例如6翻转变成了9,这将会对模型训练起到反作用,平移也可能导致丢失字符;缩放和旋转是可以对验证码进行的操作,但是幅度不宜过大,不同的验证码图片即便字符大小有区别,应该也是很微小的,并且验证码字符常常有倾斜的可能,但是我们也不宜将其倾斜幅度过大,否则也有可能将一个倾斜的6变成一个倾斜的9。
数据增强一般用于训练数据不足的情况,当训练数据比较充足时,使用数据增强提升可能很小。
1 | from keras.preprocessing.image import ImageDataGenerator |
验证码图片去除干扰线
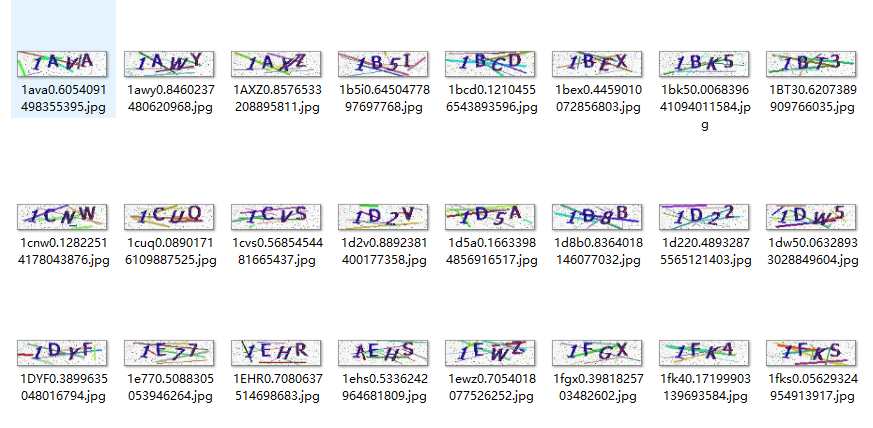
像上面这种形式的验证码,有比较明显的干扰线,并且大部分的干扰线有个明显的特征,颜色比验证码字符的颜色更鲜艳一些,所以可以考虑根据像素值分布来去除绝大部分的干扰线,windows自带的画图软件有个很好用的功能叫“颜色选取器”,使用方式如下:
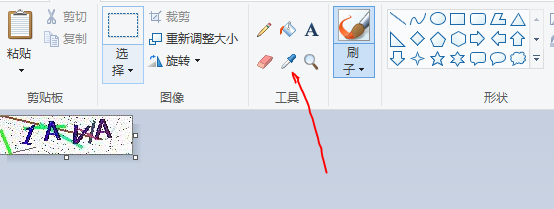
点击箭头指向的选项:
然后将鼠标放到你选取的图片的某个区域处,再点击颜色编辑,就可以看到这个颜色的RGB 值
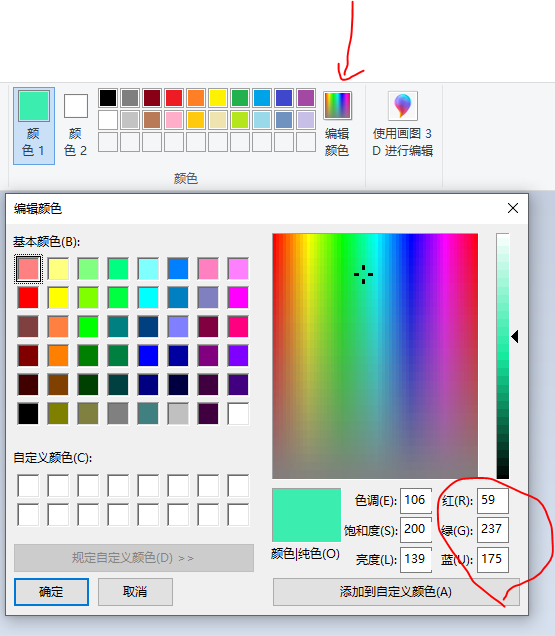
以下是我简单看了一些颜色的RGB值:
1 | # 干扰线的颜色 |
经过观察,很容易发现大多数情况下,干扰线的颜色R和G的值比较大,而验证码字符的颜色B的值较大(或者至少可以说验证码字符的R和G的值比较小),那只要找到这样一个分界值,就可以把干扰线去掉了。我这里找个一个粗略的边界值,展示一下代码实现方式:
1 | def process_img(img_list: list, img_path: str): |
麻瓜库
最近开源了一个白嫖的OCR库,可以用来识别单行的印刷体文字或者验证码字符,具体查看官方文档,我有使用它测试上面那种验证码字符的识别准确率,简单写下过程:
安装:pip install muggle-ocr
使用:
1 | import muggle_ocr |
直接使用这个麻瓜库的识别准确率在0.64左右,但是经过我上面的干扰线处理,准确率可以提升至0.85左右,然后我自己的模型却只能达到0.75……