本文章参考《python深度学习》
深度学习用于文本和序列
深度学习用于自然语言处理是将模式识别应用于单词、 句子和段落,这与计算机视觉是将模式识别应用于像素大致相同。
文本向量化
与其他所有神经网络一样,深度学习模型不会接收原始文本作为输入,它只能处理数值张量。 文本向量化(vectorize)是指将文本转换为数值张量的过程。它有多种实现方法。
- 将文本分割为单词,并将每个单词转换为一个向量。
- 将文本分割为字符,并将每个字符转换为一个向量。
- 提取单词或字符的 n-gram,并将每个 n-gram 转换为一个向量。n-gram 是多个连续单词 或字符的集合(n-gram 之间可重叠)。
将文本分解而成的单元(单词、字符或 n-gram)叫作标记(token),将文本分解成标记的过程叫作分词(tokenization)。英文分词相较中文分词简单一些,本身句子的空格就分割了不同的单词,而中文分词需要考虑一些歧义性等问题,比较复杂,后面会有单独的篇章介绍中文分词,这里是针对英文的文本向量化处理。
所有文本向量化过程都是应用某种分词方案,然后将数值向量与生成的标记相关联。这些向量组合成序列张量,被输入到深度神经网络中。
将向量与标记相关联的方法有很多种。这里将介绍两种主要方法:
对标记做one-hot 编码(one-hot encoding)
标记嵌入[token embedding,通常只用于单词,叫作词嵌入(word embedding)]。
补充:理解 n-gram 和词袋
n-gram 是从一个句子中提取的 N 个(或更少)连续单词的集合。这一概念中的“单词” 也可以替换为“字符”。
下面来看一个简单的例子。
考虑句子“The cat sat on the mat.”(“猫坐在垫子上”)。
它可以被分解为以下二元语法(2-grams)的集合。
{“The”, “The cat”, “cat”, “cat sat”, “sat”, “sat on”, “on”, “on the”, “the”, “the mat”, “mat”}
这个句子也可以被分解为以下三元语法(3-grams)的集合。
{“The”, “The cat”, “cat”, “cat sat”, “The cat sat”, “sat”, “sat on”, “on”, “cat sat on”, “on the”, “the”, “sat on the”, “the mat”, “mat”, “on the mat”}
这样的集合分别叫作二元语法袋(bag-of-2-grams)及三元语法袋(bag-of-3-grams)。这里袋(bag)这一术语指的是,我们处理的是标记组成的集合,而不是一个列表或序列,即标记没有特定的顺序。这一系列分词方法叫作词袋(bag-of-words)。
词袋是一种不保存顺序的分词方法,因此它往往被用于浅层的语言处理模型,而不是深度学习模型。提取 n-gram 是一种特征工程,深度学习不需要这种死板而又不稳定的方法,并将其替换为分 层特征学习。深度学习中的一维卷积神经网络和循环神经网络,都能够通过观察连续的单词序列或字符序列来学习单词组和字符组的数据表示,而无须明确知道这些组的存在。因此,这里不进一步讨论 n-gram。但一定要记住,在使用轻量级的浅层文本处理模型时(比 如 logistic 回归和随机森林),n-gram 是一种功能强大、不可或缺的特征工程工具。
单词和字符的 one-hot 编码
one-hot 编码是将标记转换为向量的最常用、最基本的方法。它将每个单词与一个唯一的整数索引相关联, 然后将这个整数索引 i 转换为长度为 N 的二进制向量(N 是词表大小),这个向量只有第 i 个元 素是 1,其余元素都为 0。 当然,也可以进行字符级的 one-hot 编码。
1 | import numpy as np |
1 | import numpy as np |
注意,Keras 的内置函数可以对原始文本数据进行单词级或字符级的 one-hot 编码。你应该使用这些函数,因为它们实现了许多重要的特性,比如从字符串中去除特殊字符、只考虑数据 集中前 N 个最常见的单词(这是一种常用的限制,以避免处理非常大的输入向量空间)。
使用Keras实现单词级one-hot编码
1 | from keras.preprocessing.text import Tokenizer |
注意:这里的word_index只有9个元素,因为The和the被认为是同一个
补充:Keras分词器Tokenizer的使用介绍
fit_on_texts:将输入的句子列表,生成词典,如上面的samples输入后,就生成了词典,通过tokenizer.word_index查看;texts_to_sequences:将句子转换成单词索引序列,如上面的sequences的值为[[1, 2, 3, 4, 1, 5], [1, 6, 7, 8, 9]],代表samples中的句子;texts_to_matrix:将句子序列转换成token矩阵,也就是one-hot编码
不过这里的one_hot_results的shape非三维的,看起来稍微有点奇怪~
one-hot 编码的一种变体是所谓的one-hot 散列技巧(one-hot hashing trick),如果词表中唯 一标记的数量太大而无法直接处理,就可以使用这种技巧。这种方法没有为每个单词显式分配 一个索引并将这些索引保存在一个字典中,而是将单词散列编码为固定长度的向量,通常用一个非常简单的散列函数来实现。(也就是哈希吧~)
这种方法的主要优点在于,它避免了维护一个显式的单词索引, 从而节省内存并允许数据的在线编码(在读取完所有数据之前,你就可以立刻生成标记向量)。 这种方法有一个缺点,就是可能会出现散列冲突(hash collision),即两个不同的单词可能具有相同的散列值,随后任何机器学习模型观察这些散列值,都无法区分它们所对应的单词。如果散列空间的维度远大于需要散列的唯一标记的个数,散列冲突的可能性会减小。
1 | import numpy as np |
使用词嵌入
将单词与向量相关联还有另一种常用的强大方法,就是使用密集的词向量(word vector), 也叫词嵌入(word embedding)。one-hot 编码得到的向量是二进制的、稀疏的(绝大部分元素都 是 0)、维度很高的(维度大小等于词表中的单词个数),而词嵌入是低维的浮点数向量(即密集向量,与稀疏向量相对)。
与 one-hot 编码得到的词向量不同,词嵌入是从数据中学习得到的。常见的词向量维度是 256、512 或 1024(处理非常大的词表时)。与此相对,one-hot 编码的词向量维度通常为 20 000 或更高(对应包含 20 000 个标记的词表)。因此,词向量可以将更多的信息塞入更低的维度中。
获取词嵌入有两种方法。
- 在完成主任务(比如文档分类或情感预测)的同时学习词嵌入。在这种情况下,一开始是随机的词向量,然后对这些词向量进行学习,其学习方式与学习神经网络的权重相同。
- 在不同于待解决问题的机器学习任务上预计算好词嵌入,然后将其加载到模型中。这些词嵌入叫作预训练词嵌入(
pretrained word embedding)。
利用embedding层学习词嵌入
要将一个词与一个密集向量相关联,最简单的方法就是随机选择向量。这种方法的问题在于, 得到的嵌入空间没有任何结构。例如,accurate 和 exact 两个词的嵌入可能完全不同,尽管它们 在大多数句子里都是可以互换的。深度神经网络很难对这种杂乱的、非结构化的嵌入空间进行学习。
说得更抽象一点,词向量之间的几何关系应该表示这些词之间的语义关系。词嵌入的作用应该是将人类的语言映射到几何空间中。例如,在一个合理的嵌入空间中,同义词应该被嵌入 到相似的词向量中,一般来说,任意两个词向量之间的几何距离(比如 L2 距离)应该和这两个 词的语义距离有关(表示不同事物的词被嵌入到相隔很远的点,而相关的词则更加靠近)。除了距离,你可能还希望嵌入空间中的特定方向也是有意义的。
为了更清楚地说明这一点,我们来看一个具体示例。 在图中,四个词被嵌入在二维平面上,这四个词分别是 cat(猫)、dog(狗)、wolf(狼) 和 tiger(虎)。对于我们这里选择的向量表示,这些词之间的某些语义关系可以被编码为几何 变换。例如,从 cat 到 tiger 的向量与从 dog 到 wolf 的向量相等,这个向量可以被解释为“从宠 物到野生动物”向量。同样,从 dog 到 cat 的向量与从 wolf 到 tiger 的向量也相等,它可以被解 释为“从犬科到猫科”向量。
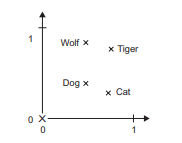
在真实的词嵌入空间中,常见的有意义的几何变换的例子包括“性别”向量和“复数”向量。 例如,将 king(国王)向量加上 female(女性)向量,得到的是 queen(女王)向量。将 king(国王) 向量加上 plural(复数)向量,得到的是 kings 向量。词嵌入空间通常具有几千个这种可解释的、 并且可能很有用的向量。
一个好的词嵌入空间在很大程度上取决于你的任务,因此,合理的做法是对每个新任务都学习一个新的嵌入空间。幸运的是,反向传播让这种 学习变得很简单,而 Keras 使其变得更简单。我们要做的就是学习一个层的权重,这个层就是 Embedding 层。
其实这里的底层原理应该更重要,后面再慢慢研究,这里先看如何应用
1 | from keras.layers import Embedding |
实例化Embedding 层至少需要两个参数: 标记的个数(这里是 1000,即最大单词索引 +1)和嵌入的维度(这里是 64)
最好将 Embedding 层理解为一个字典,将整数索引(表示特定单词)映射为密集向量。它接收整数作为输入,并在内部字典中查找这些整数,然后返回相关联的向量。
Embedding 层实 际上是一种字典查找:
单词索引 –> Embedding层 –> 对应的词向量
Embedding 层的输入是一个二维整数张量,其形状为 (samples, sequence_length), 每个元素是一个整数序列。
它能够嵌入长度可变的序列,例如,对于前一个例子中的 Embedding 层,你可以输入形状为 (32, 10)(32 个长度为 10 的序列组成的批量)或 (64, 15)(64 个长度为 15 的序列组成的批量)的批量。不过一批数据中的所有序列必须具有相同的长度(因为需要将它们打包成一个张量),所以较短的序列应该用 0 填充,较长的序列应该被截断。
这个 Embedding 层返回一个形状为 (samples, sequence_length, embedding_ dimensionality) 的三维浮点数张量。然后可以用RNN层或一维卷积层来处理这个三维张量。
将一个 Embedding 层实例化时,它的权重(即标记向量的内部字典)最开始是随机的, 其他层一样。在训练过程中,利用反向传播来逐渐调节这些词向量,改变空间结构以便下游模 型可以利用。一旦训练完成,嵌入空间将会展示大量结构,这种结构专门针对训练模型所要解决的问题。
注意:embedding层实例化、输入和输出的区别
我们将这个想法应用于IMDB 电影评论情感预测任务。首先,我们需要快速准备数据。将电影评论限制为前 10 000 个最常见的单词, 然后将评论长度限制为只有 20 个单词。对于这 10 000 个单词,网络将对每个词都学习一个 8 维嵌入,将输入的整数序列(二维整数张量)转换为嵌入序列(三维浮点数张量),然后将这个 张量展平为二维,最后在上面训练一个 Dense 层用于分类。
1 | from keras.datasets import imdb |
得到的验证精度约为 76%,考虑到仅查看每条评论的前 20 个单词,这个结果还是相当不错的。但请注意,仅仅将嵌入序列展开并在上面训练一个 Dense 层,会导致模型对输入序列中的每个单词单独处理,而没有考虑单词之间的关系和句子结构(举个例子,这个模型可能会将 this movie is a bomb 和 this movie is the bomb 两条都归为负面评论 a)。更好的做法是在嵌入序列上添加循环层或一维卷积层,将每个序列作为整体来学习特征。
使用预训练的词嵌入
有时可用的训练数据很少,以至于只用手头数据无法学习适合特定任务的词嵌入。那么应该怎么办?
你可以从预计算的嵌入空间中加载嵌入向量(你知道这个嵌入空间是高度结构化的,并且具有有用的属性,即抓住了语言结构的一般特点),而不是在解决问题的同时学习词嵌入。
在自然语言处理中使用预训练的词嵌入,其背后的原理与在图像分类中使用预训练的卷积神经网络是一样的:没有足够的数据来自己学习真正强大的特征,但你需要的特征应该是非常通用的, 比如常见的视觉特征或语义特征。
在这种情况下,重复使用在其他问题上学到的特征,这种做法是有道理的。 这种词嵌入通常是利用词频统计计算得出的(观察哪些词共同出现在句子或文档中),用到的技术很多,有些涉及神经网络,有些则不涉及。Bengio 等人在 21 世纪初首先研究了一种思路, 就是用无监督的方法计算一个密集的低维词嵌入空间 a,但直到最有名且最成功的词嵌入方案之一word2vec算法发布之后,这一思路才开始在研究领域和工业应用中取得成功。
word2vec算法 由 Google 的 Tomas Mikolov于 2013 年开发,其维度抓住了特定的语义属性,比如性别。 有许多预计算的词嵌入数据库,你都可以下载并在Keras的 Embedding 层中使用。 word2vec 就是其中之一。另一个常用的是 GloVe(global vectors for word representation,词表示全局向量),由斯坦福大学的研究人员于 2014 年开发。这种嵌入方法基于对词共现统计矩阵进行因式分解。其开发者已经公开了数百万个英文标记的预计算嵌入,它们都是从维基百科数据 和 Common Crawl 数据得到的。
我们来看一下如何在Keras模型中使用GloVe嵌入。同样的方法也适用于word2vec 嵌入或 其他词嵌入数据库。这个例子还可以改进前面刚刚介绍过的文本分词技术,即从原始文本开始, 一步步进行处理。
下载链接:http://mng.bz/0tIo,下载原始
IMDB 数据集并解压1 | import os |
利用本节前面介绍过的概念,我们对文本进行分词,并将其划分为训练集和验证集。因为预训练的词嵌入对训练数据很少的问题特别有用(否则,针对于具体任务的嵌入可能效果更好), 所以我们又添加了以下限制:将训练数据限定为前 200 个样本。因此,你需要在读取 200 个样本之后学习对电影评论进行分类。
1 | import os |
补充:pad_sequences()有什么用
pad_sequences(sequences, maxlen=None)
maxlen设置最大的序列长度,长于该长度的序列将会截短,短于该长度的序列将会填充
打开 https://nlp.stanford.edu/projects/glove,下载 2014 年英文维基百科的预计算嵌入。这是一个 822 MB 的压缩文件,文件名是 glove.6B.zip,里面包含 400 000 个单词(或非单词的标记) 的 100 维嵌入向量。(官网下载不了可以找百度云链接),解压文件。
对解压后的文件(一个.txt文件)进行解析,构建一个将单词(字符串)映射为其向量表示的索引
1 | glove_dir = 'D:/python_project/深度学习/keras_t/samples/glove.6B' |
接下来,需要构建一个可以加载到 Embedding 层中的嵌入矩阵。它必须是一个形状为 (max_words, embedding_dim) 的矩阵,对于单词索引(在分词时构建)中索引为 i 的单词, 这个矩阵的元素 i 就是这个单词对应的 embedding_dim 维向量。注意,索引 0 不应该代表任何单词或标记,它只是一个占位符。
1 | embedding_dim = 100 |
1 | model = Sequential() |
1 | model.layers[0].set_weights([embeddings_matrix]) |
1 | model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc']) |
模型很快就开始过拟合,考虑到训练样本很少,这一点也不奇怪。出于同样的原因,验证精度的波动很大,但似乎达到了接近 60%。
因为这里的图像波动比较较大就不展示了
注意,你的结果可能会有所不同。训练样本数太少,所以模型性能严重依赖于你选择的 200 个样本,而样本是随机选择的。如果你得到的结果很差,可以尝试重新选择 200 个不同的 随机样本,你可以将其作为练习(在现实生活中无法选择自己的训练数据)。
你也可以在不加载预训练词嵌入、也不冻结嵌入层的情况下训练相同的模型。在这种情况下, 你将会学到针对任务的输入标记的嵌入。如果有大量的可用数据,这种方法通常比预训练词嵌入更加强大,但本例只有 200 个训练样本。
我们来试一下这种方法:其实只要把下面这两行代码注释掉就可以了
1 | # 在模型中加入Glove嵌入 |
验证精度停留在 50% 多一点。因此,在本例中,预训练词嵌入的性能要优于与任务一起学 习的嵌入。如果增加样本数量,情况将很快发生变化,你可以把它作为一个练习。
首先,你需要对测试数据进行分词,方法和流程和前面训练集的分词是一致的,所以其实这里可以封装成一个方法,分别调用生成训练集和测试集。
1 | test_dir = os.path.join(imdb_dir, 'test') |
1 | model.load_weights('pre_trained_glove_mode.h5') |
测试精度达到了令人震惊的 56% !只用了很少的训练样本,得到这样的结果很不容易。
总结
这里讲了以下内容:
- 将原始文本转换为神经网络能够处理的格式。
- 使用
Keras模型的 Embedding 层来学习针对特定任务的标记嵌入。 - 使用预训练词嵌入在小型自然语言处理问题上获得额外的性能提升。