文本摘要生成的评估指标
ROUGE-N
这里的N就是指的n-gram,n=1时叫ROUGE-1(也叫Unigrams);n=2时,叫ROUGE-2(也叫Bigrams);n=3时,叫ROUGE-3(Trigrams)。

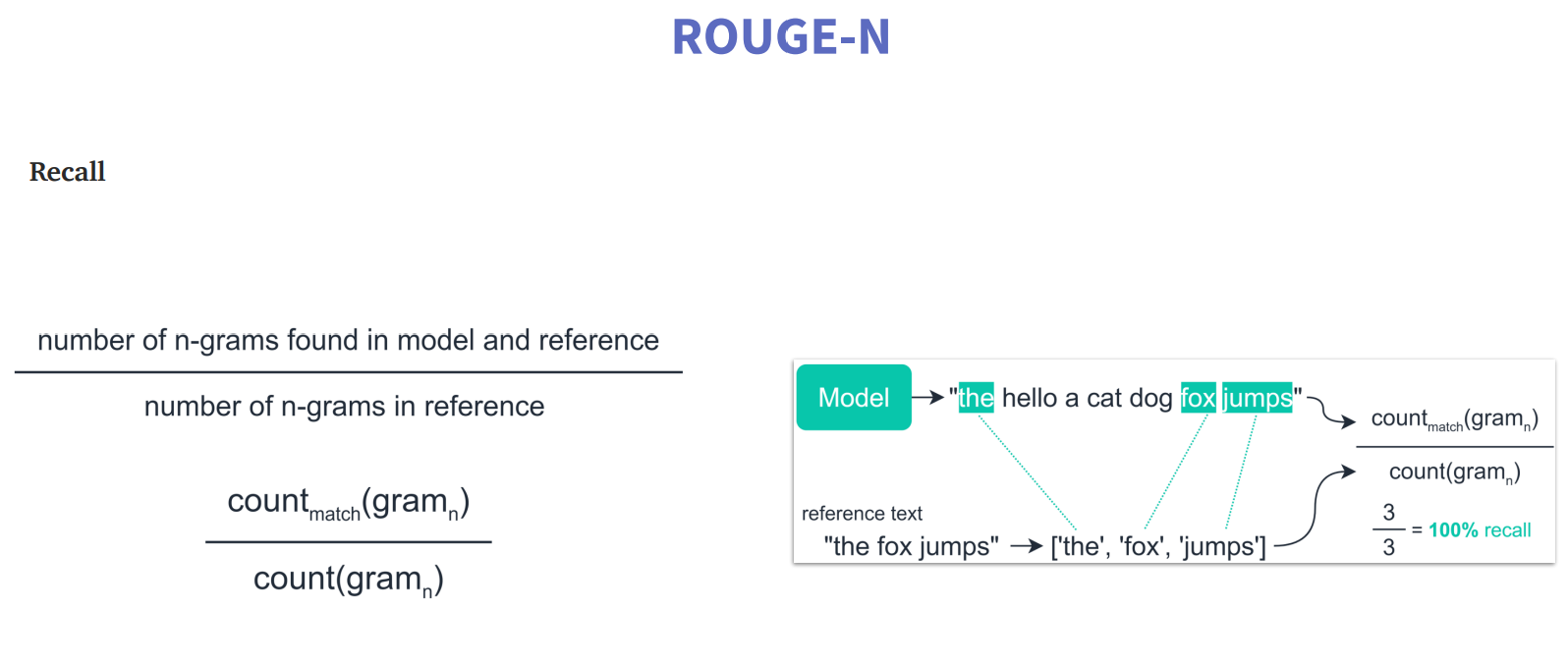

上图中precision和recall的计算均是采用ROUGE-1的方式。
ROUGE-L
这里L是指the longest common subsequence(LCS,即最长公共子串),根据这一指标来评估。


ROUGE-S
这里S指的skip-gram(word2vec中有学习过)。

思考:ROUGE方法的缺点
如果模型生成的文本和真实的文本语义完全一致,但是表达方式不一样(例如使用近义词),那么这种评测方式就有很大问题,也就说缺乏对语义的评测。
代码实战
1 | from rouge import Rouge |
批量评估
1 | model_outs = [ |
rouge没法直接对中文进行评估,需要做一些额外处理。