NER学习和实践阶段性总结
前面一段时间我针对NER进行了系统的学习,并借助UER-py对开庭公告进行了实体抽取,整个项目收获颇丰,前面本身已经对学习和实践过程进行了记录,具体细节参考前面的文章。
对NER技术不太了解的同学可以参考前面我翻译的一篇NER论文综述。
这篇文章主要内容包括:
- 针对网络模型以及其中涉及的技术点进行一定概述;
- 针对上篇NER综述进行一定的补充;
- 结合自己所擅长领域,思考后续可以借助NER来做的一些研究和实践。
网络模型结构
根据上篇NER综述,基于深度学习的命名实体识别模型由输入的分布式表示、上下文编码器和标签解码器组成。经过近年来的研究发展,每个部分都有较多的技术可选,这里我用思维导图的形式有好地展示了原论文中的技术分类。
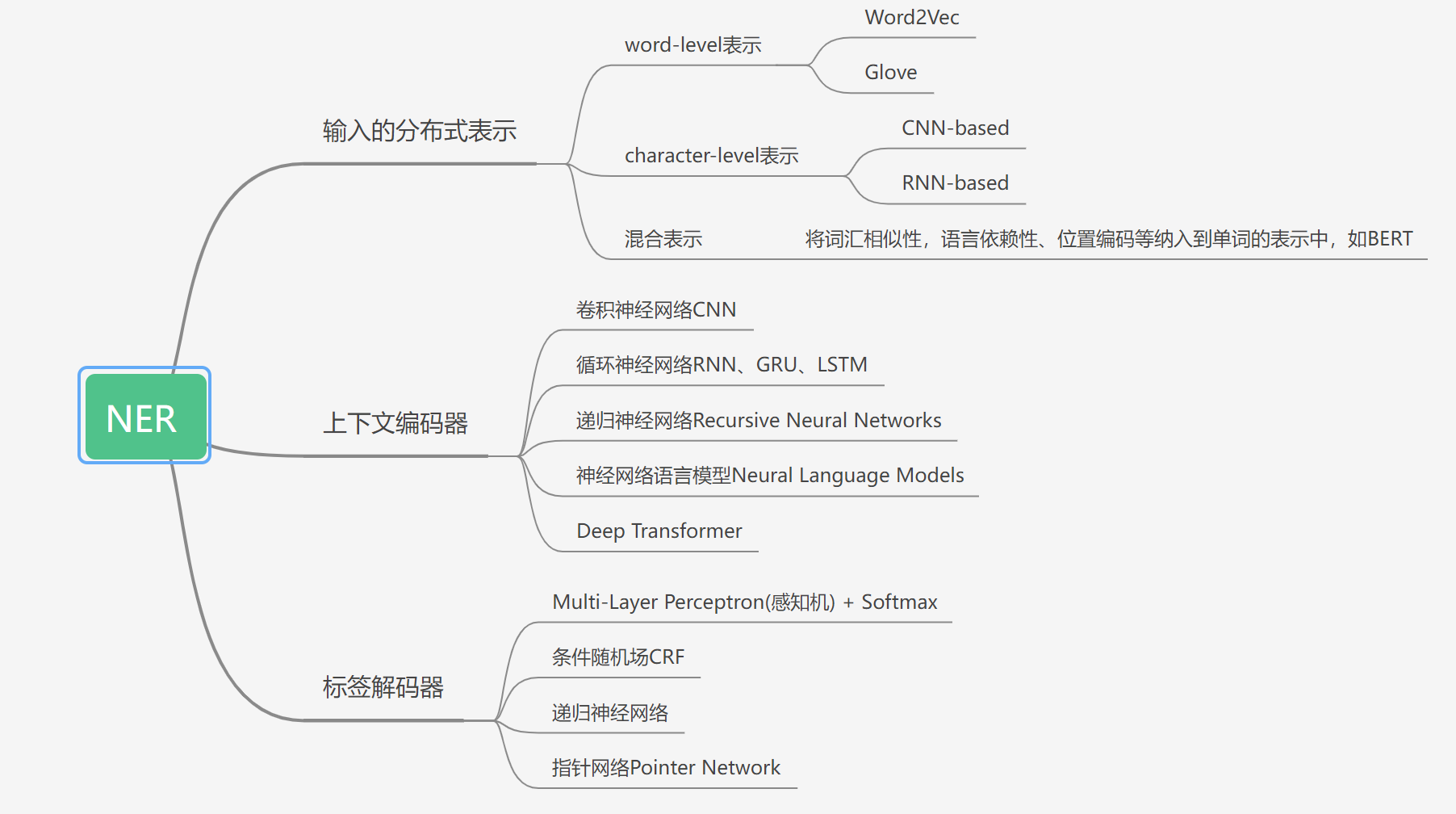
这里输入的分布式表示使用了BERT的预训练词嵌入权重,并且网络结构与BERT类似,由token embedding、position embedding、segment embedding和Layer Norm组成;上下文编码器我使用了transformer encoder,其由堆叠的自注意力、多头注意力和逐点、完全连接的层来构建;标签解码器部分我选择了CRF,CRF是标签解码部分最常用的方法,其针对非语言模型的词嵌入,捕获标签转换依赖项是非常有效的,但是当实体类型数量很大时,CRF的计算成本很高。
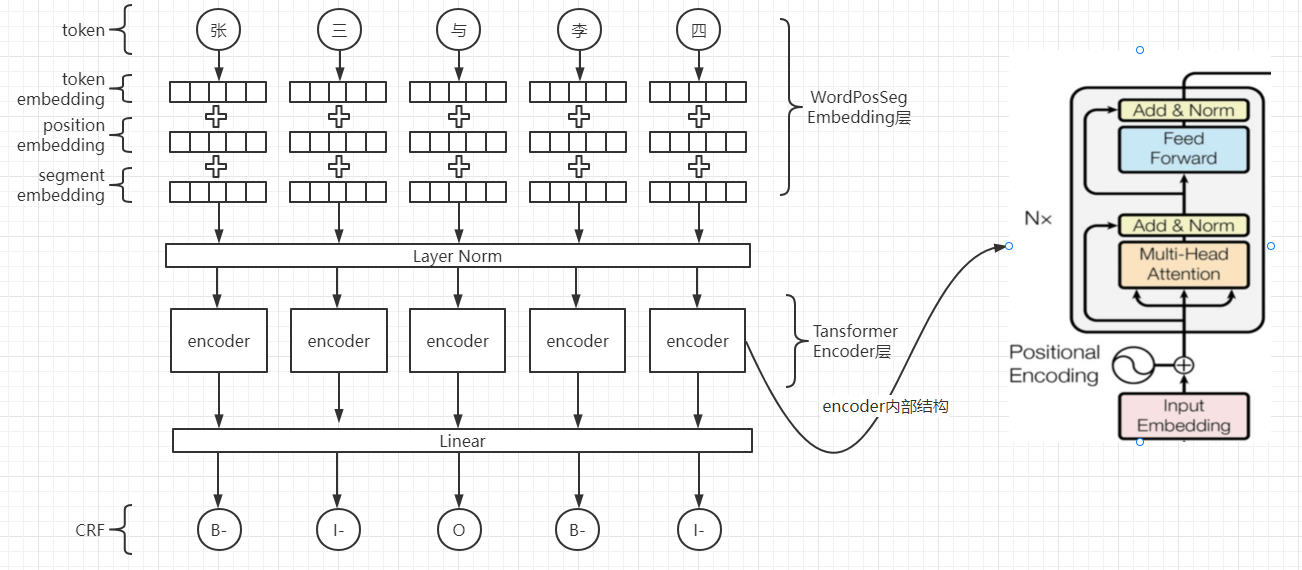
关于BERT当然是看一下原论文,下面我仅针对BERT的三个Embedding层做简单概述,其属于输入的分布式表示的一种混合表示。在上下文编码器方面,基于大型语料库进行预训练的transformer比LSTM更有效,不过如果没有经过预训练或者训练数据比较少的情况下,transformer就不行了。
在我的项目实践过程,我专门针对使用CRF和不使用CRF做了性能对比,使用CRF的提升微乎其微,这在上篇NER综述中也给出了解释:与softmax分类相比,在采用诸如BERT和ELMo等语境化语言模型嵌入时,CRF并不总能带来更好的性能。对于CRF的具体原理会在其他文章中单独展开。
总之,选择哪种结构是你的数据和领域任务决定的,如果数据丰富,可以考虑使用从头开始RNN训练模型和微调语境化语言模型;如果数据稀缺,采用迁移策略可能是更好的选择。对于新闻领域,有很多预训练模型可用。对于特定领域(如医学和社交媒体),使用特定领域的数据微调通用语境化语言模型通常是一种有效的方法。
BERT、GPT、EMLo的关系
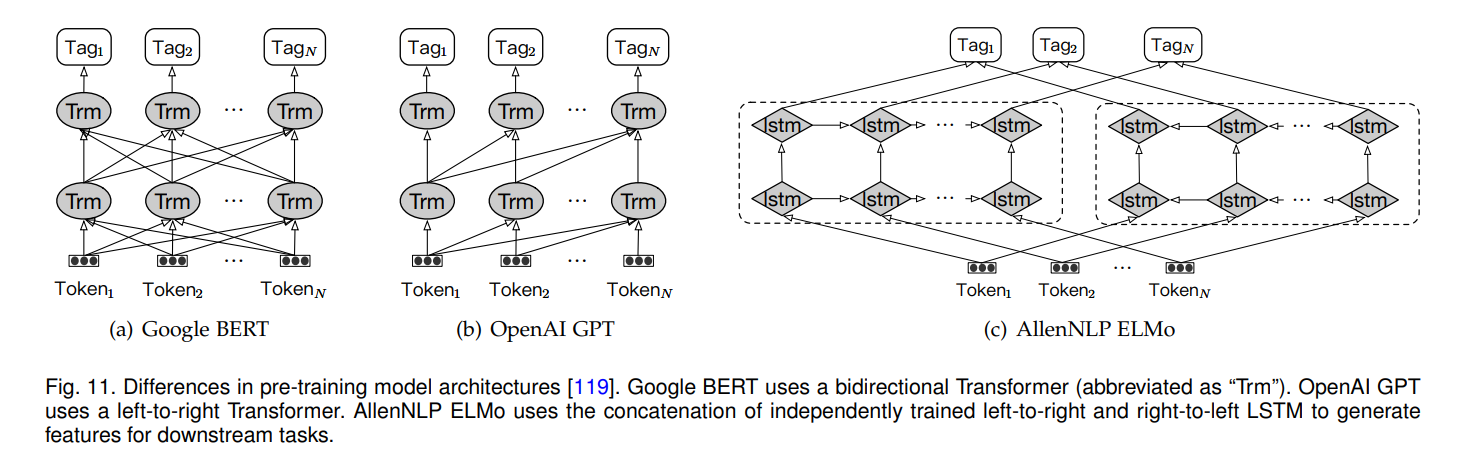
BERT论文中把将预训练语言模型应用到下游任务分为两种方法,基于特征的(以ELMo为代表作)和基于微调的(以GPT为代表作),虽然三者都是2018年推出,但是按照时间顺序应该是EMLo、GPT和BERT。
之所以他们都如此有名,是因为他们并不局限于特定的自然语言任务,他们的主要目标(这里说的是主要目标,并不是全部,其本身也可以训练特定的目标任务)是通过语言模型训练得到一个通用的词向量表示,供下游任务使用。在此之前比较流行的词向量表示方法是Word2Vec和Glove,但是这两种方法的局限性在于
- 每个单词的表示是固定的,无法解决一词多义的问题;
- 没有将上下文语境纳入词的表示(其实本质还是一词多义问题)。
ELMo (Embedding from Language Models) 是于2018年由论文《Deep contextualized word representations》提出的一种深层语境词向量表征模型,它可以根据上下文来调整单词的 embedding 表征,使得同一个单词在不同语境中可以表达为不同的词义。
ELMo 是基于 biLM(双向语言模型,即由前向语言模型和后向语言模型组成) 而建立的模型,它采取的是多层Bi-LSTM 结构,虽然是双向LSTM,但只有在最后一层上作了concat,所以并不是真正意义上的上下文。
基于特征提取的预训练方法是使用之前网络学到的表示来从新样本中提取出有趣的特征,ELMo分为两阶段工作:
- 第一阶段:利用 biLSTM 模型,根据上下文对 embedding 进行动态表征;
- 第二阶段:将第一阶段得到的 embedding 整合后作为补充的新特征,交给下游任务使用。
GPT全称为 Generative Pre-Training,即生成式预训练。它首次于 2018 年由 OpenAI 在论文《Improving Language Understanding by Generative Pre-Training》中提出。GPT使用transformer decoder,比LSTM的特征提取能力强,但是其结构限制了只能从左到右提取特征,是一个单向网络,即只能利用上文来推断后面的单词,是一个单向语境的模型。
基于微调的预训练方法是将用于特征提取的模型顶部几层“解冻”,并将这解冻的几层和新增加的部分联合训练,GPT也是一个两阶段模型,第一阶段 pre-training,第二阶段 fine-tuning。
BERT(Bidirectional Encoder Representations from Transformers),代表来自Transformer的双向编码器表示,与EMLOL和GPT不同的地方在于,BERT是一个真正的双向网络,使用transformer encoder学习语言表示,另外还提出了两个新的任务,MLM(Masked Language Model,遮蔽语言模型)和下一个句子预测。
下图是ELMo、GPT和BERT的模型结构对比。
相关文章:
https://zhuanlan.zhihu.com/p/550487826
https://zhuanlan.zhihu.com/p/558646716
https://zhuanlan.zhihu.com/p/395136481
BERT和GPT虽然取得了卓越的成就,但是别忘了最核心的组件是Transformer,对于Transfomer的原理在其他的文章中我也会介绍。
BERT的三个Embedding层
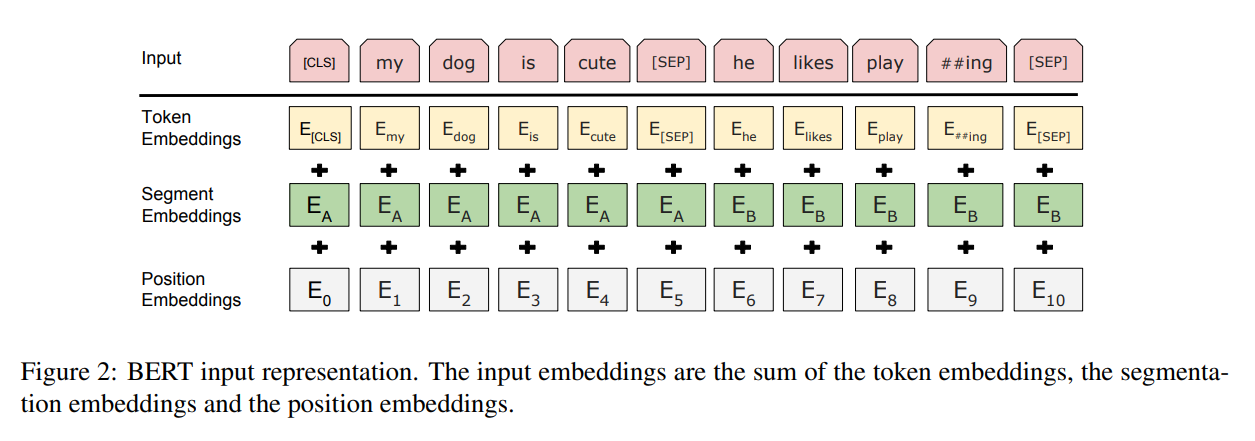
token embedding
token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示;输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们是为后面的分类任务和划分句子对服务的。
BERT中tokenization使用的方法是WordPiece tokenization, 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。
position embedding
表示当前词所在位置的index embedding。在BERT中positionEmbedding是通过模型学习到的embedding向量,而transformer的positionEncoding是通过sin、cos直接构造出来的。
Transformers无法编码输入的序列的顺序性,加入position embeddings会让BERT理解下面下面这种情况, I think, therefore I am,第一个 “I” 和第二个 “I”应该有着不同的向量表示。
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来将序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行代表序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会有完全相同的position embedding,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。(疑问:在后续的学习过程中会改变吧?)
segment embedding
表示当前词所在句子的index embedding。假设两个句子作为输入,对第一个句子的每个token添加sentence A embedding,第二个句子添加sentence B embedding,实验中对应的EA=1,EB=0。
我们已经介绍了长度为n的输入序列将获得的三种不同的向量表示,分别是:
Token Embeddings, (1, n, 768) ,词的向量表示
Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
参考原文链接:https://blog.csdn.net/weixin_48185819/article/details/122042452
这篇文章写的好棒,转载一下:https://blog.csdn.net/liu16659/article/details/108025672
NER综述补充
上篇NER综述中未提及NER三种任务种类,根据文本中实体存在的形式一般可以将NER任务分成三大类,分别是:
- flat ner:传统的NER,实体之间彼此不重合且连续;
- nested ner:嵌套NER,实体之间存在部分重合甚至完全嵌套的情况;
- discontinous ner:非连续NER,单个实体由多个不连续的文本片段组成;
其中最常见的是flat ner,也是三种任务相对来说更简单的任务,针对另外也有相关的研究,不过我目前并没有去仔细了解过,只是记录一下,后面遇到了至少有一定的头绪。
另外关于这三种NER任务,复旦邱锡鹏老师的项目组有一篇论文,提出一种模型可以同时解决这三类任务,感兴趣的同学可以深入研究下。
论文题目:《A Unified Generative Framework for Various NER Subtasks》
论文地址:https://arxiv.org/pdf/2106.01223.pdf
针对司法风险领域的NER思考
细粒度NER任务
现在NER的研究是非常多的,面向开放的数据集有很多最新论文都提出了比较先进的技术方案,效果也都不错,但是多数还是一些针对通用的命名实体的研究,比如人名、组织机构名、地名等,当然对于少数领域比如医药领域、生物医学领域也是有一定的研究的,其实还是有很多特定的领域是需要用这一技术来解决的,例如司法领域和风险领域(因为我本来就是做司法和风险领域比较多,所以很容易就想到这两个领域)。
当然这类工作谈不上是研究和创新,算是一种工程应用,就是把最新的研究成果应用到这些领域,自然也是有意义的,不过目前的难点均是在数据集标注上,所以针对少样本学习一直是一个挑战。应用于特定的领域算是NER细粒度任务的一方面,另一方面是同一个命名实体可以有多个类型,比如在司法领域中,一个司法案件的当事人,既可以是一家企业,也可以是被告,有两种类型,这方面的研究没太怎么见过,后续是一个研究方向。
边界检测和实体类型分类解耦
这一研究方向在司法和风险领域目前没有想到可以深入展开的点。将命名实体识别和实体链接联合起来
关于实体链接的具体任务是啥,对于我个人来说还需要进一步研究。借助辅助资源的NER
借助辅助资源这里我觉得可以理解为外部知识库(总感觉与实体链接有一点像),其实无论在司法领域还是风险领域,一般要获取的实体信息均有比较明显的特征,我觉得是可以借助外部知识库来协助命名实体识别的,比如案号有一定的规则,案由是一系列标注的术语,处罚依据带有书名号等。
其他关于NER迁移学习、可扩展性、通用工具包我觉得是工作量大,难度非常高的工作,不是基于我所关注的领域就可以去解决的问题,不过我目前的一个研究规划就是希望可以训练得到一个针对司法和风险领域通用的NER模型。