KNN分类算法
KNN是机器学习种最简单的分类算法,而图像分类也是图像识别种最简单的问题,所以这里使用KNN来做图像分类,帮忙大家初步了解图像识别算法。
KNN(K-NearestNeighbor),即K-最近邻算法,顾名思义,找到最近的k个邻居,在前k个最近样本(k近邻)中选择最近的占比最高的类别作为预测类别。
KNN算法的计算逻辑:
- 给定测试对象,计算它与训练集中每个对象的距离;
- 圈定距离最近的k个训练对象,作为测试对象的邻居;
- 根据这k个近邻对象所属的类别,找到占比最高的那个类别作为测试对象的预测类别。
在KNN中,有两个方面的因素会影响KNN算法的准确度:一个是距离计算,另一个是k的选择。
一般使用两种比较常见的距离公式计算距离:
- 曼哈顿距离:
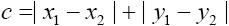
- 欧式距离:
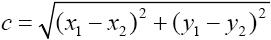
KNN算法实现
1 | import numpy as np |
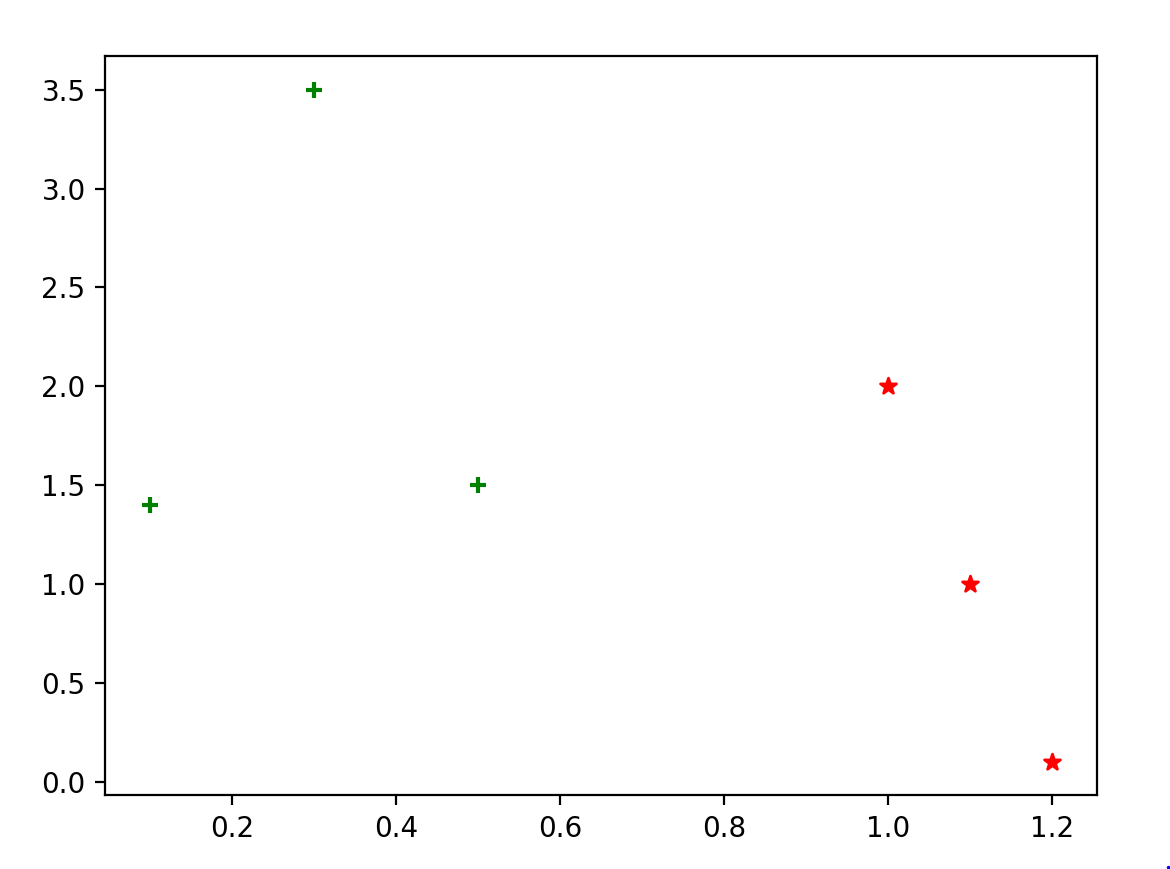
我们先创建一个简单的数据集,然后使用Matplotlib绘制图形,可以直观看到地查看数据分布情况。
接下来实现KNN算法
1 | import operator |
最后测试下KNN算法的效果:
1 | # 使用曼哈顿距离和欧式距离得到的预测结果不一样 E: ['A', 'B'] M: ['A', 'A'] |
注意,输入测试集的时候,需要将其转换为Numpy矩阵,否则系统会提示传入的参数是list类型,没有shape的方法。
KNN实现MNIST数据分类
下载和准备数据集
MNIST数据集是手写数字的图片数据集,MNIST可以直接通过pytorch进行下载与读取(也可以自行下载,然后放到相关目录,使用pytorch解析)
1 | import torch |
首次运行代码会自动下载数据到目录/ml_dataset/pymnist,如果运行时速度过慢,可以上网查询MNIST下载方式,将下载好的数据包,放置该目录,程序会自动解析。
train_dataset与test_dataset可以返回训练集数据、训练集标签、测试集数据以及测试集标签,训练集数据以及测试集数据都是n×m维的矩阵,这里的n是样本数(行数),m是特征数(列数)。训练数据集包含60 000个样本,测试数据集包含10 000个样本。
在MNIST数据集中,每张图片均由28×28个像素点构成,每个像素点使用一个灰度值表示。在这里,我们将28×28的像素展开为一个一维的行向量,这些行向量就是图片数组里的行(每行784个值,或者说每行就代表了一张图片)。训练集标签以及测试标签包含了相应的目标变量,也就是手写数字的类标签(整数0~9)。
上面代码打印的结果为:
1 | train_data: torch.Size([60000, 28, 28]) |
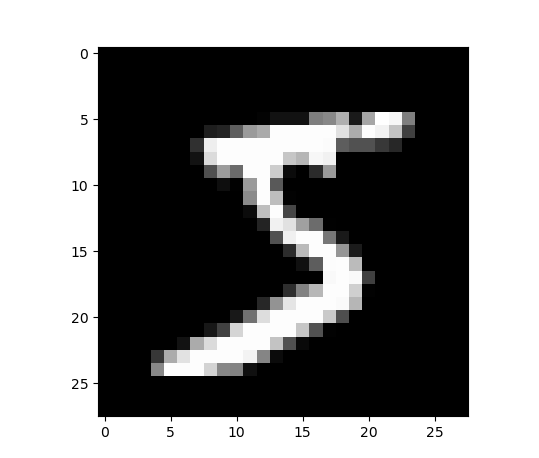
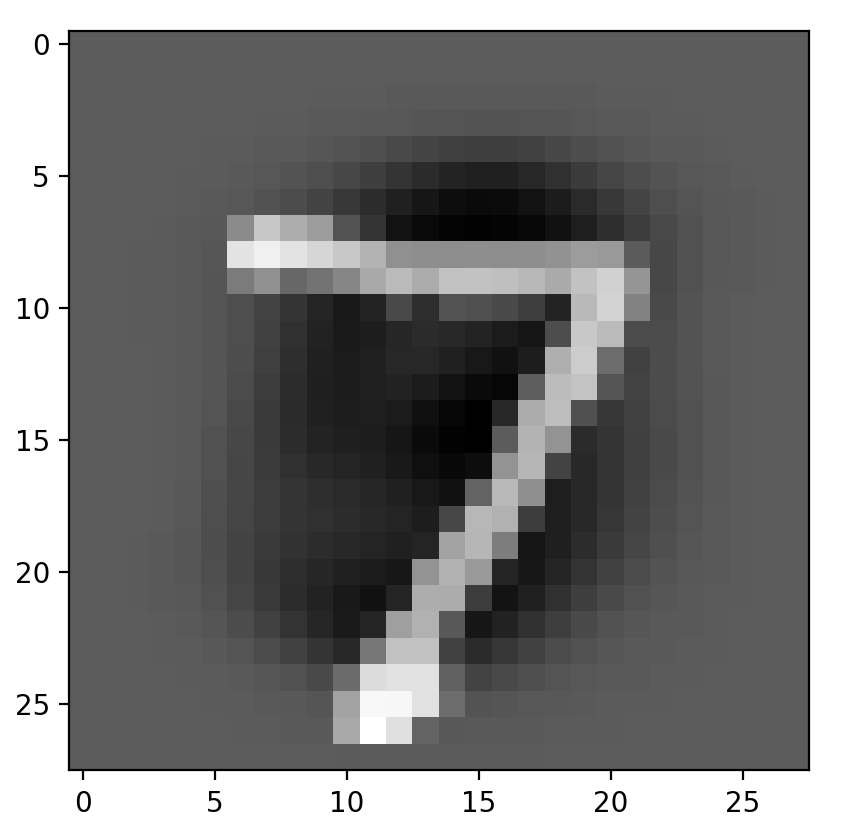
如果大家对这个数据集不是很了解,可以尝试多去显示几张图片看下,并查看相应的标签。
例如:
1 | # 查看mnist数据集的图像是啥样的 |
数字5:
原理剖析
在真正使用Python实现KNN算法之前,我们先来剖析一下思想,这里我们以MNIST的60 000张图片作为训练集,我们希望对测试数据集的10 000张图片全部打上标签。KNN算法将会比较测试图片与训练集中每一张图片,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
那么,具体应该如何比较这两张图片呢?在本例中,比较图片就是比较28×28的像素块。最简单的方法就是逐个像素进行比较,最后将差异值全部加起来
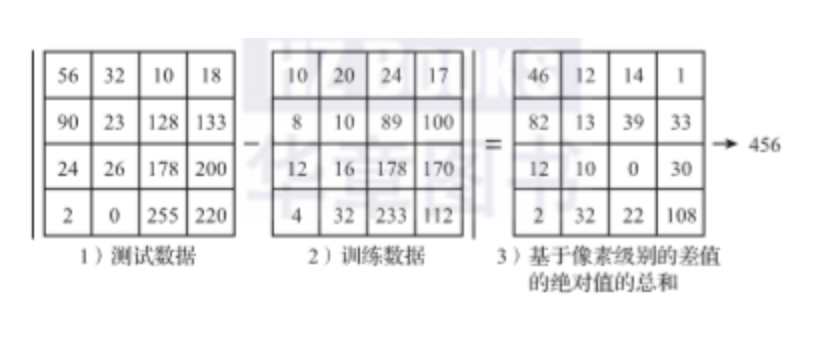
两张图片使用L1距离(曼哈顿距离,相应的L2距离是欧式距离)来进行比较。逐个像素求差值,然后将所有差值加起来得到一个数值。如果两张图片一模一样,那么L1距离为0,但是如果两张图片差别很大,那么,L1的值将会非常大。
验证KNN在MNIST上的效果
我们直接利用上面实现的KNN算法来测试:
1 | from KNN import KNNClassify |
这里需要多说点,上面的KNN算法实现,我是当作一个单独的脚本,这里的MNIST数据分类,是另一个脚本,且位于同一文件夹下:
直接在MNIST.py脚本中使用from KNN import KNNClassify可能会出错,需要在__init__.py中添加一行代码:from .KNN import KNNClassify。
最后运行代码,Got 368 / 1000 correct => accuracy: 0.368000!这说明1000张图片中有368张图片预测类别的结果是准确的。
先别气馁,我们之前不是刚说过可以使用数据预处理的技术吗?下面我们试一下如果在进行数据加载的时候尝试使用归一化,那么分类准确度是否会提高呢?
我们稍微修改下代码,主要是在将X_train和X_test放入KNN分类器之前先调用centralized,进行归一化处理。
1 | class MNIST: |
下面再来看下输出结果的准确率:Got 951 / 1000 correct => accuracy: 0.951000,95%算是不错的结果。
现在我们来看一看归一化后的图像是什么样子的
1 | class MNIST: |
所以是否了解到数据预处理的重要性了?!未进行数据预处理的准确率只有36.8%,进行归一化数据预处理后,准确率提升至95%!
在开始使用算法进行图像识别之前,良好的数据预处理能够很快达到事半功倍的效果。图像预处理不仅可以使得原始图像符合某种既定规则以便于进行后续的处理,而且可以帮助去除图像中的噪声。
在后续讲解神经网络的时候我们还会了解到,数据预处理还可以帮助减少后续的运算量以及加速收敛。常用的图像预处理操作包括归一化、灰度变换、滤波变换以及各种形态学变换等。
归一化可用于保证所有维度上的数据都在一个变化幅度上。比如,在预测房价的例子中,假设房价由面积s和卧室数b决定,面积s在0~200之间,卧室数b在0~5之间,进行归一化的一个实例就是s=s/200,b=b/5。
KNN实现Cifar10数据分类
Cifar10是一个由彩色图像组成的分类的数据集(MNIST是黑白数据集),其中包含了飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车10个类别,且每个类中包含了1000张图片。整个数据集中包含了60 000张32×32的彩***片。该数据集被分成50 000和10 000两部分,50 000是training set,用来做训练;10 000是test set,用来做验证。
下载和准备数据集
同样的你可以通过Pytorch直接下载该数据集,或者自己从数据集官网下载,然后放置指定目录,程序会自动解析
1 | import torch |
如果对数据集不了解,可以查看数据集的图片内容
1 | class Cifar10 |
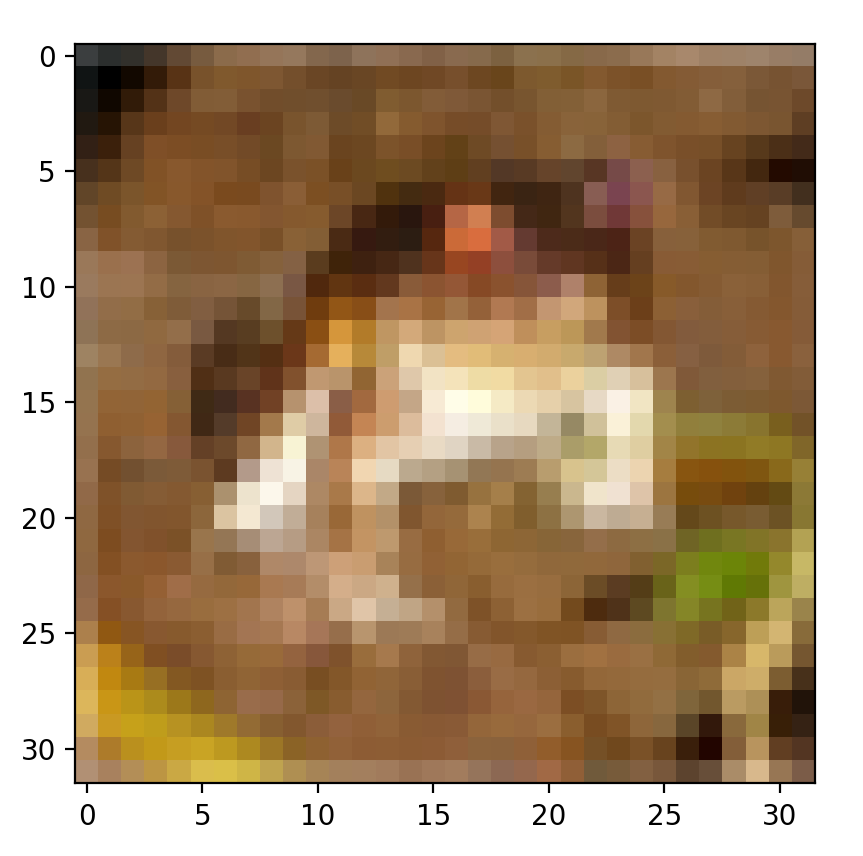
classes是我们定义的类别,其对应的是Cifar中的10个类别。使用PyTorch读取的类别是index,所以我们还需要额外定义一个classes来指向具体的类别。由于只有32×32个像素,因此图像比较模糊。
验证KNN在Cifar10上的效果
现在我们主要观察下KNN对于Cifar10数据集的分类效果,与之前MNIST数据集不同的是,X_train = train_loader.dataset.train_data,X_train的dtype是uint8而不是torch.uint8,所以不需要使用numpy()这个方法进行转换。
1 | class Cifar10: |
经过验证,KNN算法在Cifar10数据集上的准确率不高,大概只有30%的准确率,而且是在归一化处理的基础上。
总结
前面我们讲了影响KNN算法的两大因素分别为距离度量算法和K的取值,也就是算法的两个超参数,到底如何选取这两个值,就是一个模型调参的问题,这个过程一般就是需要你自己去测试,选取一个效果比较好的取值。
虽然KNN在MNIST数据集中的表现还算可以(主要原因可能是MNIST是灰度图),但是其在Cifar10数据集上的分类准确度就差强人意了。另外,虽然KNN算法的训练不需要花费时间(训练过程只是将训练集数据存储起来),但由于每个测试图像需要与所存储的全部训练图像进行比较,因此测试需要花费大量时间,这显然是一个很大的缺点,因为在实际应用中,我们对测试效率的关注要远远高于训练效率。
在实际的图像分类中基本上是不会使用KNN算法的。因为图像都是高维度数据(它们通常包含很多像素),这些高维数据想要表达的主要是语义信息,而不是某个具体像素间的距离差值(在图像中,具体某个像素的值和差值基本上并不会包含有用的信息),所以这就是我们为什么需要用深度学习和神经网络来训练模型提高准确率和检测速度。