本文章参考《Python深度学习》
深度学习用于计算机视觉(下篇)
本系列文章内容较多,共分为三篇,主要包括以下内容:
- 理解卷积神经网络(convnet)
- 使用数据增强来降低过拟合
- 使用预训练的卷积神经网络进行特征提取
- 微调预训练的卷积神经网络
- 将卷积神经网络学到的内容及其如何做出分类决策可视化
上篇主要包括前两点,中篇包括三四点,下篇主要围绕第五点。
卷积神经网络的可视化
人们常说,深度学习模型是“黑盒”,即模型学到的表示很难用人类可以理解的方式来提取和呈现。虽然对于某些类型的深度学习模型来说,这种说法部分正确,但对卷积神经网络来说绝对不是这样。卷积神经网络学到的表示非常适合可视化,很大程度上是因为它们是视觉概念的表示,这篇文章介绍三种最容易理解也最有用的可视化方法。
- 可视化卷积神经网络的中间输出(中间激活):有助于理解卷积神经网络连续的层如何 对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义。
- 可视化卷积神经网络的过滤器:有助于精确理解卷积神经网络中每个过滤器容易接受的 视觉模式或视觉概念。
- 可视化图像中类激活的热力图:有助于理解图像的哪个部分被识别为属于某个类别,从 而可以定位图像中的物体。
对于第一种方法(即激活的可视化),我们将使用 前面在猫狗分类问题上从头开始训练的小型卷积神经网络。对于另外两种可视化方法,我们将使用前面介绍的 VGG16模型。
可视化中间激活
可视化中间激活,是指对于给定输入,展示网络中各个卷积层和池化层输出的特征图(层的输出通常被称为该层的激活,即激活函数的输出)。这让我们可以看到输入如何被分解为网络 学到的不同过滤器。我们希望在三个维度对特征图进行可视化:宽度、高度和深度(通道)。每个通道都对应相对独立的特征,所以将这些特征图可视化的正确方法是将每个通道的内容分别绘制成二维图像。
这里我们使用的之前的从头开始训练的小型卷积神经网络
1 | model = models.Sequential() |
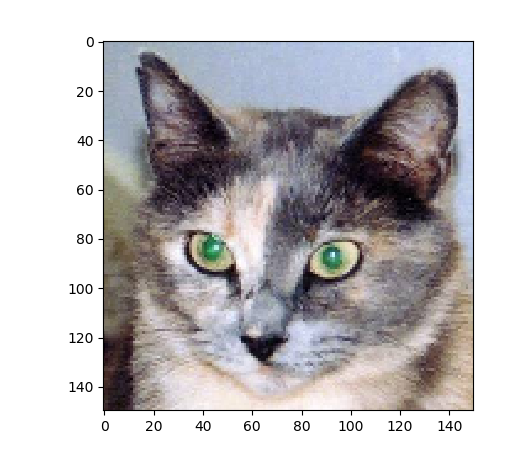
接下来,我们要输入一张图像,一张猫的图像,他不属于网络的训练图像
1 | img_path = 'D:/python_project/深度学习/keras_t/samples/cats_and_dogs_small/test/cats/cat.1700.jpg' |
我们来显示这张图像
1 | import matplotlib.pyplot as plt |
为了提取想要查看的特征图,我们需要创建一个Keras 模型,以图像批量作为输入,并输出所有卷积层和池化层的激活。为此,我们需要使用 Keras 的 Model 类。模型实例化需要两个参数:一个输入张量(或输入张量的列表)和一个输出张量(或输出张量的列表)。得到的类是一个 Keras 模型,就像你熟悉的 Sequential 模型一样,将特定输入映射为特定输出。Model 类允许模型有多个输出,这一点与 Sequential 模型不同。
1 | from keras import models |
输入一张图像,这个模型将返回原始模型前 8 层的激活值。这是你在本书中第一次遇到的 多输出模型,之前的模型都是只有一个输入和一个输出。一般情况下,模型可以有任意个输入 和输出。这个模型有一个输入和 8 个输出,即每层激活对应一个输出。
1 | # 返回8个Numpy数组组成的列表,每个层激活对应一个Numpy数组 |
它是大小为 148×148 的特征图,有 32 个通道。
我们来绘制原始模型第一层激活的第 4 个和第7个通道
1 | import matplotlib.pyplot as plt |
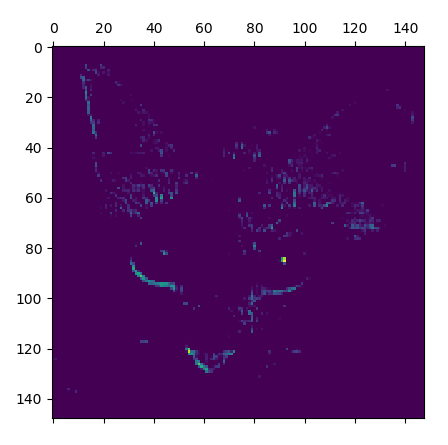
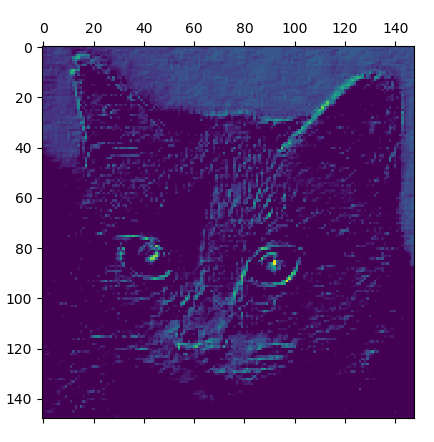
请注意,你的通道可能与此不同,因为卷积层学到的过滤器并不是确定的
下面我们来绘制网络中所有激活的完整可视化。我们需要在 8 个特征图中的每一个中提取并绘制每一个通道,然后将结果叠加在一个大的图像张量中,按通道并排。
1 | layer_names = [] |

这里需要注意以下几点。
- 第一层是各种边缘探测器的集合。在这一阶段,激活几乎保留了原始图像中的所有信息。
- 随着层数的加深,激活变得越来越抽象,并且越来越难以直观地理解。它们开始表示更 高层次的概念,比如“猫耳朵”和“猫眼睛”。层数越深,其表示中关于图像视觉内容 的信息就越少,而关于类别的信息就越多。
激活的稀疏度(sparsity)随着层数的加深而增大。在第一层里,所有过滤器都被输入图 像激活,但在后面的层里,越来越多的过滤器是空白的。也就是说,输入图像中找不到 这些过滤器所编码的模式。
我们刚刚揭示了深度神经网络学到的表示的一个重要普遍特征:随着层数的加深,层所提取的特征变得越来越抽象。更高的层激活包含关于特定输入的信息越来越少,而关于目标的信息越来越多(本例中即图像的类别:猫或狗)。
深度神经网络可以有效地作为信息蒸馏管道 (information distillation pipeline),输入原始数据(本例中是 RGB 图像),反复对其进行变换, 将无关信息过滤掉(比如图像的具体外观),并放大和细化有用的信息(比如图像的类别)。 这与人类和动物感知世界的方式类似:人类观察一个场景几秒钟后,可以记住其中有哪些抽象物体(比如自行车、树),但记不住这些物体的具体外观。