PyTorch实现卷积神经网络
关于卷积神经网络的一些基础知识和概念等前面已经多次学习,这篇文章的重点是Pytorch来实现卷积神经网络,偏向于代码实践,理论知识不多,不过有一点关于图像经过卷积后的输出尺寸问题的公式我觉得不错,值得记录。
卷积层
我们知道卷积的过程是:让卷积核在图片上依次进行滑动,滑动方向为从左到右,从上到下,每滑动一次,卷积核就与其滑窗位置对应的输入图片x做一次点击运算并得到一个数值。在卷积的过程中,一般情况下,图片的宽高会变得越来越小,而通道数会变得越来越多。这里尺寸改变有什么样的规律呢?
输入1*7的向量,经过1*3的卷积,如果步长为2,最终得到一个1*5的向量;如果步长为2,最终得到一个1*3的向量
输入7*7的向量,经过3*3的卷积,如果步长为1,最终得到一个5*5的向量;如果步长为2,最终得到一个3*3的向量;如果步长为3,会报错
上面的例子卷积核个数都是1且通道数也是1,下面考虑多个卷积核的情况
输入32*32*3的图片,如果kernel大小为5*5*3(实际上大小就是5*5,后面的3只是为了表示针对3通道图片的一种写法,卷积核会对三个通道分别实行5*5卷积,然后加到一起),单个卷积核和步长为1的情况下,最终得到一个28*28*1的新图片;如果我们连续堆叠6个不同的卷积,最终特征层将得到6个通道,即28*28*6的新图片。
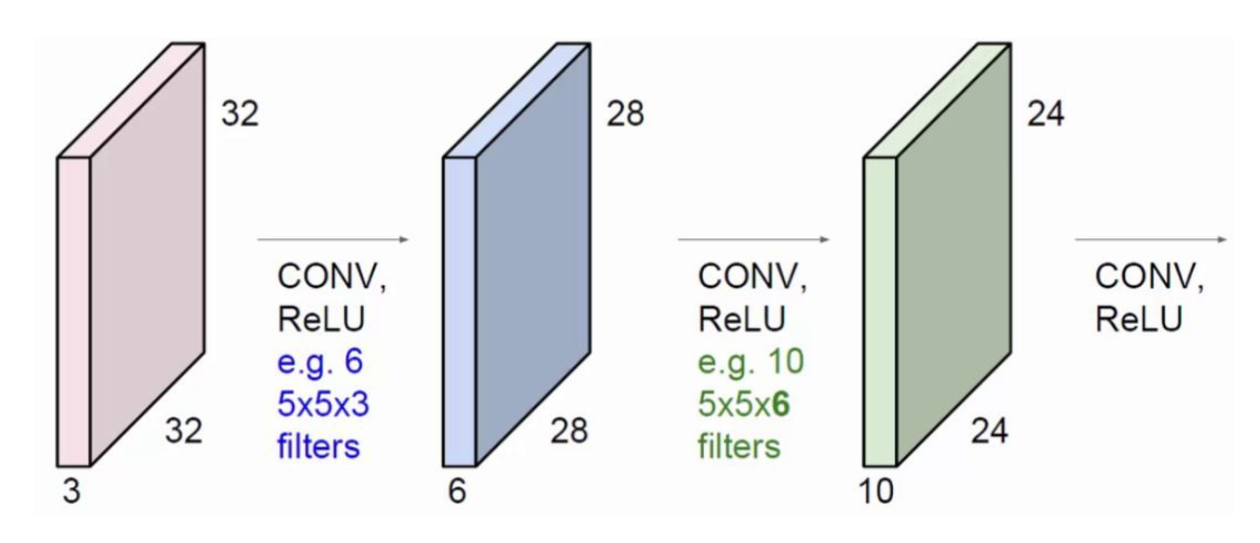
,在7*7的输入图片周边做一个像素的填充(pad=1,周边填充是上下左右都会填充),如果步长为1,kernel为3*3的卷积输出的特征层为7*7。
所以可以总结出一种通用的卷积层计算公式:输入图片为W1*H1*D1(字母分别表示图像的宽、高、channel),卷积层的参数中kernel大小为F*F,步长为S,pad大小为P,kernel个数为K,那么经过卷积后,输出图像的宽、高、channel分别为:
1 | W2 = (W1-F+2P)/S + 1 |
其实关于这个计算公式倒是不用刻意的去记忆,理解了卷积的原理,那么关于卷积后的图片尺寸大小,很容易就能得出,完全用不到公式。
PyTorch中的卷积函数代码:
1 | import torch.nn as nn |
参数说明
- in_channels(int):输入图片的channel
- out_channels(int):输出图片(特征层)的channel
- kernel_size(int or tuple):kernel的大小
- stride(int or tuple, optional):卷积的步长,默认为1
- padding(int or tuple, optional):四周pad的大小,默认为0
- dilation(int or tuple, optional):kernel元素间的距离,默认为1
- groups(int, optional):将原始输入channel划分成的组数,默认为1
- bias(
bool, optional):如果是True,则输出的Bias可学,默认为True
因为输出图片的通道数等于卷积核的个数,所以这里的out_channels参数可以理解为卷积核个数。
池化层
池化是对图片进行压缩(降采样)的一种方法,池化的方法有很多,如max pooling、average pooling等。池化层也有操作参数,我们假设输入图像为W1*H1*D1(字母分别表示图像的宽、高、channel),池化层的参数中,池化kernel的大小为F*F,步长为S,那么经过池化后输出的图像宽、高、channel分别为:
1 | W2 = (W1 - F)/S + 1 |
通常情况下,F=2,S=2。
一个4*4的特征层经过池化filter=2*2,stride=2的最大池化操作后可以得到一个2*2的特征层。
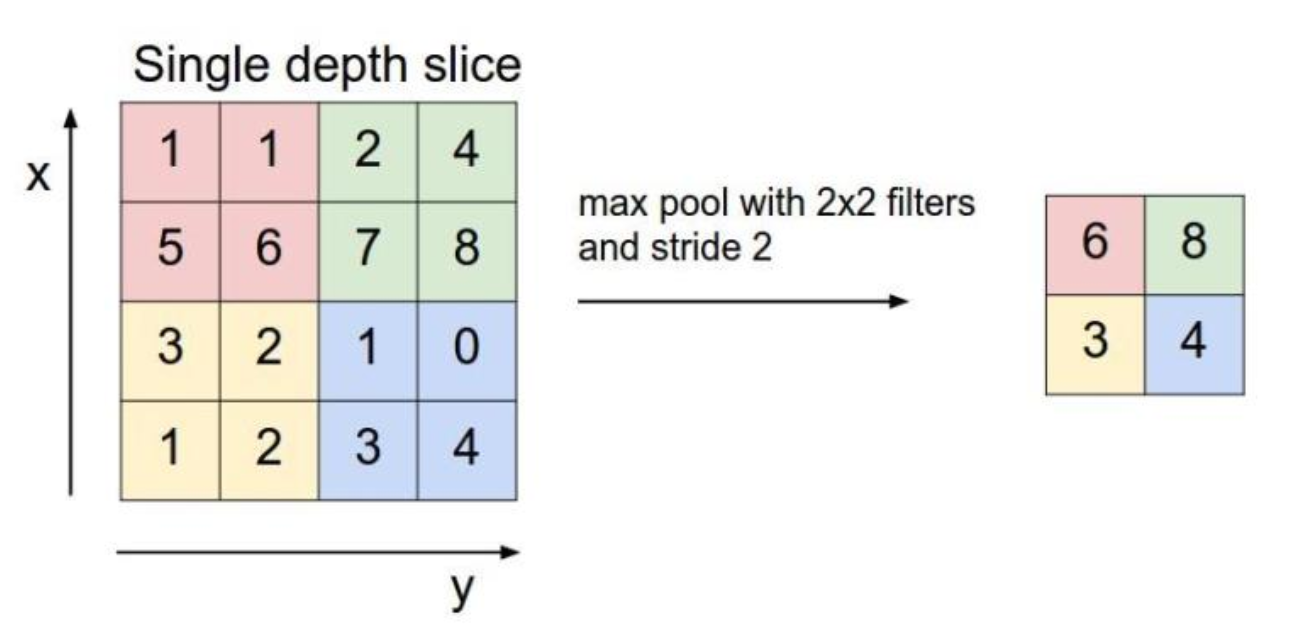
池化层对原始特征层的信息进行压缩,卷积层、池化层、激活层很多时候三者几乎像一个整体一样同时出现。
Pytorch定义卷积神经网络的代码(初版)
1 | import torch.nn as nn |
批规范化层(BatchNorm层,BN层)
批规范化层主要是为了加速神经网络的收敛过程以及提高训练过程中的稳定性。
batch的概念就是在使用卷积神经网络处理图像数据时,往往是几张图片(如32张、64张、128张等)被同时输入到神经网络中一起进行前向计算,误差也是将该batch中所有图片的误差累计起来一起回传。
BatchNorm方法其实就是对一个batch和中的数据根据公式做了归一化。
VGGNet
下面我们借助比较比较常见的VGG网络架构来进行了解Pytorch是如何实现卷积神经网络的。
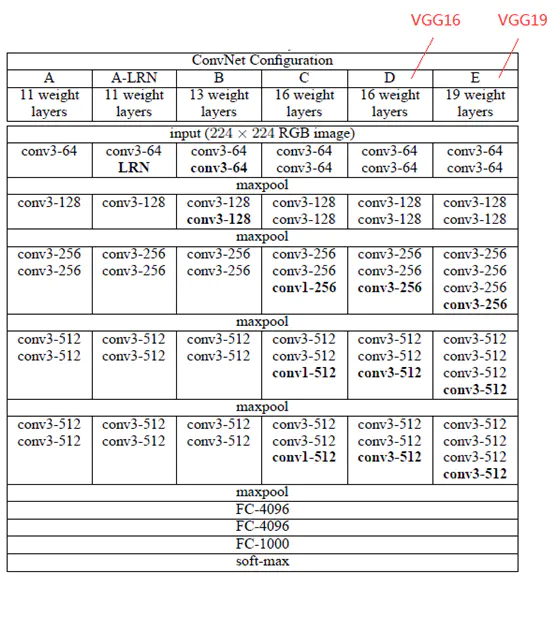
VGGNet包含两种结构,分别为16层和19层,VGG16包含了16个隐藏层(13个卷积层+3个全连接层),如图中的D列所示;VGG19包含了19个隐藏层(16个卷积层+3个全连接层),如图中的E列所示。
VGGNet结构中,所有的卷积层的kernel都只有3*3;其连续使用3组3*3 kernel(stride=1)的原因是它与使用1个7*7 kernel产生的效果相同,然而更深的网络结构还会学习到更复杂的非线性关系,从而使得模型的效果更好。
该操作带来的另一个好处是参数数量的减少,因为对于一个包含了C个kernel的卷积层来说,原来的参数个数为7*7*C,而新的参数个数为3*(3*3*C)。
VGG16的立体的网络结构图:(此部分内容参考文章:https://blog.csdn.net/weixin_38132153/article/details/107616764)
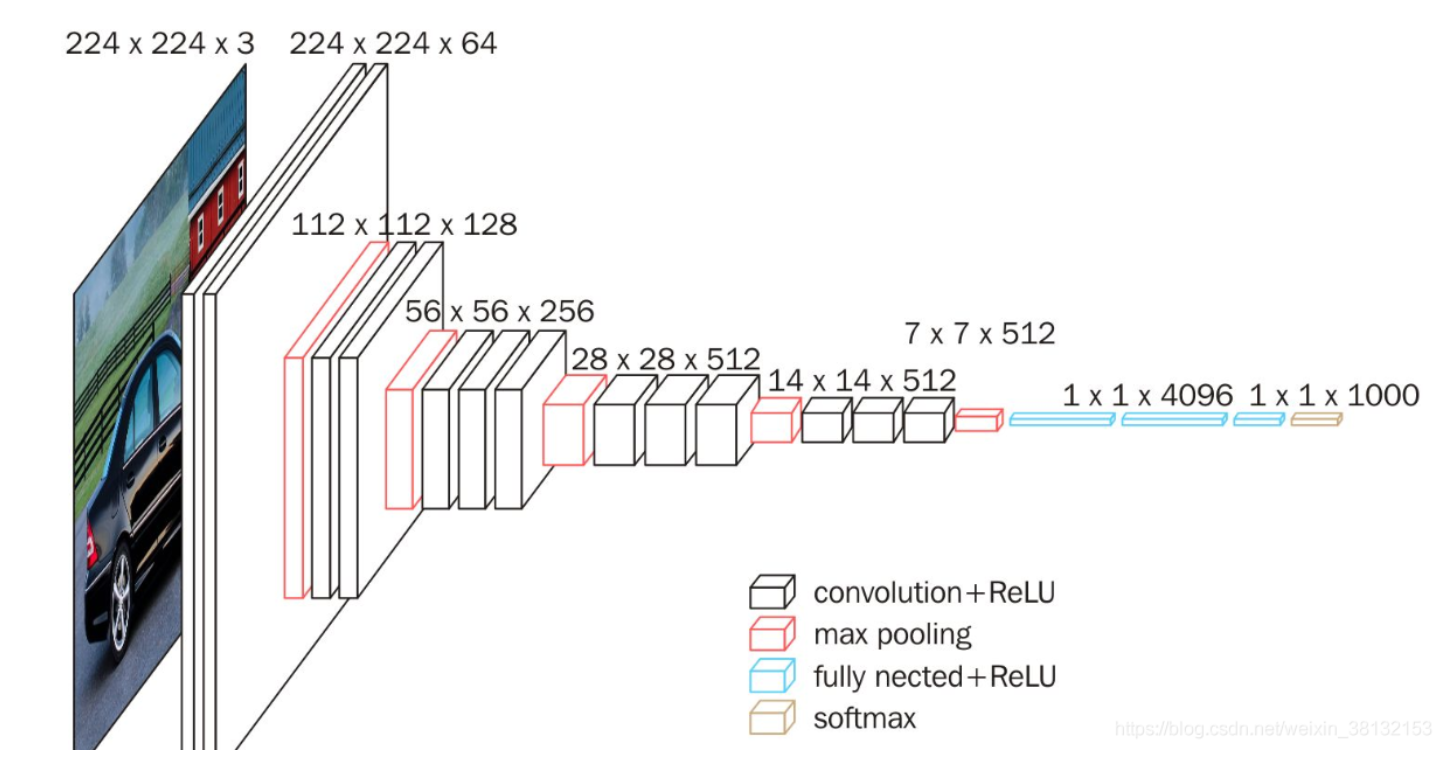
根据VGG16的网络结构,我们使用Pyotrch来个初步实现一下
1 | import torch |
这里特别需要注意的一点就是,全连接层的输入值(in_features),上面给出的网络结构图的尺寸值前提是在输入图片大小为3*224*224,所以经过全部卷积层后得到512*7*7的特征图,如果输入尺寸有变,那么全连接层的输入值是要自己改变的。
上面编写的初步版本我们很容易读懂是如何一步步实现的,但是经过观察思考我们可以发现,卷积部分代码存在许多重复的地方,如果我们可以编写一个方法,通过传入参数,自动实现卷积部分就好了。
1 | 可以通过初始化参数指定生成VGG16 or VGG19网络模型 |
经过对VGGNet的学习,我们可以发现这些所谓的神经网络架构模型,其实就是卷积层+激活+池化等的组合,不同的就是要使用多少层卷积,每层卷积的卷积核数量、大小、步长等的区别,针对一些特定的数据集,如果你能设计出一个网络模型以更快的速度达到现有的更高的精度,那你就是开创者。
VGG16实现Cifar10分类
如果要把VGG16应用于Cifar10分类任务,那么上面提到的输入到全连接层的in_features需要修改,因为Cifar10的图片尺寸是3*32*32,经过全部卷积层后变成了1*1*512。
1 | # 全连接层 |
1 | # 训练(速度特别慢,5轮跑了十几个小时, 准确率76%,5轮后的损失还挺大的,其实还可以继续跑) |
这里介绍了保存训练模型和加载训练模型的方式。
使用VGG16模型训练速度较慢,因为网络结构较深;Cifar10的图片比较小,我尝试用了一个更简单的模型,达到的准确率与VGG16训练5轮的准确率差不多。
1 | class CNN(nn.Module): |