深度学习目标检测破解滑动验证码
前言
本文主要参考以下文章:
这两篇文章都是同一位大佬所写,第一篇是利用华为云的一个深度学习平台做的(无需做任何编码工作),第二篇是通过PyTorch来做的,要自己代码实现。我这里主要参考第二篇文章,也直接在这里把作者使用到github项目列出来:
因为我在次之前接触过一点Keras,还没有接触过PyTorch,所以倾向于利用Keras来解决此问题,于是我就查找了keras-yolov3的相关资料,主要参考这两篇博客:
上面那篇博客过于具体过程讲的比较详细,一般按照教程来就可以,下面那篇是我遇到一些问题时找到的,关于这个项目的解析比较详细,可以帮助我们理解这个项目。
这篇博客主要使用这个github项目:
正文
labelImg
是github上的一个开源的图片标注工具,比较适用于目标检测任务的标注,具体使用方法github上写的比较清楚,主要就是安装一个PyQt5应该就可以用了,运行后有一个图像化界面,可以选择图片使用矩形框进行标注,类似这样:
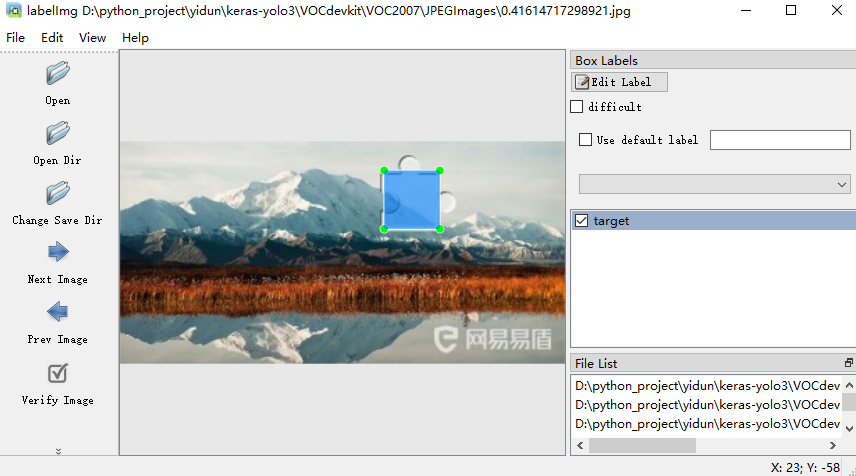
如果你需要标记的对象有很多种类,可以先在data/predefined_classes.txt中输入所有的分类,后面在图形界面中标注时直接选择相应的class;因为这里只是为了找出验证码中的小滑块,属于同一类,这里起名为target;先设置好xml文件保存的路径,然后打开验证码图片的文件夹,一张张标注即可。
每标记完成一张图片记得保存,保存后会生成xml文件,文件内容如下:
1 | <annotation> |
object里面的name是这张图片的分类名称(这里都是target),(xmin, ymin)和(xmax, ymax)是两组坐标,表示你标记的矩形的左上角和右下角。
此外还可以保存成yolo3要求的数据格式:
点击左上角的file->PascalVOC,之后会显示为YOLO;YOLO数据格式,会直接把每张图片标注的标签信息保存到一个txt文件中:
1 | 0 0.521000 0.235075 0.362000 0.450249 |
txt中信息说明:
- 每一行代表标注的一个目标
- 第一个数代表标注目标的标签,第一目标circle_red,对应数字就是0
- 后面的四个数代表标注框的中心坐标和标注框的相对宽和高(进行了归一化)
同时会生成一个Annotation/classes.txt实际类别文件classes.txt
关于yolov3
Pytorch-yolov3
Pytorch安装
因为本次实践过程一开始准备使用pytorch,在安装的时候遇到点问题,这里记录下。曾尝试使用pip install torch安装,但会报ModuleNotFoundError:no module named 'tools.nnwrap'的错误,这种情况可以打开Pytorch官网,选择你的电脑系统、安装方式、编程语言、显卡版本等会提示你使用相应的安装命令,如图:
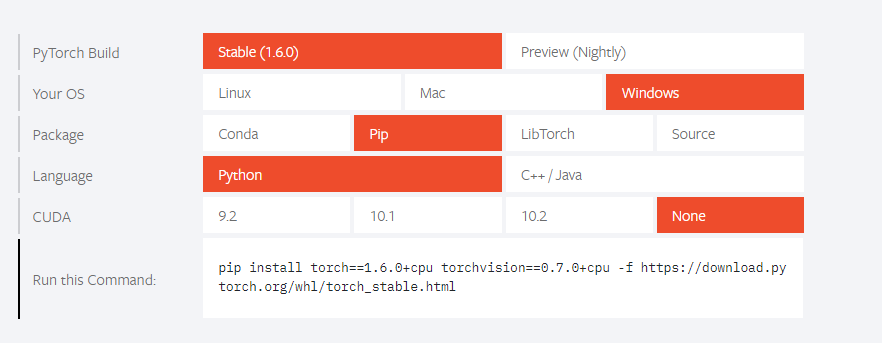
把下面的那串命令复制到终端执行就可以了,但是我使用这种方式也有个问题,下载超时;然后我直接打开了那个下载地址,选择了相应的版本直接在浏览器中进行下载,虽然下载速度较慢,但是勉强可以下载。
之后把cd到下载的.whl文件目录,然后执行pip install filename即可。比如我这里是:pip install torch-1.6.0+cpu-cp36-cp36m-win_amd64.whl
因为后来我专注于使用keras实现,所以pytorch的内容暂时没了。
Keras-yolo3
下载使用
keras-yolo3的GitHub地址我上面已经给出了,直接将项目拉到本地即可:
git clone https://github.com/qqwweee/keras-yolo3
之后需要下载权重文件yolov3.weights,下载完成后放到keras-yolo3文件夹下;
因为原生的yolov3使用darknet作为主干网络,需要将其配置文件转化为keras适用的h5格式文件:
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
执行完以上命令,会在model_data下生成yolo.h5的文件。
这里有一篇关于yolov3.cfg参数说明及调参经验的文章,是我在查询我的模型检测不到目标时可能存在的问题时看到的,当时我在纠结下面这个参数说明:
1 | # Testing(此处下面的两行,测试的时候开启即可) |
到底需不需要设置batch和subdivisions,这篇文章里讲到keras实际并没有使用这个配置。
这里再额外解释一下,这部操作的具体含义,查看yolo.py可以看到有这样一行配置"model_path": 'model_data/yolo.h5',其实这里生成的yolo.h5文件,本身就是一个训练好的模型,可以直接用来对你的图片进行检测,如果你要检测的目标恰好已经被这个模型包含了,那你就无需再训练了。
因为我这里训练的滑块缺口,模型肯定是不包含的,所以需要自己从头训练,然后按照很多博客中写的,要去修改yolov3.cfg中的三处地方(文章下面有写),这样就产生了以下几个问题:
1、修改完之后并没有告诉我们需要重新生成h5文件,那有啥用呢?参考原始的train.py代码,有一个加载预训练模型的操作,预训练模型名称为yolo_weights.h5,所以如果需要使用预训练模型,这里要重新生成h5文件:
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5
否则直接运行train.py会报错的;或者你可以选择不加载预训练模型,将create_model方法的参数load_pretrained修改为False即可(这时候就根本无需修改yolov3.cfg文件,我尝试过直接删除该文件都可以正常训练,因为根本没有去使用该文件)
2、博客中要求我们使用文章中给出的train.py去训练,实际上就是对原始的train.py做了修改,设置不加载预训练模型,那为何前面要让我们去改yolov3.cfg文件呢,我感觉这两个操作很矛盾。
准备数据集
新建文件夹
1) 新建一个文件夹
VOCdevkit;2) 在
VOCdevkit下新建文件夹VOC2007;3) 在
VOC2007下,建立如下文件夹Annotations、ImageSets、JPEGImages、SegmentationClass、SegmentationObject(后面两个与分割有关暂时没用)
其中
Annotations存放图片xml文件(包括标注的坐标和类别)JPEGImages存放图片(训练所需的图片)而
ImageSets下面又有文件夹Layout、Main、SegmentationImageSets->Main目录下,存放train.txt、val.txt、test.txt、trainval.txt(txt文件中只存放图片的名字,不包括后缀名)标注数据
使用上面提到的
labelImg工具,将图片全部放到JPEGImages文件夹,将生成的xml文件放到Annotations(labelImg工具可以直接设置保存的文件夹)划分数据集
标注好数据之后,需要划分数据集,生成
ImageSets/Main目录下的txt文件,在
VOC2007目录下运行以下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()运行完成后,会在
ImageSets->Main目录下生成这四个文件train.txt、val.txt、test.txt、trainval.txt。
转换数据格式
生成的数据集不能供yolov3直接使用。需要运行voc_annotation.py
- 需要修改
voc_annotation.py
1 | sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] |
- 运行代码:
python voc_annotation.py
在keras-yolo3文件夹下得到3个文件:
2007_test.txt, 2007_train.txt, 2007_val.txt
txt文件中包含图片完整的路径信息、坐标信息和类别信息
包括前面的数据集划分,这里的转化,一直都是划分了三个数据集,但是在后面的训练代码中,实际上是对训练集划分为按照9:1划分训练集和验证集,所以感觉这里分的验证集没有什么用
参数/代码修改
1、修改参数文件yolov3.cfg
打开yolov3.cfg,搜索yolo(共3次),按如下提示修改
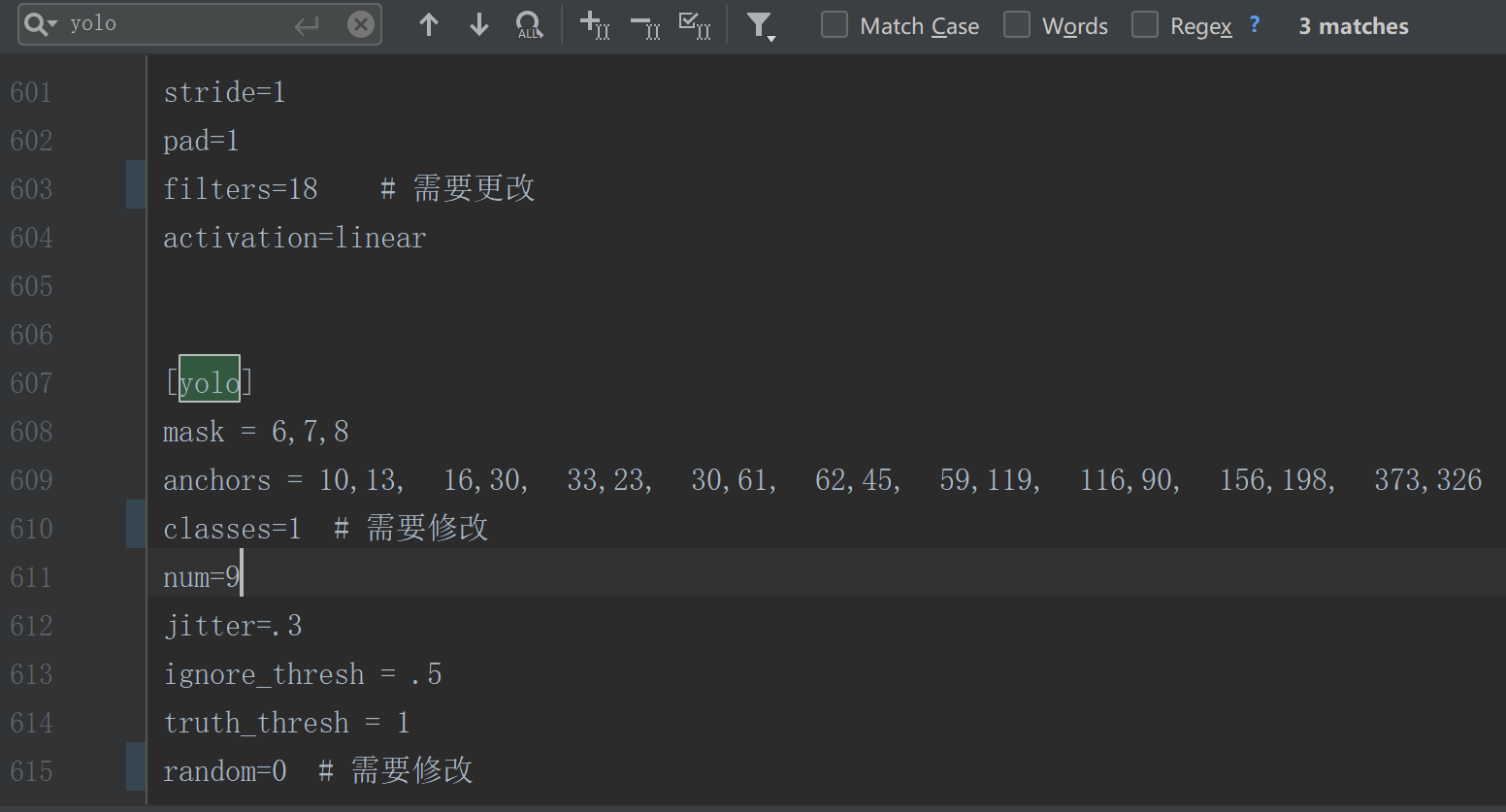
filters:3*(5+len(classes))(yolo层上一层的filters)
classes: 你要训练的类别数
random:原来是1,显存小的话改为0,显存大的话不用改
!!!注意:filter要设置为具体的数字,我第一次居然就写的3*(5+len(classes)), 导致训练完的模型检测不到目标
因为我这里只有目标target一类,所以classes=1,filter=18,因为我是用CPU训练的,所以设置的random=0
2、修改model_data下的voc_classes.txt为自己训练的类别:
将voc_classes.txt修改为自己训练的类别,一行一个类别名称。
3、修改train.py的代码
这里我在修改一些参数后运行时,会报错,所以直接用了博客中给出的代码:
1 | """ |
4、修改yolo.py:
1 | class YOLO(object): |
其实这里的修改可以等到训练完成后,测试的时候再调整
开始训练
python train.py
代码中epochs=500,batch_size=10可根据情况自行修改,因为这个验证码的目标检测问题比较简单,类别也只有1类,我尝试100轮后loss降到15,但是效果并不明显,batch_size一般也根据显存大小来设置,显存小的话batch_size就设置小一些(模型效果不好时,说不定也会和batch_size有关系,可以调小一些试试,因为太大表示计算机一次性读取的图片过多,可能会处理不过来),当然batch_size设置的越大收敛的会越快;另外按照很多博客写的一般loss降到10左右即可使用。
PS:运行train时,遇到了一个错误:AttributeError: module 'keras.backend' has no attribute 'control_flow_ops',参考这篇博客可以解决:https://blog.csdn.net/weixin_44697140/article/details/105891364
测试
运行python yolo_video.py --image
等这条命令运行完,再输入图片的路径进行预测。
关于yolo_video.py的使用可以看github上面的项目描述。
研究下代码应该可以发现,核心检测方法是yolo.py中的detect_image,yolo_video.py这边实际上是一个外层调用,首先通过命令行传入一些参数,包括图片地址,然后打开图片,传入detect_image,然后对返回的图片进行展示。
不过yolo.py中的_defaults的配置需要注意下,可能会需要你来进行一定的调整:
1 | class YOLO(object): |
这里model_path(测试的模型权重路径)、anchors_path(模型anchors数据路径)、classes_path(数据集种类路径)我们训练前已经调整过,这里不需要再做调整。
score代表一个阈值,只有置信度高于此值的目标才会被框出来,iou交并比(Intersection-over-Union,IoU),是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值(可以看看上面我给出的介绍YOLO的文章,里面有提到这一概念)。当检测到Box比较多时,可以适当的调大这两个值,以搜寻最匹配的结果;当无法检测到Box时,可以适当减少这两个值,有的博客中有提到将这两个值设置到0.0几来解决检测不到Box的问题,实际上这种方式并不可取,调到这么低才出现的box置信度很低,也就表示结果其实并不准确,也就是治标不治本,本质还是要去提升模型的准确率。
调参
按照以上操作开始训练之后,可能并不一定就能直接获得理想的模型,之后我们需要来调整一些参数来尝试使模型更优。
先记录下我这边的训练情况:
一开始是在windows机器上运行,但是没有显卡,具体环境如下:
windows+CPU(12G内存)+keras(2.3.1)+tersonflow(1.15.0)
训练图片共244张,其中220用于训练,24用于验证。
跑100轮用了12个小时左右吧,但是识别的时候识别率很低,因为只有少数的图片可以检测到目标,大部分都检测不到,所以明显是模型有问题,但是我多次核查我的所有改动和上面的博客中提到的是否一致,基本确定没有什么错误,此外也查询了许多资料,但是没有得到很有效的解决措施。但是基于一些杂七杂八的信息,得知不同的环境对结果也会有所不同,如有无GPU,tersonflow版本等。于是我换了一个有GPU的环境,打算尝试下,环境如下:
ubuntu+GPU(GeForce GTX 1050 Ti/4G显存)+keras(2.2.4)+tersonflow-gpu(1.13.0)
之后我对input_shape做了调整,不再使用原始的416*416,因为要求长宽都是16的倍数即可,而我的图片长宽正好为320*160,那为啥不直接就用原始尺寸呢,说不定可以得到更精确的结果。因为显存只有4G,继续保持batch_size=8,将epochs扩大了一倍调整为200(本来想的是有显卡训练会很快,但实际发现训练依然很慢,只比CPU版本有一丢丢的提升,平均一轮165秒,200轮也需要9个多小时)
本次训练结束后测试效果依然不理想,真是让人头大,应该所有操作完全按照这两篇博客讲的来进行的,或许是博客中有些步骤并不对或者遗漏了某些操作,经过查资料对keras yolov3的进一步了解,我提出了一些疑问(具体看下载使用这部分内容),所以接下来我进行了一系列的尝试,为了加以区分,加上小标题:
第一次
重新生成编辑yolov3.cfg然后重新生成h5文件,然后使用原始的train.py(加载预训练模型)
1、首先将yolov3.cfg的batch改为64,subdivisions改为16,width=320,height=160,如果keras真的未使用该配置,那做了修改也不会有什么影响,万一使用了,那也就保证了参数正确;然后将random改为1,因为我下面还是在有4G显存的机器上训练,所以可以尝试下改为1;filters和classes肯定还是要改的,不过之前已经改过了;
2、重新生成h5文件:python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5(坑也太多了,之前转换没问题,现在转换又开始报编码错误了,原因在cfg文件中加了中文注释,大家注意下……)
3、重新调整train.py,首先换为原始train.py文件,修改:
annotation_path = '2007_train.txt'
input_shape = (320,160)
batch_size = 16(有两处,因为之前设置batch_size=8训练好像没啥压力,所以这次调大点)
开始训练后,额,速度好像倒是挺快,val_loss=nan!!!,貌似哪里不太对,我怀疑因为使用的是预训练模型,但是又擅自改变了input_shape导致的,所以先把input_shape改为(416, 416),包括cfg文件里的width和height,然后重新生成h5文件,然后再次训练,好像依然不行……难道这里面是不能使用预训练模型的?
这里转念一想,前50轮好像是“预热”,开始训练时有这样的提示:
1 | Load weights model_data/yolo_weights.h5. |
所以大胆猜想了一下,因为只调整了最后两层(这也是为什么训练的这么快),实际模型可能与我需要的相差甚远,等过了50轮之后再看看,果然50轮之后有了val_loss,但是在训练到100多轮之后,学习率变得极低
1 | Epoch 00104: ReduceLROnPlateau reducing learning rate to 9.999999717180686e-11. |
损失也降不下去了,导致整个训练提前结束了。没办法拿模型测试了一下,主观上感觉好像比以前稍微强点,对差不多半数的图片都能识别出box,虽然不准确,大小也不对,但是基本是定位在目标范围内。本来想的是看看怎么去优化模型,但是网上几乎查不到什么有用的资料,暂时不知道该怎么去优化。
第二次
考虑到针对keras的相关文章都没有提到对cfg文件除filter,classes、random的修改,所以我打算对自己做的多余的修改进行复原,然后重新生成h5文件,然后使用预训练模型,并把shape也还原为(416, 416),开始训练发现此次的初始loss相比第一次大很多,并且速度也慢了很多,虽然不确定会有提升,但是这说明做的修改还是会产生影响的?
开始训练后,在初始的50轮预热之后,报错导致训练终止:
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info
上网查了是由于显存不够,所以调整batch_size=8继续训练。
第51轮,自动Killed……难道还是因为显存不够?
第三次
在第二次调整后训练的过程中,仔细思考了下如何针对第一次的模型进行优化(因为其实对第二次根本不报啥希望),然后想到anchors(锚点),在yolov3中也叫先验框,这个是作者根据VOC数据集利用kmeans聚类得到的一些先验框大小,原始的共有9类:10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326,考虑到我的目标只有一类(滑块缺口),并且大小基本相同,或许应该根据自己的数据集来生成适用的先验框,正好项目中的kmeans.py就具备这样的功能,kmeans.py可以根据你自己的xml数据生成新的anchors(锚点),只需要更改filename和cluster_number即可:
1 | if __name__ == "__main__": |
这里我改成只生成3种大小的先验框,完全没必要生成9种,其实我感觉一种也可以,但是发现不同图片的滑块大小确实会不太一样,所以觉得生成3种大小相比一种或许能够有所提高。
生成的anchors如下(这个每次运行结果可能都不太一样):
1 | K anchors: |
然后要做的事情:
1、首先跟第一次的所有调整保持一致;
2、cfg文件的anchors改成这三组数值,一共有三处要改,然后重新生成h5文件;
3、修改model_data/yolo_anchors.txt文件内容为这三组数值;
4、train.py 修改input_shape(320, 160),batch_size=16
运行报错
1 | File "/home/qxb/liutengfei/keras-yolo3/yolo3/model.py", line 376, in yolo_loss |
看了下是因为对anchors进行了修改,但是没有改model.py,也就是模型和配置不匹配,上网查了资料,看到了这篇文章基于keras的YOLOV3改变锚框数量代码操作,特别契合我的需求。
我们这里是将原有的9个anchors(每个尺度3个anchors)改为3个anchors(每个尺度1个anchors),要进行以下操作:
1、对于cfg文件,不仅要修改anchors,同时要调整num=3(原先为9),mask分别改为2, 1, 0;random和classes根据自身情况而定。改完后,每个[yolo]上面几行的filters改为x(5+classes)其中X就是预设的anchor数量,此处我们预设的是1(之前是3,还记得上面是让改的是3\(5+classes)),并且只有一类,所以总共是6;改完记得重新生成h5文件。
2、修改model.py文件num_layers要保证为3,所以在这个文件内出现的num_layer下面的//3,都给去掉;另外anchor_mask改为如下:
1 | anchor_mask = [[2], [1], [0]] if num_layers==3 else [[3,4,5], [1,2,3]] |
此次训练依然提前终止,因为学习率在第120轮左右变得极低,不过此次损失值降到了21左右,相比之前的80多也算有了极大的进步,不过测试结果并不理想,测了几个大概都是这样:

对着测试结果思考了一会,感觉哪里不太对劲,前面还在设置先验框来着,我先验框的大小已经明确给出了,你的检测Box给我一个长方形的是什么鬼,明显不是模型的问题,肯定哪里配置错了,上网一查,果然查到了类似的问题:
问题描述:预测框的中心位置正常,但是预测的框的width和height不正常。
解决方法:使得训练的配置cfg和测试中cfg的输入width, height, anchorbox保持一致!
虽然这里给出的cfg配置文件我的肯定没有问题,并且测试是不需要cfg文件的,但是根据同样的道理,也就是说训练和测试的大小不一致可能会导致这个问题,然后我真的在训练代码中发现了问题:
input_shape = (320, 160) # multiple of 32, hw
这里给出了注释,这是高x宽,我写的320*160实际上宽x高,虽然这里写错了应该会对模型的精度造成一定的影响,只要我检测的时候也这样来配置应该可以正常检测,由于我一开始测试的yolo.py中model_image_size=(320, 160),那我换成(160, 320)或许可以,一试果然可以:

难道说测试代码中的model_image_size实际是宽x高?测了一些图片,感觉准确率其实还可以(准确率在百分之六七十吧,至少比前几次有了质的飞跃),但是我觉得按照正确的shape重新训练一个模型,准确率应该更高,于是改了train.py再次训练。
本次训练同样是提前结束,不过这次损失只降到24,还没有上次降得低,测试了一下,准确率跟上面的差不多,不过测试的话model_image_size还是要设置为(160, 320)才比较准确,所以并不是宽x高?也是高x宽?具体这里也搞不清楚到底什么原因,但是好像只要按照高x宽并且和真实测试图片保持一致就可以,而不用管训练中如何设置的。
因为我之前一共标了305张图片,经过上面的划分,实际训练和验证只使用了244张,我批量测试了一下剩余的61张,差不多有44张算是比较准确的定位了(这个准确我是按照左边界是否准确来判定的,因为左边界不准确后面滑动的距离肯定也会算错,那就无法通过验证)类似这样:

准确率在70%以上,不过感觉还是有点低,因为损失毕竟也没有降到10左右,所以我打算把这61张也放进训练集进行训练,反正后面测试还可以随便再下一些验证码图片。
加上之后训练结果依然是70%左右,虽然损失下降到了20,但是准确率没有实质性的提升;之后我就没有再去尝试提升准确率了,其实还可以不使用预训练模型来尝试训练一下,后面如果做了相关尝试有比较好的效果再来更新……
批量测试以及实际应用
yolo_video中写了一大堆的命令行参数,对于不了解这块的来说反而容易懵,实际上就是去调用yolo中的detect_image,所以我们完全可以自己编写一个脚本,一个循环读取你要测试的图片,使用PIL的Image加载,然后传入detect_image,原始的detect_image方法返回给我们检测后的图片(会把检测的目标图片标注到图片上),所以我们直接保存到一个文件夹中,后面去挨个看一遍就知道大概的效果了。
当然我们在实际应用中,一般需要用到检测到的目标的坐标,这时候我们修改一下detect_image的内部逻辑,把坐标返回出来就OK了。
不过这里要注意一个int32的问题,yolo中是把相关坐标值转换成了int32类型,这里我比较疑惑,难道检测到的目标位置不会是小数吗?另外,因为转换成了int32类型,导致我后面使用的时候出错(json.dumps int32型的数据会报错),后来发现这个问题后就把yolo中相关的astype('int32')去掉了。