本文章参考《Python深度学习》
深度学习用于计算机视觉(上篇)
本系列文章内容较多,共分为三篇,主要包括以下内容:
- 理解卷积神经网络(convnet)
- 使用数据增强来降低过拟合
- 使用预训练的卷积神经网络进行特征提取
- 微调预训练的卷积神经网络
- 将卷积神经网络学到的内容及其如何做出分类决策可视化
上篇主要包括前两点,中篇包括三四点,下篇主要围绕第五点。
卷积神经网络简介
我们先通过一个简单的例子来展示什么卷积神经网络,它是Conv2D层和MaxPooling2D层的堆叠。
1 | from keras import layers |
卷积神经网络接收形状为 (image_height, image_width, image_channels) 的输入张量(不包括批量维度)。本例中设置卷积神经网络处理大小为 (28, 28, 1) 的输入张量, 这正是 MNIST 图像的格式。
model.summary()可以用来查看卷积神经网络的架构
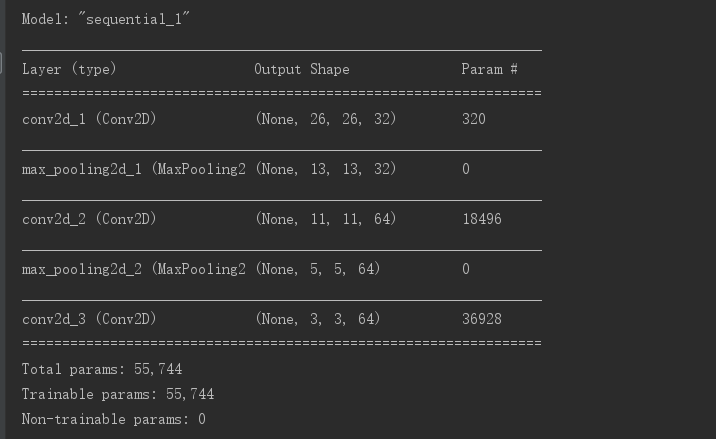
可以看到,每个 Conv2D 层和 MaxPooling2D 层的输出都是一个形状为 (height, width, channels) 的 3D 张量。宽度和高度两个维度的尺寸通常会随着网络加深而变小。通道数量由传 入 Conv2D 层的第一个参数所控制(32 或 64)。
下一步是将最后的输出张量[大小为 (3, 3, 64)]输入到一个密集连接分类器网络中, 即 Dense 层的堆叠,你已经很熟悉了。这些分类器可以处理 1D 向量,而当前的输出是 3D 张量。 首先,我们需要将 3D 输出展平为 1D,然后在上面添加几个 Dense 层。
1 | model.add(layers.Flatten()) |
我们将进行 10 类别分类,最后一层使用带 10 个输出的 softmax 激活。现在网络的架构如下
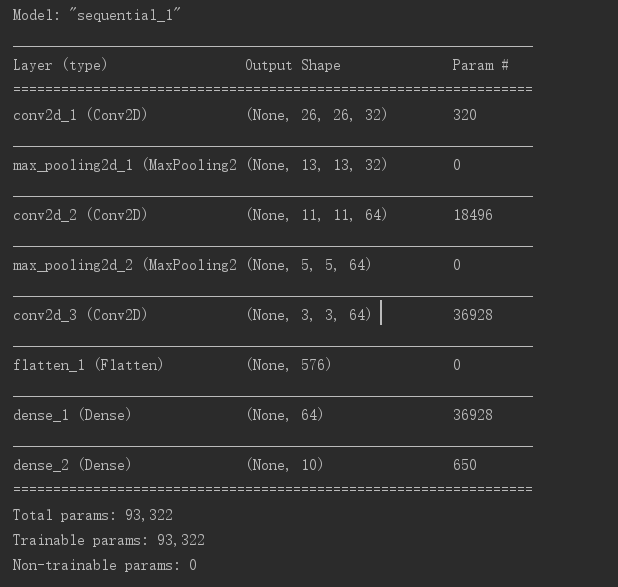
如你所见,在进入两个 Dense 层之前,形状 (3, 3, 64) 的输出被展平为形状 (576,) 的向量(3x3x64=576)。 下面我们在 MNIST 数字图像上训练这个卷积神经网络。
1 | from keras.datasets import mnist |
这里的训练集数据的shape是 (60000, 28, 28),而输入到神经网络的数据格式是4D张量,(samples, height, width, channels),所以这里使用reshape转换为目标格式(reshape一定要在明确自己的需求的情况下使用,我在前面的文章中写过我在自己处理验证码数据时,错误使用reshape带来的大坑)
另外,这里除以255,to_categorical等知识前面的文章其实基本都已经介绍过,这里就不再一一细说。
这里使用卷积神经网络训练手写数字分类,能达到99%的准确率,相比直接使用全连接层网络,效果得到了一定的提升(因为这个任务比较简单,使用全连接层网络的准确率也是比较高的)
卷积运算
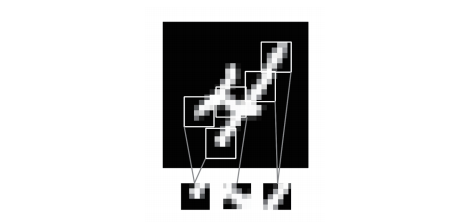
密集连接层和卷积层的根本区别在于,Dense 层从输入特征空间中学到的是全局模式(比如对于 MNIST 数字,全局模式就是涉及所有像素的模式),而卷积层学到的是局部模式(见下图),对于图像来说,学到的就是在输入图像的二维小窗口中发现的模式。在上面的例子中, 这些窗口的大小都是 3×3。
这个重要特性使卷积神经网络具有以下两个有趣的性质。
卷积神经网络学到的模式具有平移不变性(translation invariant)。卷积神经网络在图像右下角学到某个模式之后,它可以在任何地方识别这个模式,比如左上角。对于密集连 接网络来说,如果模式出现在新的位置,它只能重新学习这个模式。这使得卷积神经网络在处理图像时可以高效利用数据(因为视觉世界从根本上具有平移不变性),它只需要更少的训练样本就可以学到具有泛化能力的数据表示。
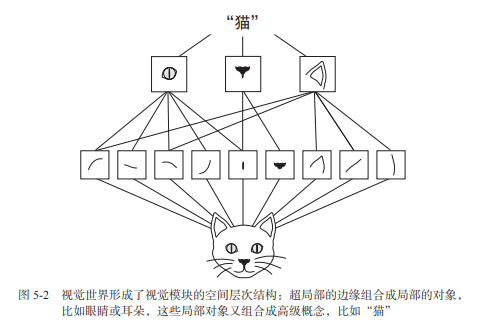
卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns),见下图。 第一个卷积层将学习较小的局部模式(比如边缘),第二个卷积层将学习由第一层特征组成的更大的模式,以此类推。这使得卷积神经网络可以有效地学习越来越复杂、越来越抽象的视觉概念(因为视觉世界从根本上具有空间层次结构)。
对于包含两个空间轴(高度和宽度)和一个深度轴(也叫通道轴)的 3D 张量,其卷积也叫特征图(feature map)。卷积运算从输入特征图中提取图块,并对所有这些图块应用相同的变换,生成输出特征图(output feature map)。该输出特征图仍是一个 3D 张量,具有宽度和高度,其深度可以任意取值,因为输出深度是层的参数,深度轴的不同通道不再像 RGB 输入那样代表特定颜色,而是代表过滤器 (filter)(等于过滤器数量)。
卷积由以下两个关键参数所定义。
- 从输入中提取的图块尺寸:这些图块的大小通常是 3×3 或 5×5。本例中为 3×3,这是很常见的选择。
- 输出特征图的深度:卷积所计算的过滤器的数量。本例第一层的深度为 32,最后一层的深度是 64。
对于 Keras 的 Conv2D 层,这些参数都是向层传入的前几个参数:Conv2D(output_depth, (window_height, window_width))。
卷积的工作原理:在 3D 输入特征图上滑动(slide)这些 3×3 或 5×5 的窗口,在每个可能的位置停止并提取周围特征的 3D 图块[形状为 (window_height, window_width, input_ depth)]。然后每个 3D 图块与学到的同一个权重矩阵[叫作卷积核(convolution kernel)]做 张量积,转换成形状为 (output_depth,) 的 1D 向量。然后对所有这些向量进行空间重组, 使其转换为形状为 (height, width, output_depth) 的 3D 输出特征图。输出特征图中的 每个空间位置都对应于输入特征图中的相同位置(比如输出的右下角包含了输入右下角的信 息)。举个例子,利用 3×3 的窗口,向量 output[i, j, :] 来自 3D 图块 input[i-1:i+1, j-1:j+1, :]。整个过程详见图。
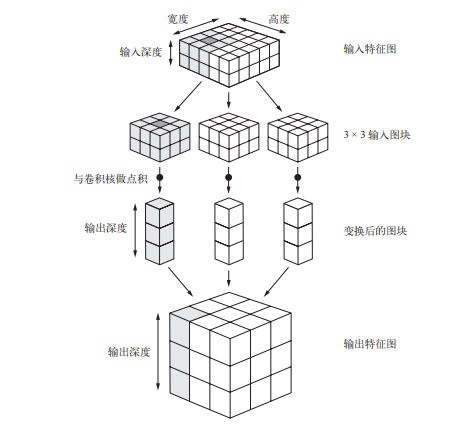
以上过程描述非常形象,多读几遍有助于理解,也可以和前面的一篇CNN原理一起看
注意,输出的宽度和高度可能与输入的宽度和高度不同。不同的原因可能有两点。
- 边界效应,可以通过对输入特征图进行填充来抵消。
- 使用了步幅(stride)。
这两个概念在上篇CNN文章已经介绍的很清楚了,并且是比较简单的概念这里就不再说了。
最大池化
每个 MaxPooling2D 层之后,特征图的尺寸都会减半。例如,在第一个 MaxPooling2D 层之前,特征图的尺寸是 26×26,但最大池化运算将其减半为 13×13。这就是最大池化的作用:对特征图进行下采样,与步进卷积类似。
最大池化是从输入特征图中提取窗口,并输出每个通道的最大值。它的概念与卷积类似, 但是最大池化使用硬编码的 max 张量运算对局部图块进行变换,而不是使用学到的线性变换(卷积核)。最大池化与卷积的最大不同之处在于,最大池化通常使用 2×2 的窗口和步幅 2,其目的是将特征图下采样 2 倍。与此相对的是,卷积通常使用 3×3 窗口和步幅 1。
虽然前面文章也讲过最大池化,但是书中这里从神经网络架构的角度来重新理解了一下为什么需要池化层。
1 | model_no_max_pool = models.Sequential() |
如果没有最大池化层,模型的架构如下

这种架构有什么问题?有如下两点问题。
这种架构不利于学习特征的空间层级结构。第三层的 3×3 窗口中只包含初始输入的 7×7 窗口中所包含的信息。卷积神经网络学到的高级模式相对于初始输入来说仍然很小, 这可能不足以学会对数字进行分类(你可以试试仅通过 7 像素×7 像素的窗口观察图像 来识别其中的数字)。我们需要让最后一个卷积层的特征包含输入的整体信息。
最后一层的特征图对每个样本共有 22×22×64=30 976 个元素。这太多了。如果你将其 展平并在上面添加一个大小为 512 的 Dense 层,那一层将会有 1580 万个参数。这对于这样一个小模型来说太多了,会导致严重的过拟合。 简而言之,使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
注意,最大池化不是实现这种下采样的唯一方法,使用步幅或者平均池化也都可以,但是最大池化的效果往往是最好的。
在小数据集上从头开始训练一个卷积神经网络
本例我们将重点讨论猫狗图像分类,数据集中包含 4000 张猫和狗的图像 (2000 张猫的图像,2000 张狗的图像)。我们将 2000 张图像用于训练,1000 张用于验证,1000 张用于测试。
训练所需的样本数量与你所要训练网络的大小和深度有关,只用几十个样本训练卷积神经网络就解决一个复杂问题是不可能的,但如果模型很小, 并做了很好的正则化,同时任务非常简单,那么几百个样本可能就足够了。
准备数据
这里用到的猫狗分类数据集不在keras中,可以从https://www.kaggle.com/ c/dogs-vs-cats/data下载原始数据集,需要注册账号,并且容易验证码刷不出来,不过网上有很多分享的百度网盘下载链接也可以下载。
这些图像都是中等分辨率的彩色 JPEG 图像,下载数据并解压之后,你需要创建一个新数据集,其中包含三个子集:每个类别各1000个样本的训练集、每个类别各500个样本的验证集和每个类别各500个样本的测试集。
划分数据集的代码:
1 | import os |
这个步骤不写代码,手动操作也是可以的。
构建网络
1 | from keras import layers |
前面已经介绍了卷积神经网络是Conv2D层和MaxPooling2D层的堆叠;我们再来看一下特征图的维度如何随着每层变化
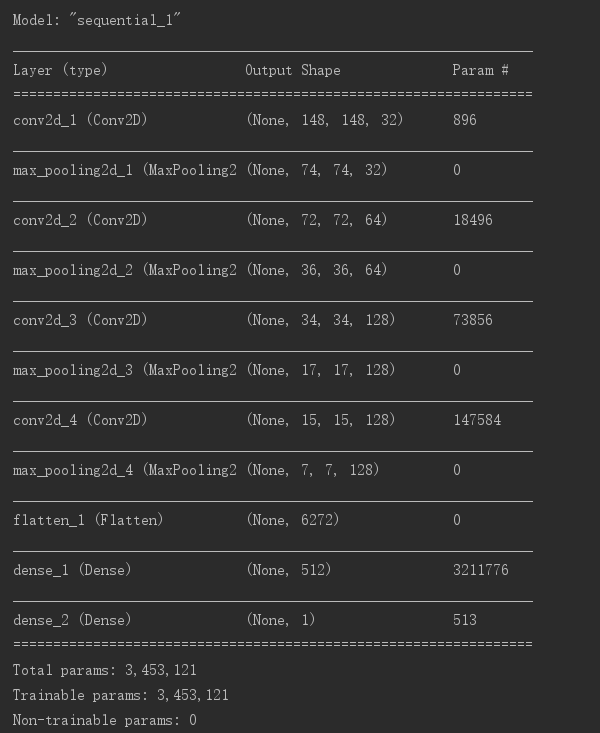
经过前面的学习基本也可以理解这个图中每个数字的由来(除了param那一列),因为卷积大小是(3, 3)所以每次卷积后高和宽减小2,最大池化后高和宽减半,输出通道数量等于卷积核数量。在编译这一步,和前面一样,我们将使用 RMSprop 优化器。因为网络最后一层是单一 sigmoid 单元,所以我们将使用二元交叉熵作为损失函数。
1 | model.compile(loss='binary_crossentropy', |
数据预处理
将数据输入神经网络之前,应该将数据格式化为经过预处理的浮点数张量,现在数据以JPEG文件的形式保存在硬盘中,所以数据预处理步骤大致如下:
1、读取图像文件
2、将JPEG文件解码为RGB像素网格
3、将这些像素网格转换为浮点数张量
4、将像素值(0~255范围内)缩放到[0, 1]区间(正如你所见,神经网络喜欢处理较小的输入值)
这些步骤可能看起来有点吓人,但幸运的是,Keras 拥有自动完成这些步骤的工具。Keras 有一个图像处理辅助工具的模块,位于 keras.preprocessing.image。特别地,它包含 ImageDataGenerator 类,可以快速创建 Python 生成器,能够将硬盘上的图像文件自动转换 为预处理好的张量批量。
1 | from keras.preprocessing.image import ImageDataGenerator |
flow_from_directory(directory): 以文件夹路径为参数,生成经过数据提升/归一化后的数据,在一个无限循环中无限产生batch数据,参数及其含义
- directory: 目标文件夹路径,对于每一个类,该文件夹都要包含一个子文件夹,子文件夹中任何JPG、PNG、BNP、PPM的图片都会被生成器使用
- target_size: 整数tuple,默认为(256, 256). 图像将被resize成该尺寸
- color_mode: 颜色模式,为”grayscale”,”rgb”之一,默认为”rgb”.代表这些图片是否会被转换为单通道或三通道的图片.
- classes: 可选参数,为子文件夹的列表,如[‘dogs’,’cats’]默认为None. 若未提供,则该类别列表将从
directory下的子文件夹名称/结构自动推断。每一个子文件夹都会被认为是一个新的类。(类别的顺序将按照字母表顺序映射到标签值)。通过属性class_indices可获得文件夹名与类的序号的对应字典。 - class_mode: “categorical”, “binary”, “sparse”或None之一. 默认为”categorical. 该参数决定了返回的标签数组的形式, “categorical”会返回2D的one-hot编码标签,”binary”返回1D的二值标签.”sparse”返回1D的整数标签,如果为None则不返回任何标签, 生成器将仅仅生成batch数据, 这种情况在使用
model.predict_generator()和model.evaluate_generator()等函数时会用到. - batch_size: batch数据的大小,默认32
- shuffle: 是否打乱数据,默认为True
- seed: 可选参数,打乱数据和进行变换时的随机数种子
- save_to_dir: None或字符串,该参数能让你将提升后的图片保存起来,用以可视化
- save_prefix:字符串,保存提升后图片时使用的前缀, 仅当设置了
save_to_dir时生效 - save_format:”png”或”jpeg”之一,指定保存图片的数据格式,默认”jpeg”
- flollow_links: 是否访问子文件夹中的软链
一个生成器的输出:生成150x150的RGB图像[形状为(20, 150, 150, 3)]与二进制标签[形状为(20,)]组成的批量。每个批量中包含20个样本(批量大小)。
1 | history = model.fit_generator( |
利用生成器,我们让模型对数据进行拟合。我们将使用fit_generator方法来拟合,它在数据生成器上的效果和fit相同,它的第一个参数是一个Python生成器,可以不停地生成输入和目标组成的批量,比如train_generator。
因为数据是不断生成的,所以Keras模型要知道每一轮需要从生成器中抽取多少个样本,这是steps_per_epoch参数的作用:从生成 器中抽取 steps_per_epoch 个批量后(即运行了 steps_per_epoch 次梯度下降),拟合过程 将进入下一个轮次。本例中,每个批量包含 20 个样本,所以读取完所有 2000 个样本需要 100 个批量。
使用 fit_generator 时,你可以传入一个 validation_data 参数,其作用和在 fit 方 法中类似。值得注意的是,这个参数可以是一个数据生成器,但也可以是 Numpy 数组组成的元 组。如果向 validation_data 传入一个生成器,那么这个生成器应该能够不停地生成验证数 据批量,因此你还需要指定 validation_steps 参数,说明需要从验证生成器中抽取多少个批次用于评估。
1 | model.save('cats_and_dogs_small_1.h5') |
始终在训练完成后保存模型,这是一种良好实践。
我们来分别绘制训练过程中模型在训练数据和验证数据上的损失和精度
1 | acc = history.history['acc'] |
plt.legend()函数主要的作用就是给图加上图例,plt.legend([x,y,z])里面的参数使用的是list的的形式将图表的的名称喂给这个函数;
plt.figure()主要是方便连续画几个图片。
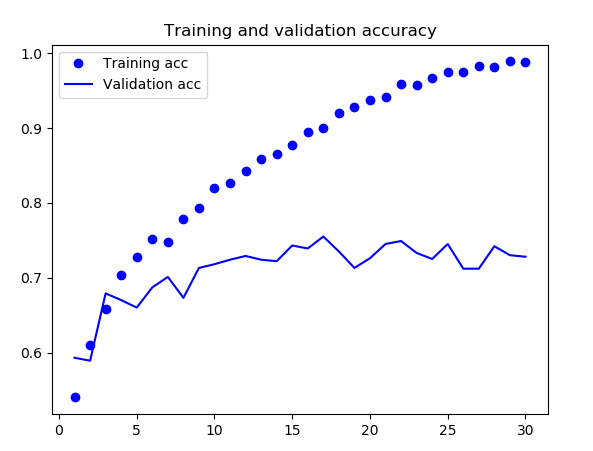
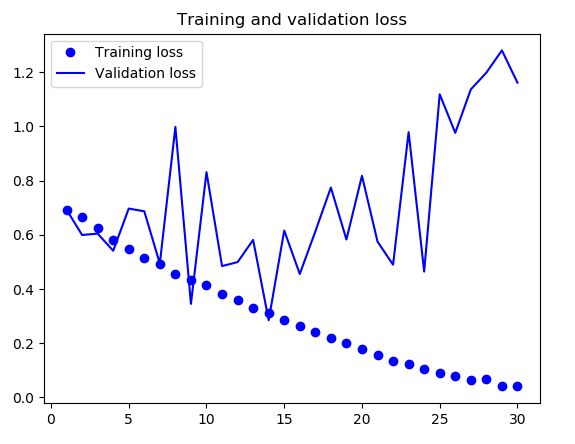
从这些图像中都能看出过拟合的特征。训练精度随着时间线性增加,直到接近 100%,而验证精度则停留在 70%~72%。验证损失仅在 5 轮后就达到最小值(后面的波动特别大,也不知道啥原因),然后保持不变,而训练损失则 一直线性下降,直到接近于 0。 因为训练样本相对较少(2000 个),所以过拟合是你最关心的问题。前面已经介绍过几种降低过拟合的技巧,比如 dropout 和权重衰减(L2 正则化)。现在我们将使用一种针对于计算机视觉领域的新方法,在用深度学习模型处理图像时几乎都会用到这种方法,它就是数据增强 (data augmentation)。
数据增强
过拟合的原因是学习样本太少,导致无法训练出能够泛化到新数据的模型。如果拥有无限的数据,那么模型能够观察到数据分布的所有内容,这样就永远不会过拟合。数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加 (augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察 到数据的更多内容,从而具有更好的泛化能力。
在 Keras 中,这可以通过对 ImageDataGenerator 实例读取的图像执行多次随机变换来实现。我们先来看一个例子。
1 | datagen = ImageDataGenerator( |
这里只选择了几个参数(想了解更多参数,请查阅 Keras 文档)。我们来快速介绍一下这些参数的含义。
- rotation_range 是角度值(在 0~180 范围内),表示图像随机旋转的角度范围。
- width_shift 和 height_shift 是图像在水平或垂直方向上平移的范围(相对于总宽 度或总高度的比例)。
- shear_range 是随机错切变换的角度。
- zoom_range 是图像随机缩放的范围。
- horizontal_flip 是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真 实世界的图像),这种做法是有意义的。
- fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移
显示几个随机增强后的图像
1 | fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)] |

如果你使用这种数据增强来训练一个新网络,那么网络将不会两次看到同样的输入。但网 看到的输入仍然是高度相关的,因为这些输入都来自于少量的原始图像。你无法生成新信息, 而只能混合现有信息。因此,这种方法可能不足以完全消除过拟合。为了进一步降低过拟合, 你还需要向模型中添加一个 Dropout 层,添加到密集连接分类器之前。
Dropout层添加在Flatten操作之后
1 | model.add(layers.Flatten()) |
我们再次来训练这个使用了数据增强和 dropout 的网络
1 | train_datagen = ImageDataGenerator( |
我们再次绘制结果,使用了数据增强和 dropout 之后,模型不再过拟合: 训练曲线紧紧跟随着验证曲线。现在的精度为 82%,比未正则化的模型提高了 15%(相对比例)。
实际测试验证精度在77%左右
通过进一步使用正则化方法以及调节网络参数(比如每个卷积层的过滤器个数或网络中的 层数),你可以得到更高的精度,可以达到86%或87%。但只靠从头开始训练自己的卷积神经网络, 再想提高精度就十分困难,因为可用的数据太少。想要在这个问题上进一步提高精度,需要使用预训练的模型,会在下一篇文章介绍。