Seq2Seq
encoder & decoder
Seq2Seq结构用于多个输入和多个输出的模型,但是输入和输出的大小可能并不一致,其本质上也是RNN网络的一个扩展,常见的应用场景包括:机器翻译、语音识别、文本摘要等。
常见的seq2seq的输出的计算方法包括以下两种:
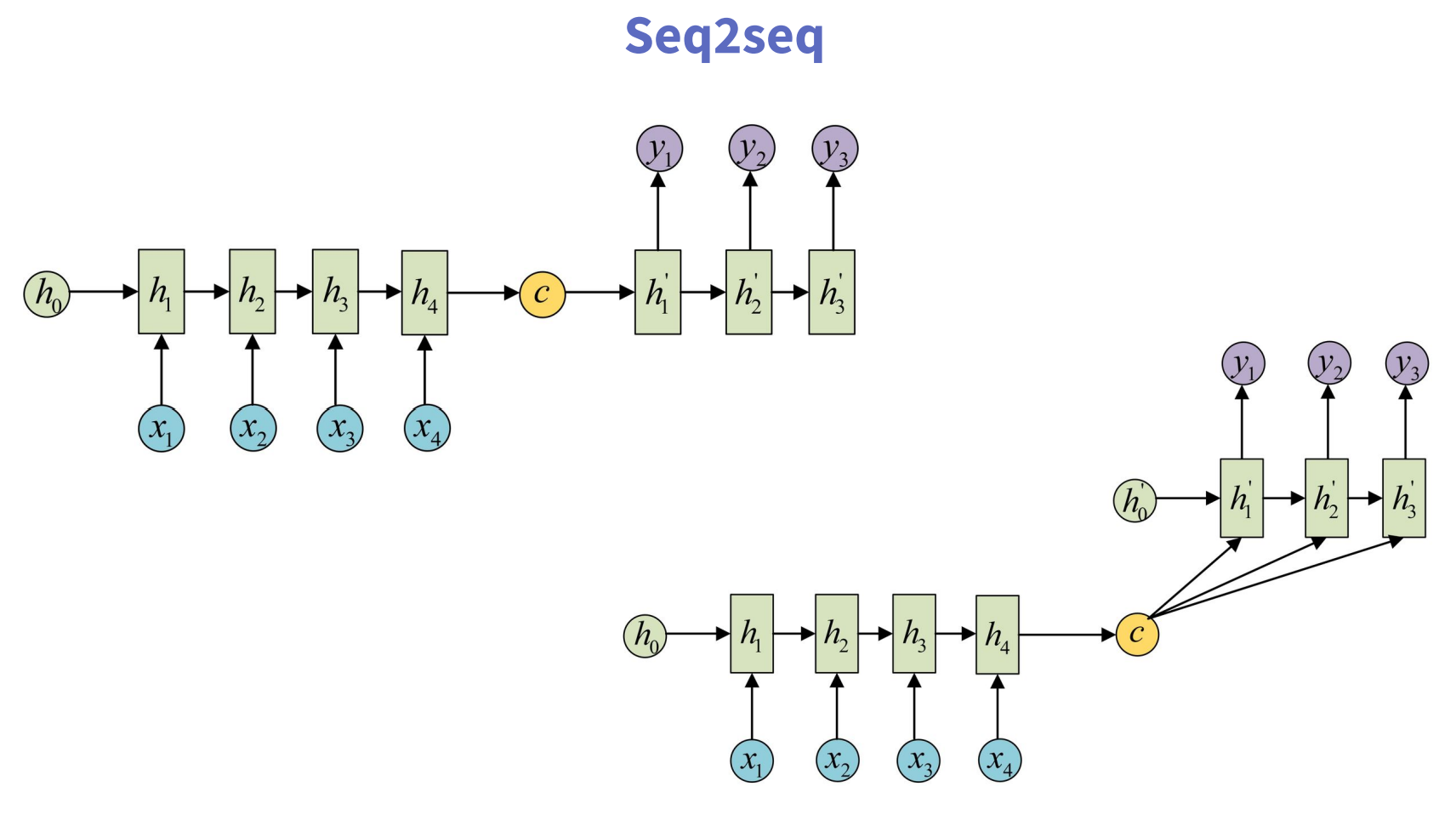
注意这里C到y1、y2、y3的计算,虽然有两种方式,但是C本质上是前半部分的最终输出状态,并非每个时间步的输出,这里搞清楚对于后续的注意力机制的理解也有帮助。
在seq2seq结构中,通常将整个模型分为encoder和decoder两个核心组件,连接两个组件的就是context vector,即Encoder组件生成的上下文向量。
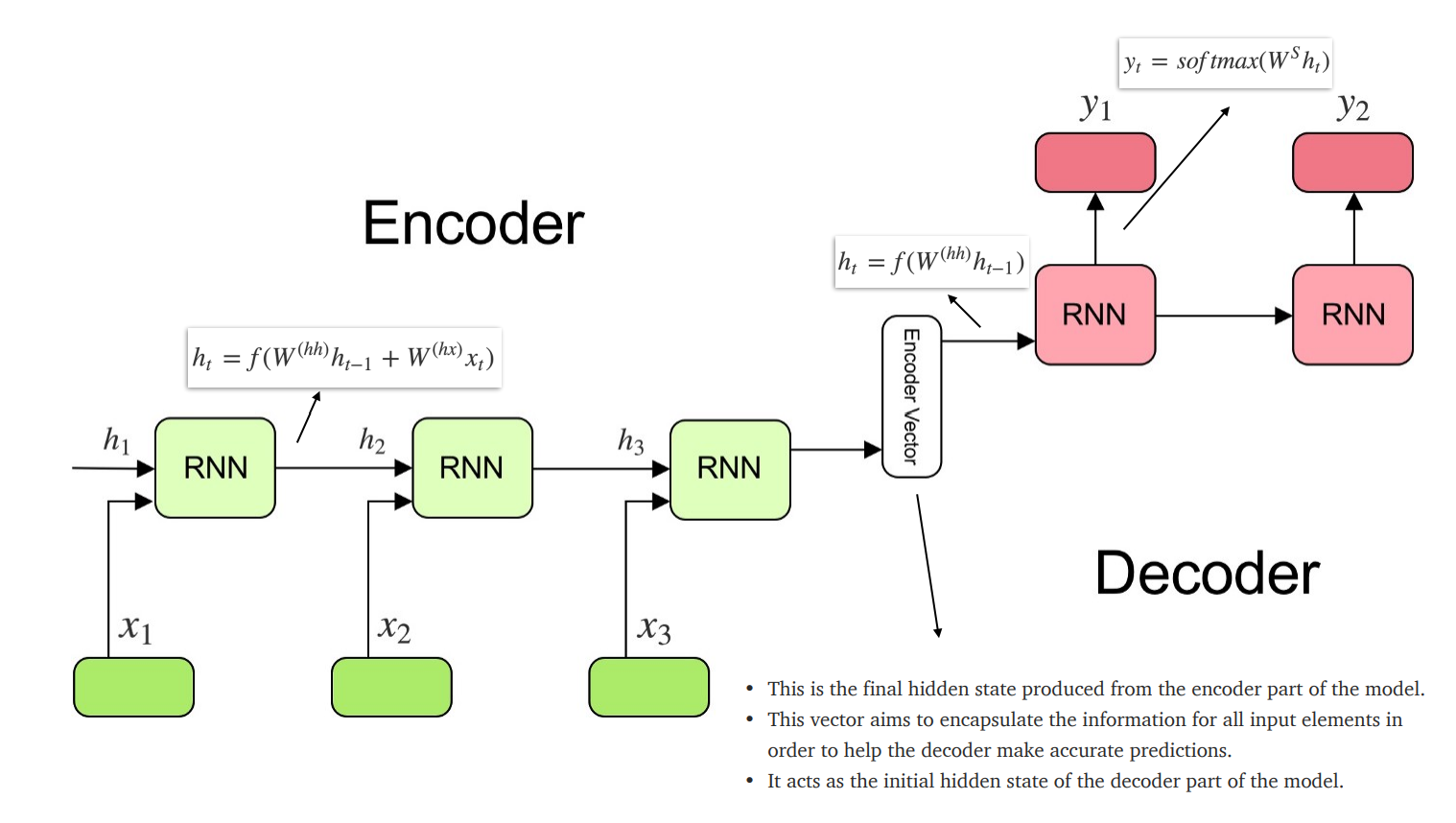
Encoder部分是RNN网络对输入序列进行处理,生成隐藏状态;Decoder部分是RNN网络对Encoder部分生成的隐藏状态进行处理,得到最终的输出。
Attention Mechanism
在seq2seq网络结构中,输出仅依赖于context vector,而context vector是encoder部分的最终输出,但是很多时候,输出还会关注部分输入,如何来计算输出与输入之间的关系,就需要依靠注意力机制。
没有注意力机制的情况,seq2seq的网络结构如下:
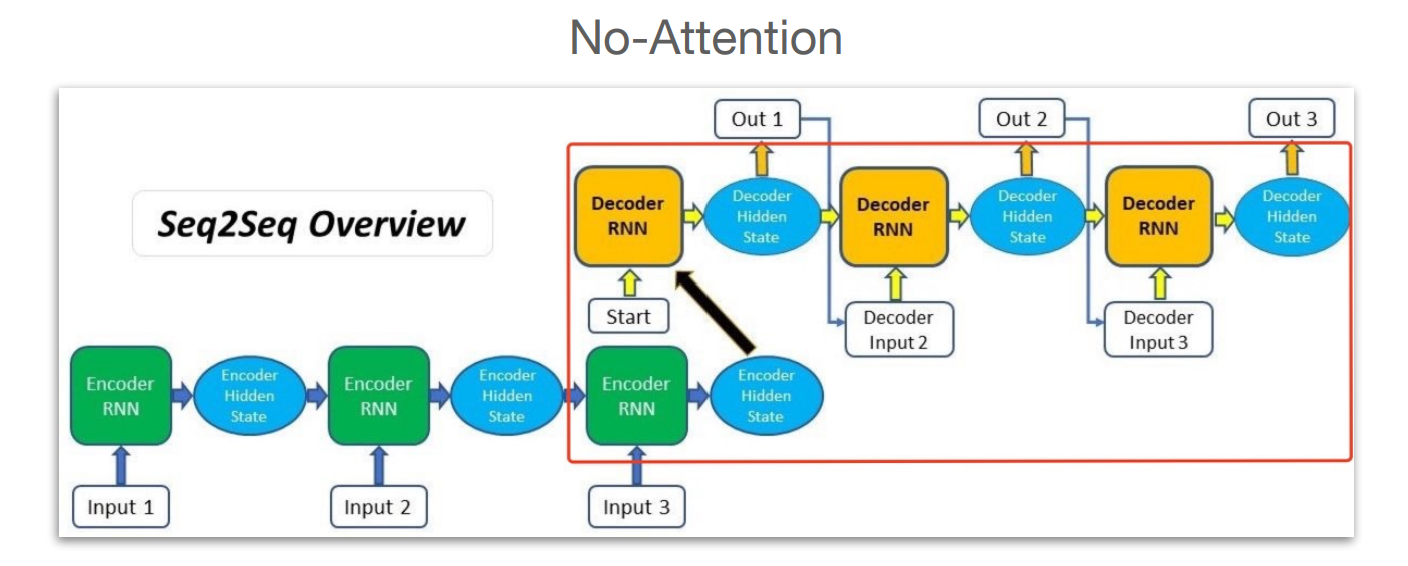
图中最后一个Encoder Hidden State 实际相当于context vector。
有注意力机制时,seq2seq的网络结构如下:
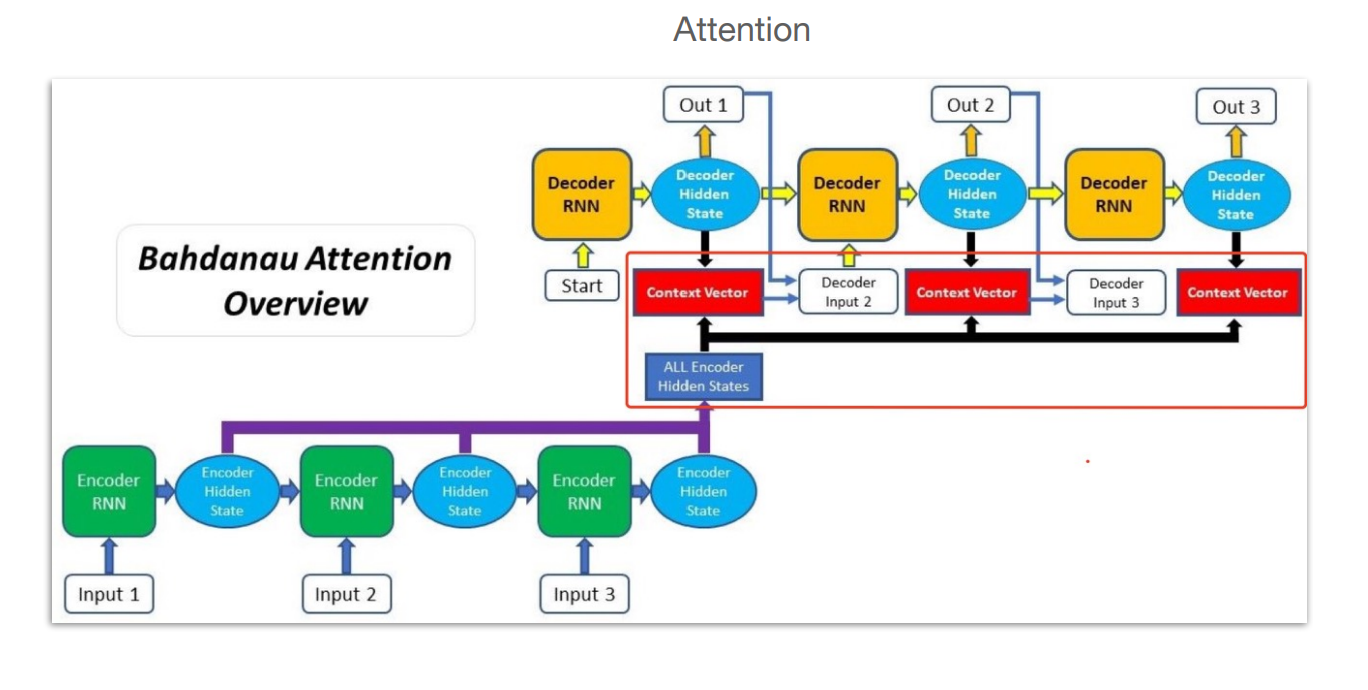
这里相比普通的seq2seq结构,有个All Encoder Hidden States,其汇集了Encoder部分每个时间步的隐藏状态,并通过一定的方法给到每个时间步的输出,这样输出就不仅依赖于Context Vector,注意这张图中也有context vector,但是其与无注意力机制的seq2seq架构中的context vector有所区别,这里的context vector是通过注意力机制计算得到的,后面会介绍(第6步)。
而这里所说的具体方法(下面会介绍),就是每个输出应该更关注哪部分输入,分为两种:Additive Attention和Multiplicative Attention,不过两种方法的本质思想一致,只不过采用的向量计算方法不同。
Additive Attention
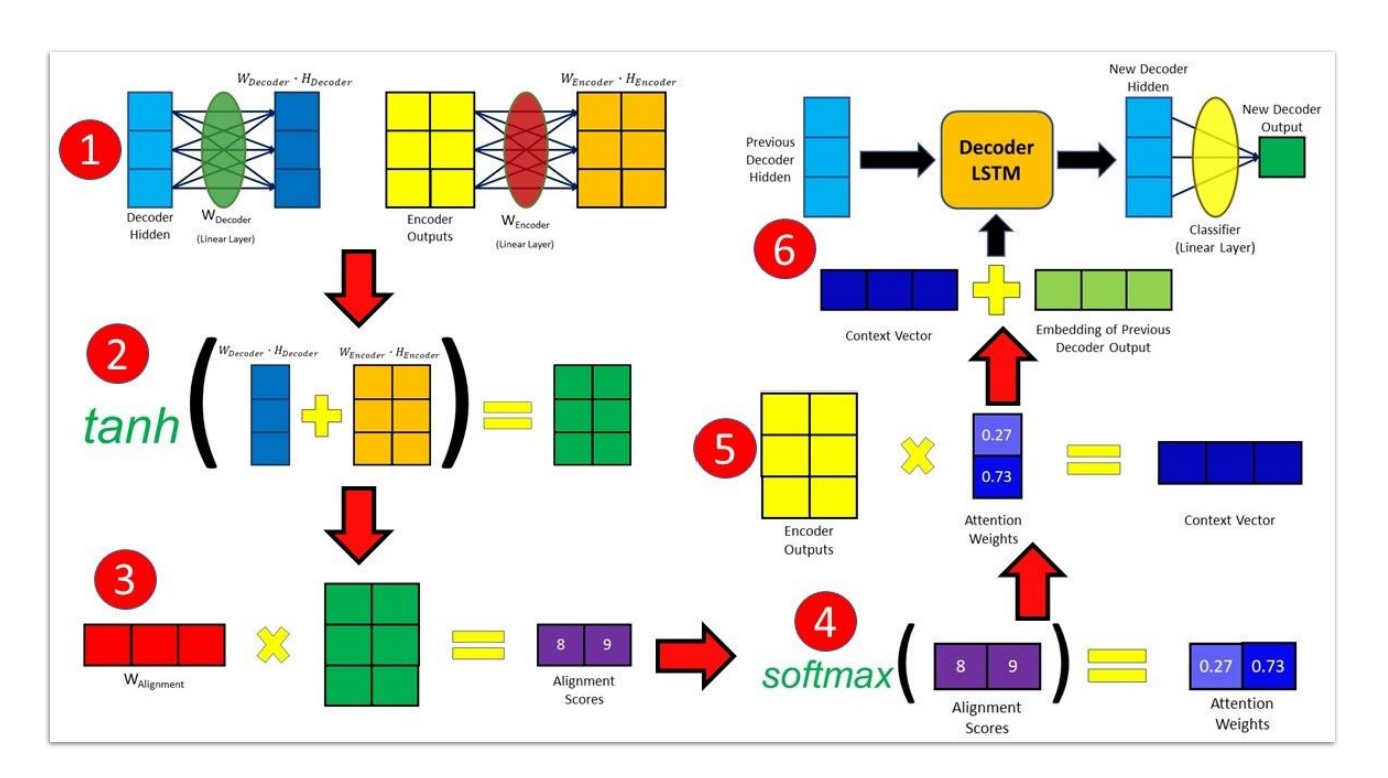
整体分为7个步骤(上图的序号标注有问题,应该从序号2开始):
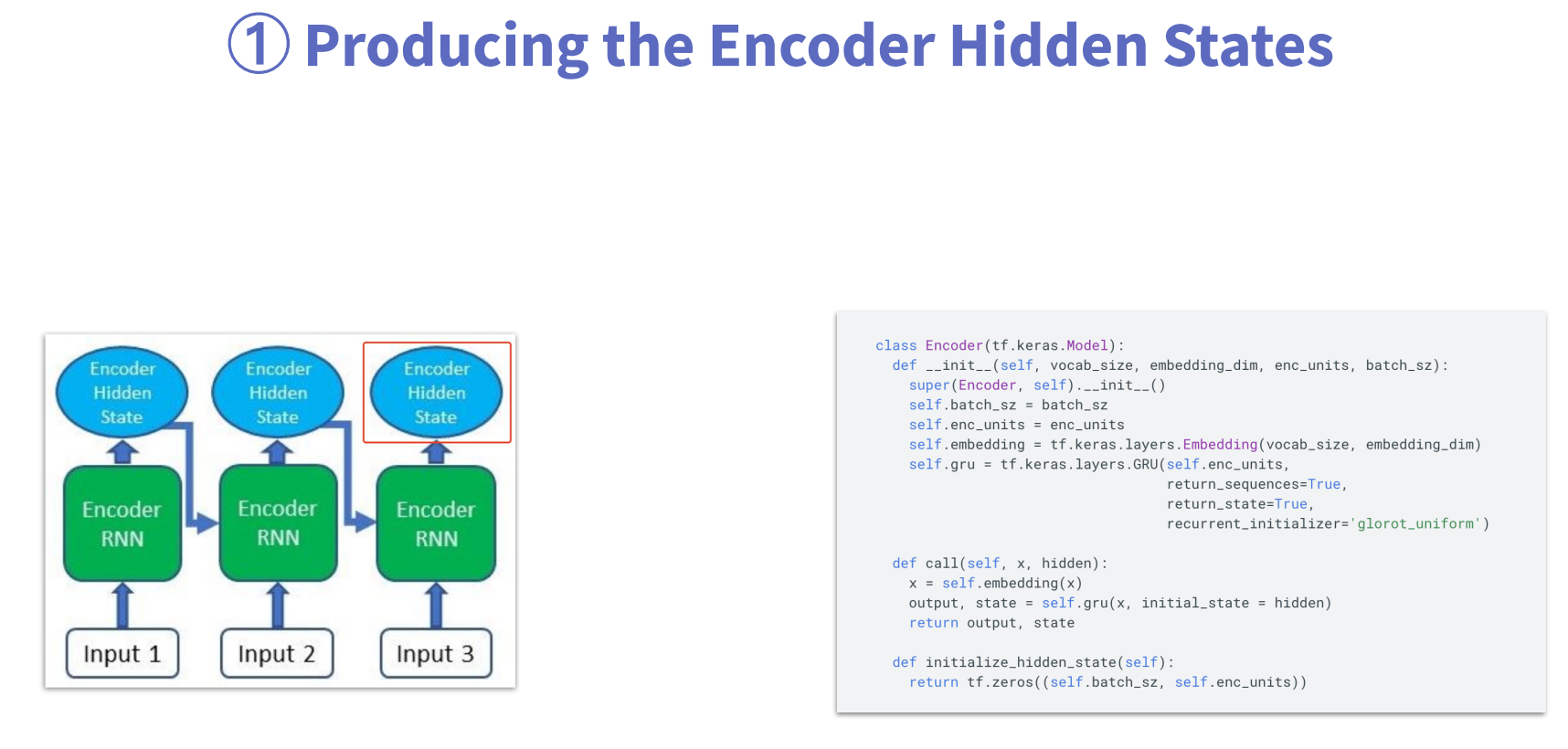
第1步:利用Encoder生成隐状态
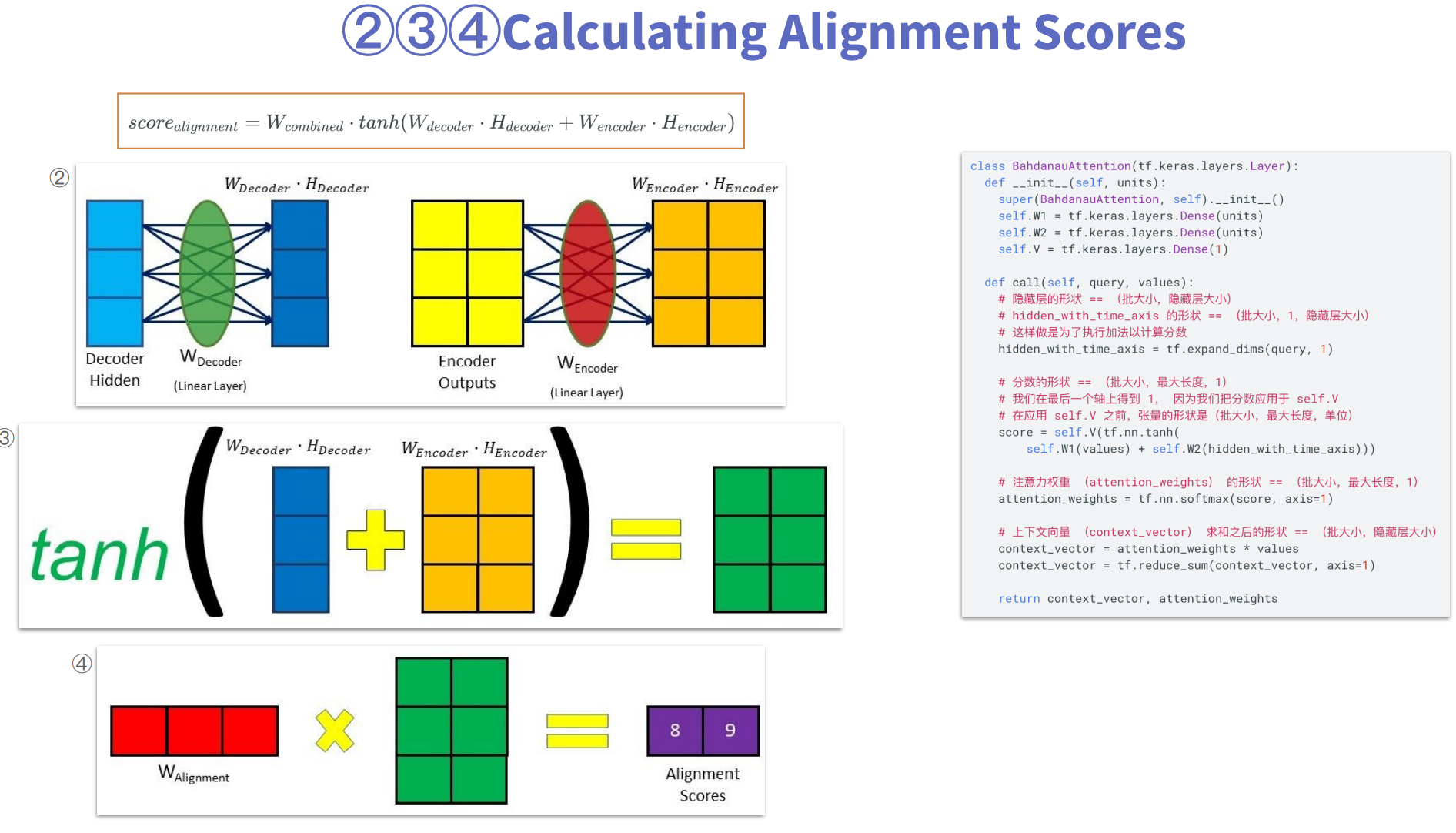
第2、3、4步:计算输入与输出相对应的分值
第5步:将分数值转换为概率值
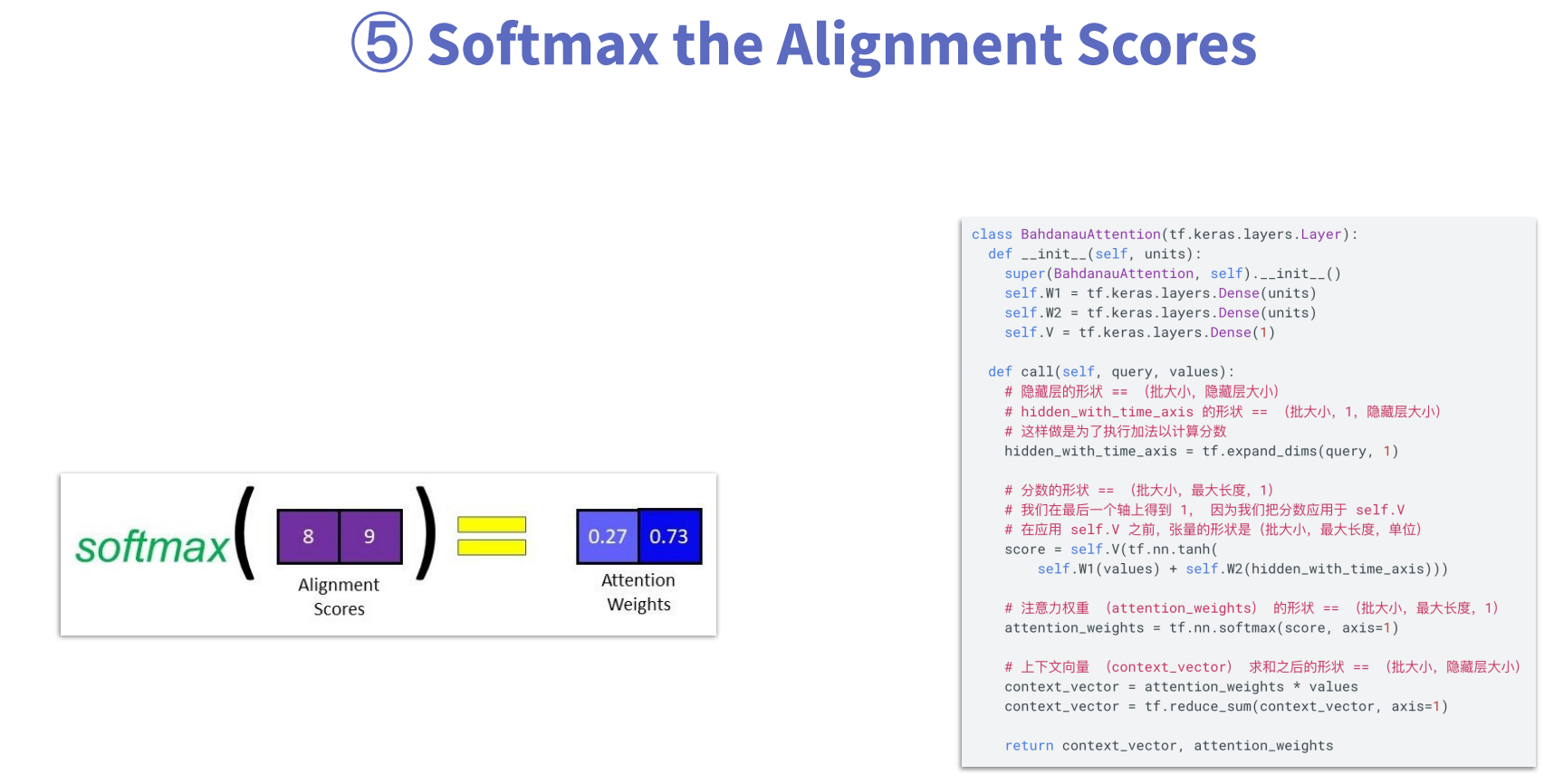
第6步:计算context vector,这里的context vector不再是Encoder的最终输出状态,而是每个时间步的输出与attention weights计算得到的结果。

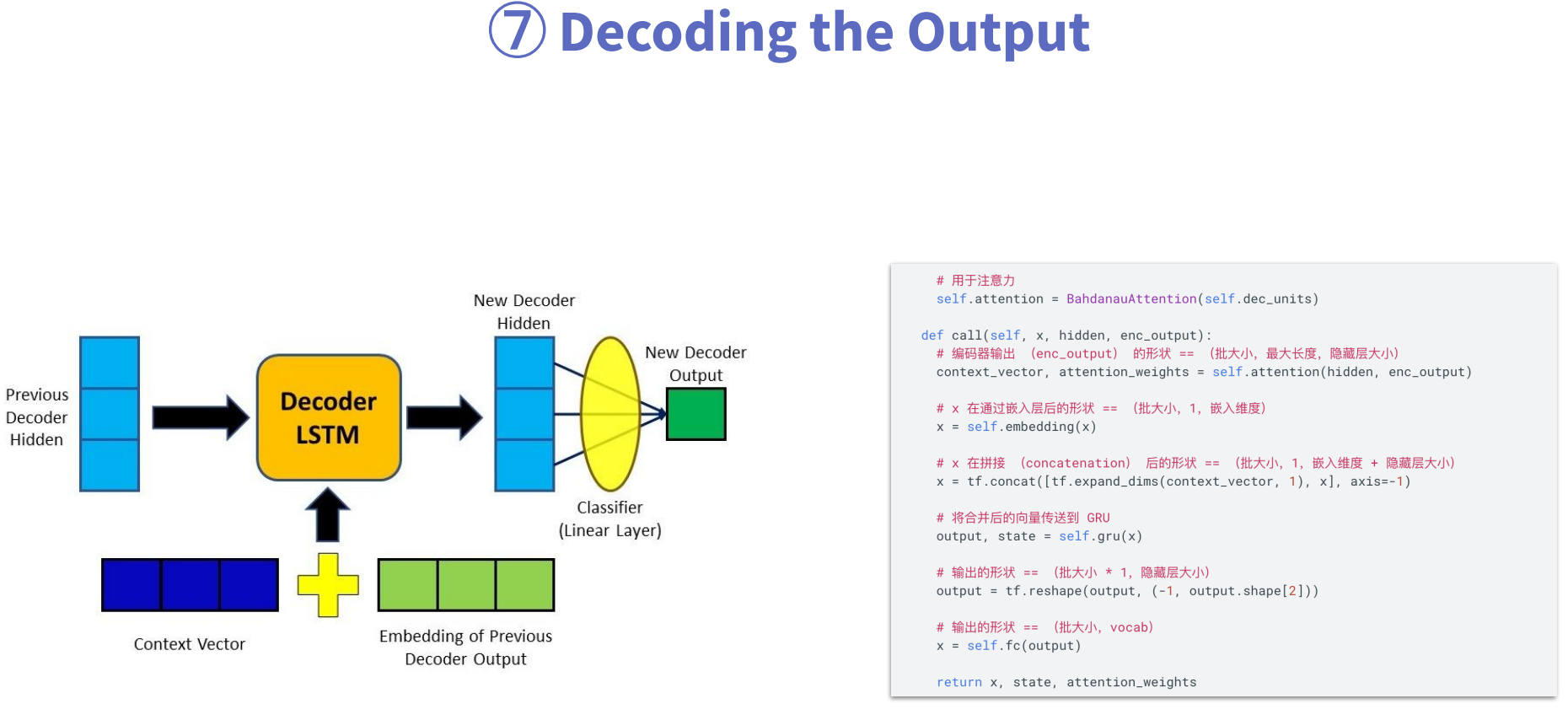
第7步:计算输出(decode),这里输出的计算涉及到三个输入,(1)前一个Decoder的隐状态;(2)context vector;(3)上一步的输出。经过Decoder之后生成隐状态,再通过分类层生成输出值。
Multiplication Attention(luong attention)
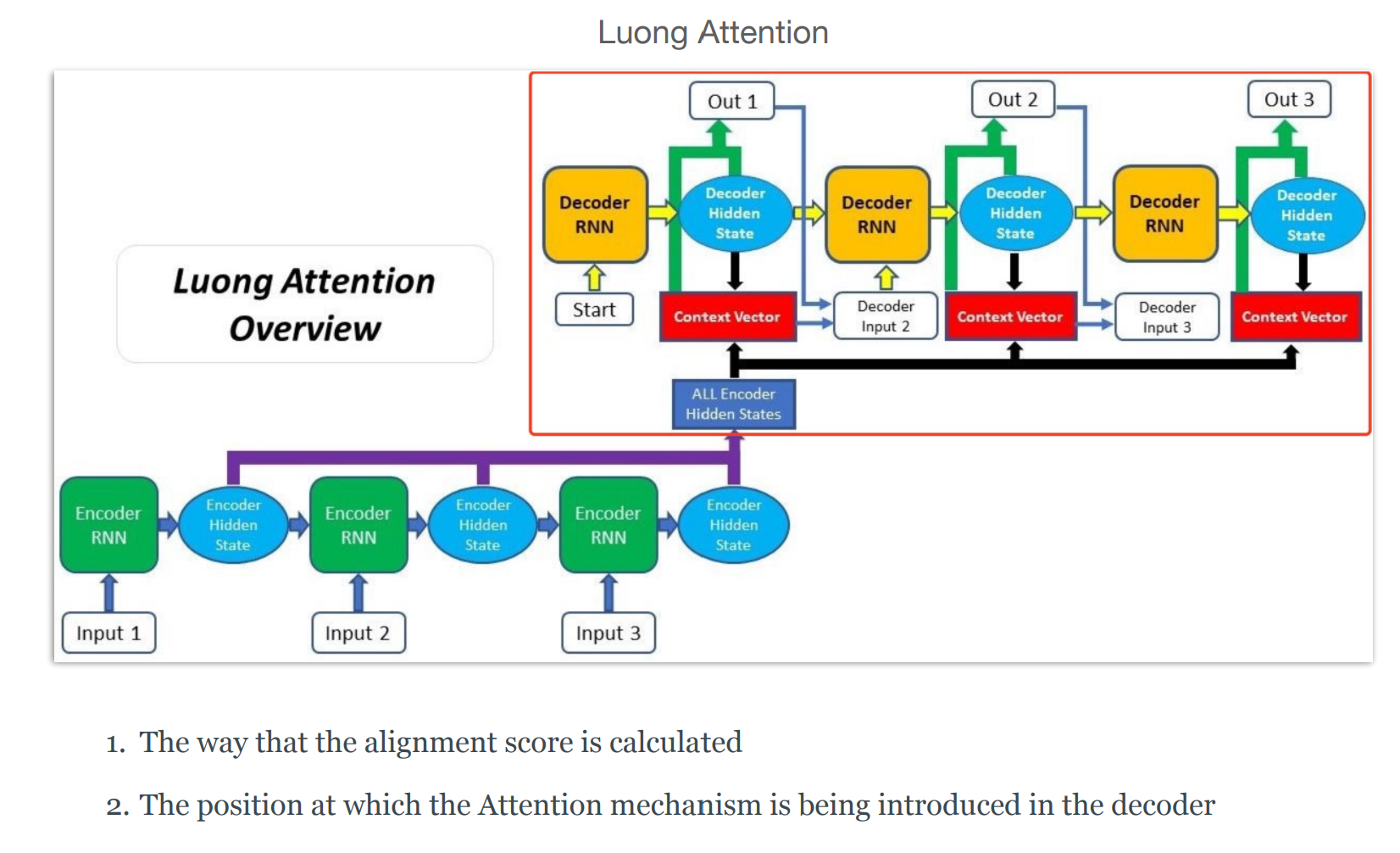
Multiplication attention与Additive Attention相比有两个区别
1、分数的计算方法,在multiplication attention 中,score的计算分为三种,dot、concat和general

dot方式,直接将H(encode)与H(decoder)相乘;
concat方式,与additive attention中的计算方式极为相似,只是把H(encoder)和H(decoder)前面各自的权重矩阵,改为使用同一个权重矩阵。
general方式,相比dot方式,前面加一个可学习的权重矩阵,灵活性更强。
2、decoder中注意力机制应用的位置,就是图中绿色部分,(1)利用context vector和decoder hidden state生成output,(2)然后再利用上一时间步的output和context vector和上一时间步的decoder hidden state生成下一时间步的decoder hidden state。然后再不断重复步骤(1)、(2)。