Out of Vocabulary
我们在NLP任务中一般都会有一个词表,这个词表一般可以使用一些大牛论文中的词表或者一些大公司的词表,或者是从自己的数据集中提取的词。但是无论当后续的训练还是预测,总有可能会出现并不包含在词表中的词,这种情况叫做Out of Vocabulary。
那么当我们遇到OOV的问题时,有以下解决方式。
Ignore
直接忽略OOV的情形,也就是不做处理,效果肯定不好。
UNK
这种方式就是把所有超出词表的词,转换为统一的\<unk>标识,对于性能的提升有限,特别是当超出词表的词是比较重要的词时。

Enlarge vocabulary
扩充词表就是把所有的词都尽可能的添加到词表中(包括非常低频率的词),这样就会带来问题:
- 计算量大,速度变慢,因为每次要预测的数量会变大;
- 低频率词的训练样本会很少,难以充分训练,最终结果就是训练不到一个理想的效果。
Individual Character
拆分成字符(如英文字母)训练,缺点就是丢失了语义和语法。
Spell Check
拼写检查,避免因为数据错误而导致的OOV。
subword
子词(类似于词根的思想),此方法介于单词和字符之间,借助n-gram实现。
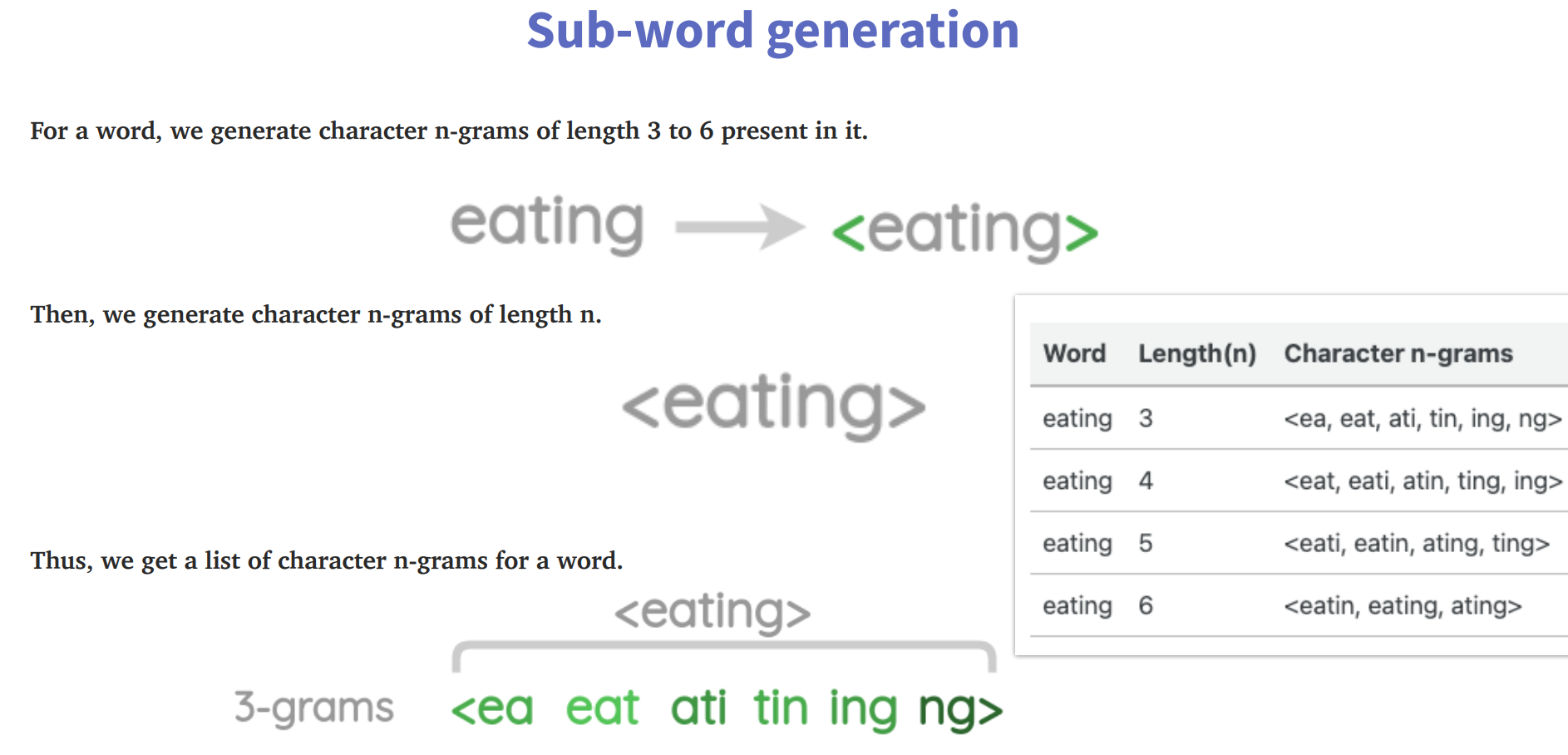
缺点:会生成非常多的子词,为了解决这一问题,利用hash将词哈希到数字以减少内存的占用。
BPE(Byte Pair Encoding)
BPE的方法其实是对subword方法的一种优化,就是减少子词。在GPT和RoBERTa中就是使用的BPE的方法。

代码实现
自己动手实现(简化版)
1 | import re |
1 | # 根据已经筛选到的最大频率组合,合并词表 |
上述过程只是一轮迭代的结果,在BPE算法中,最终要生成预先设定好的词表大小的字符对,那么也就是需要不断循环来实现。
1 | # 完整迭代 |
这里我们自行实现(思考:怎么判断生成的词数量达到预先设定的词表大小了?),锻炼动手能力,而实际上已经有相关的包封装了BPE的实现过程,主要有下面两种。
Google的sentencepiece
参考github项目:https://github.com/google/sentencepiece
安装:pip install sentencepiece
1 | input_file = 'botchan.txt' # 在上面的github项目中 |
这里方法名叫做train,实际上也就是计算,适合大规模的数据处理,速度比较快。最后会生成并保存两个文件分别为:sentencepiece.model和sentencepiece.vocab。
通过以下方式可以加载上面训练得到的词表
1 | sp = SentencePieceProcessor() |
huggingface transformer的 tokenizers
安装:pip install tokenizers
1 | tokenizer = Tokenizer(BPE()) |
WordPiece

wordpiece与BPE算法本质一样,都是基于subword的优化算法,主要区别在于如何选择子词进行合并,下面的unigram language model也是这样。
1 | from tokenizers import Tokenizer |
Unigram Language Model

同样可以借助Google的SentencePiece包来实现,只需要把model_type改为unigram即可。