CRNN
参考文章:https://xiaobaibubai.blog.csdn.net/article/details/115862743
GitHub项目:https://github.com/meijieru/crnn.pytorch
预训练模型下载地址:https://pan.baidu.com/s/1pLbeCND
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
该算法出自An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Secene Text Recognition,这篇文章来自华中科技大学白翔团队,并在2017年被人工智能顶级期刊《TPAMI》收录。
CRNN网络架构示意图
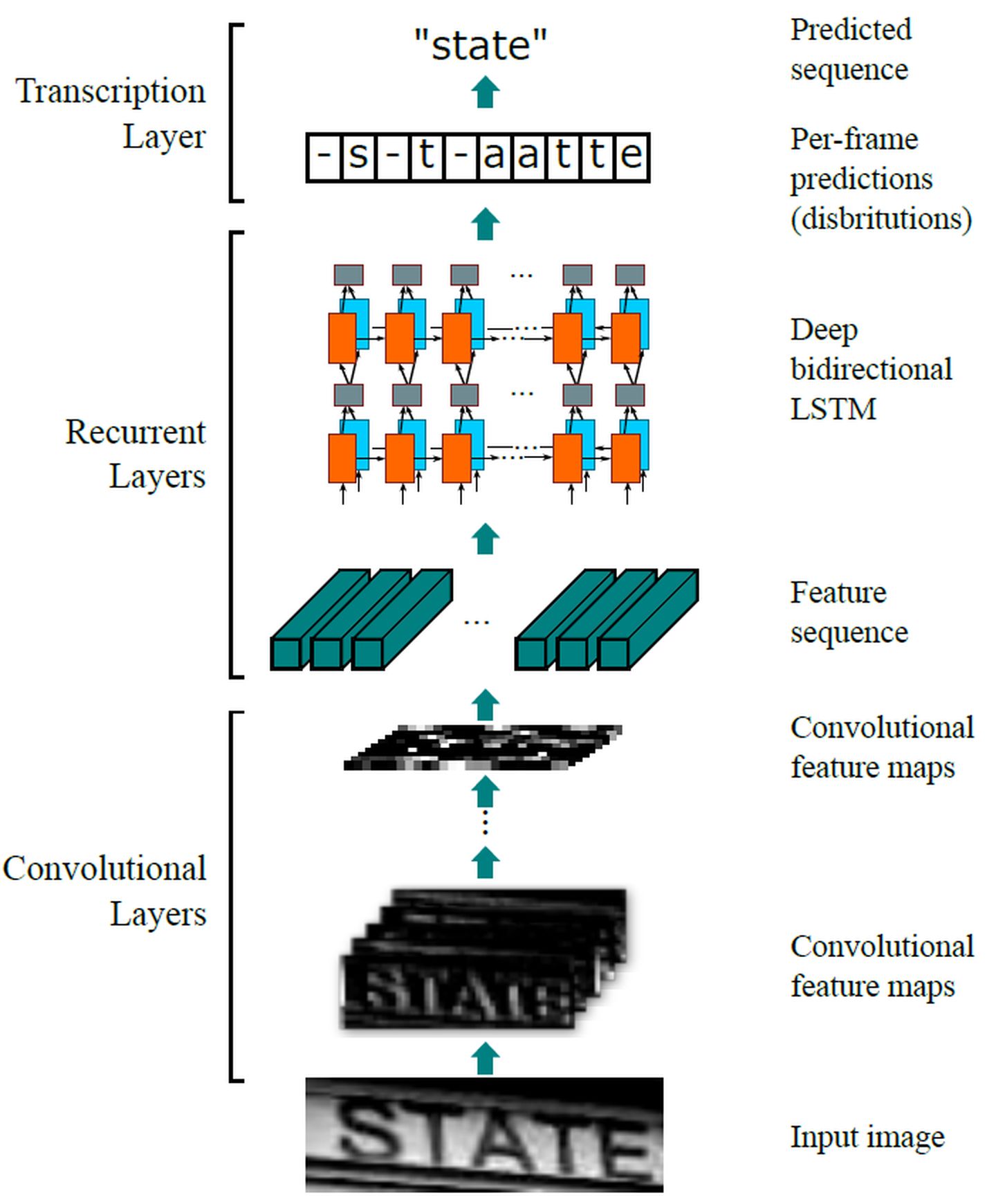
CRNN模型主要分为两个部分:一部分为特征提取,由多个卷积层、池化和非线性层组成;另一部分为序列预测,由RNN+CTC模型组成。RNN部分主要用于学习和建模CNN中提取到的隐藏状态以及空间特征之间的联系,最后预测初步的序列结果。粗糙的预测序列可能存在字母重复的情况,通过CTC模块对RNN的序列进行整合,可以对序列进行去重操作。
CRNN接收灰度图或RGB彩色图作为输入,CNN作为编码器来提取与图片中对应的中间层特征。经过变形后整理成T个时间步的输入送入随后的解码器RNN,从而预测出初步的序列。初步的序列经过CTC整流处理,去除冗余的字符后得到最终的预测结果。
CRNN参数设置
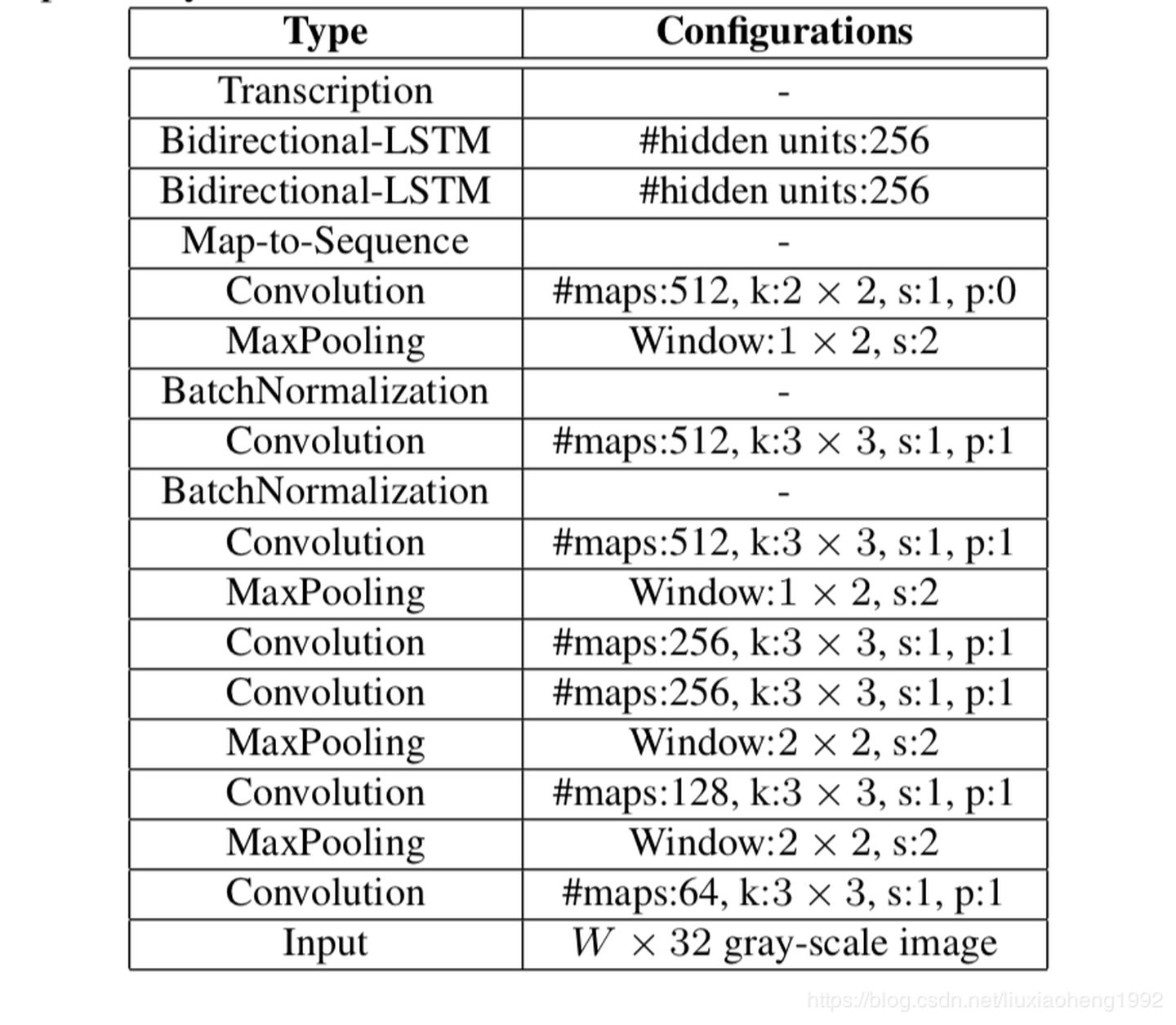
这里的结构主要借鉴VGG结构,但是做了一些调整;有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(变为原来的1/16),而宽度则只减半了两次(变为原来的1/4),这是因为文本图像多数都是高较小而宽较长,所以其feature map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN 后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height, width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 39)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为39。
注意:最后的卷积层是一个2*2,s=1,p=0(无填充)的卷积,这样会将feature map的高和宽分别减少1,所以当输入的h是32时,最后CNN输出的featuremap的高度为1(32四次除以2得到2,然后再减去1)。(但是并不是整个CNN层将图像的h放缩为原来的1/32,有很多资料这里都说是1/32,我觉得并不准确,比如当h为64时,得到的结果为3,虽然这里是限制了输入为32,但是也可以更改限制)。
同理,初始宽度160经过两次最大池化,变为40,然后经过最后一层卷积后,宽度减少1,最后变成39。
CRNN模型的实现
1 | from torch import nn |
(这里重点介绍关于CNN模块的实现,RNN模块也就是双向LSTM略过了,后面会有文章着重介绍)
重点代码解释:
- 最后两层池化:
nn.MaxPool2d(kernel_size=(2, 1), stride=(2, 1), padding=(0, 0))
h高度方向,kernel_size=2,stride=2,会使得h减小一半,w宽度方向,kernel_size=1,stride=1,w不变。
squeeze(axis = None)1
2
3
4
51)a表示输入的数组;
2)axis用于指定需要删除的维度,但是指定的维度必须为单维度,否则将会报错;
3)axis的取值可为None 或 int 或 tuple of ints, 可选。若axis为空,则删除所有单维度的条目;
4)返回值:数组
5) 不会修改原数组;permute(),将tensor的维度换位(改变维度排列)
参数:参数是一系列的整数,代表原来张量的维度。比如三维就有0,1,2这些dimension
利用pytorch实现完成该模型后,下载预训练模型crnn.pth然后进行测试,却遇到了报错:
1 | RuntimeError: Error(s) in loading state_dict for CRNN: |
通过代码分析,我们上面的模型代码创建的批规范化层分别为:”batchnorm4”、”batchnorm5”;这里报出的问题是,加载的预训练模型中没有”batchnorm5”层,然后预训练模型中”batchnorm2”和”batchnorm6”层,我们的模型中也没有,所以加载失败了。
这里就与github项目里的模型代码对应上了,一开始看了项目中给出的代码,总感觉与模型有点出入,实际上可能是为了与预训练模型对应上,这里具体的原因是啥我也无法搞清楚。(究竟是预训练生成的模型本身就写错了,还是进行了一些改进。)
改动点:改变batch_norm层的位置和次数,即在第2、4、6层后面分别添加批规范化层:
1 | conv_relu(2, True) |
这样更改完成之后,运行demo(预测demo.png)
1 | # -*- coding: utf-8 -*- |
(这里一些引用的辅助方法都没写,具体要看GitHub源代码)
预测结果有点小问题,预测得到的结果为:
—–v——–a-b–l-e– vable
而实际结果为variable,所以肯定是哪里实现不对,经过仔细研究发现关于后两层的最大池化实现方式与GitHub源代码不一样,这部分还在上面重点介绍了,理论上我的实现方式与论文中是一致的,而GitHub源代码中是这样实现的:
1 | cnn.add_module('pooling{0}'.format(2), |
MaxPool2d方法的前三个参数分别是kernel_size、stride、padding,这里把kernel_size设置为(2, 2)就与论文不符,但是仔细观察,发现实现的功能是一样的,即高度减半,宽度不变。我认为按照我的写法训练一个模型应该也是没问题的,只不过为了能和这个预训练模型的权重文件保持一致,就采用这一种池化写法,果然经过这样的调整后就正确的预测了结果。
文字识别
文字识别属于OCR技术范畴,CNN+RNN+CTC是目前比较流行的识别模型,所以去学习了一下,在这里记录了一下,而且按照开头给出的GitHub项目,又从头到尾抄了一遍,研究了下部分代码的含义,但是因为缺乏足够的数据集,暂时还没有开始训练。
假设2500个文字,每张图片4个字,按照每个文字有100个样本需要250000个样本,也就是62500张图片,这基本是一个最低限度的数据量了,因为文字一般结构复杂,100个样本可能远不够,如果500个样本的话,那就是需要约30万张图片。