构建文本摘要Baseline并且开始训练
基于前面word2vec的原理与训练实践、seq2seq模型的原理与实践以及attention机制,已经分别写了相关的文章来记录,此篇文章就是基于前面所学,开始着手训练文本摘要模型,当然仅是一个比较普通的baseline,后面还会不断优化模型。
构建seq2seq模型
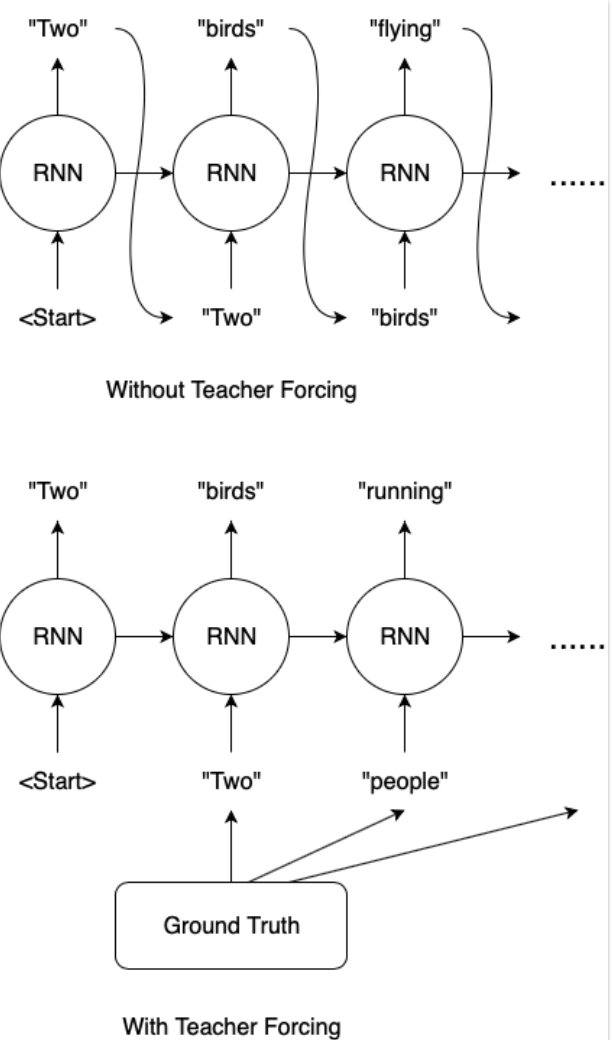
首先利用上一节seq2seq实践中,封装的encoder、decoder和attention,集成到此模型中来,另外就是增加了一个训练技巧–teacher forcing。那么teacher forcing是啥意思呢?
seq2seq模型的输出为decoder解码出的一系列概率分布,因此采用何种方式进行解码,就显得尤为重要。如贪心解码(greedy search)、teacher forcing以及介于两种之间的beam search等。
贪心解码的思想是,预测 t 时刻输出的单词时,直接将t−1时刻的输出词汇表中概率最大的单词,作为t时刻的输入,因此可能导致如果前一个预测值就不准的话,后面一系列都不准的问题。
Teacher Forcing的方法是,预测 t时刻输出的单词时,直接将t−1时刻的实际单词,作为输入,因此可能带来的问题是,训练过程预测良好(因为有标签,即实际单词),但是测试过程极差(因为测试过程不会给对应的真实单词)。
实际应用中,往往采用介于这两种极端方式之间的解码方式,如beam search 等,具体思路是预测 t 时刻输出的单词时,保留t−1时刻的输出词汇表中概率最大的前K个单词,以此带来更多的可能性(解决第一个方法的缺陷);而且在训练过程,采用一定的概率P,来决定是否使用真实单词作为输入(解决第二个方法的缺陷)。greedy search 和beam search后面我们也会一一介绍,下面是teacher forcing的具体实现。
1 | import tensorflow as tf |
开始训练
1 | import tensorflow as tf |
1 | import tensorflow as tf |
1 | from src.build_data.data_loader import load_dataset |
1 | def load_dataset(x_path, y_path, max_enc_len, max_dec_len, sample_sum=None): |