PyTorch的自动微分(autograd)
计算图
计算图是用来描述运算的有向无环图
计算图有两个主要元素:结点(Node)和边(Edge)
结点表示数据,如向量、矩阵、张量
边表示运算,如加减乘除卷积等
用计算图表示:y = (x + w) (w + 1)
令 a = x + w,b = w + 1
则 y = a b
用计算图来表示这一计算过程: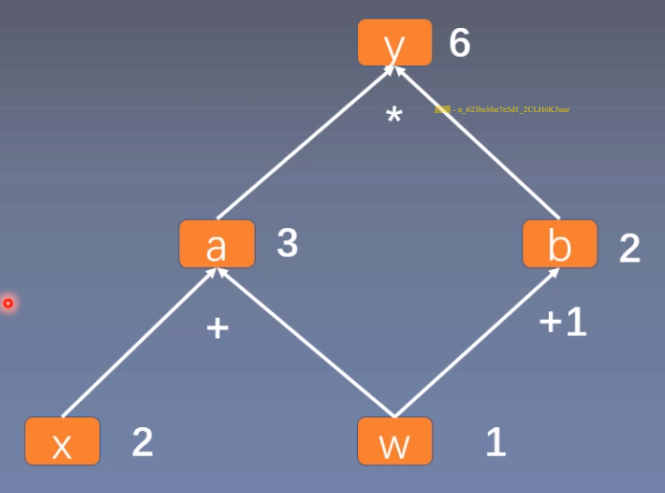
使用计算图可以更方便的求导
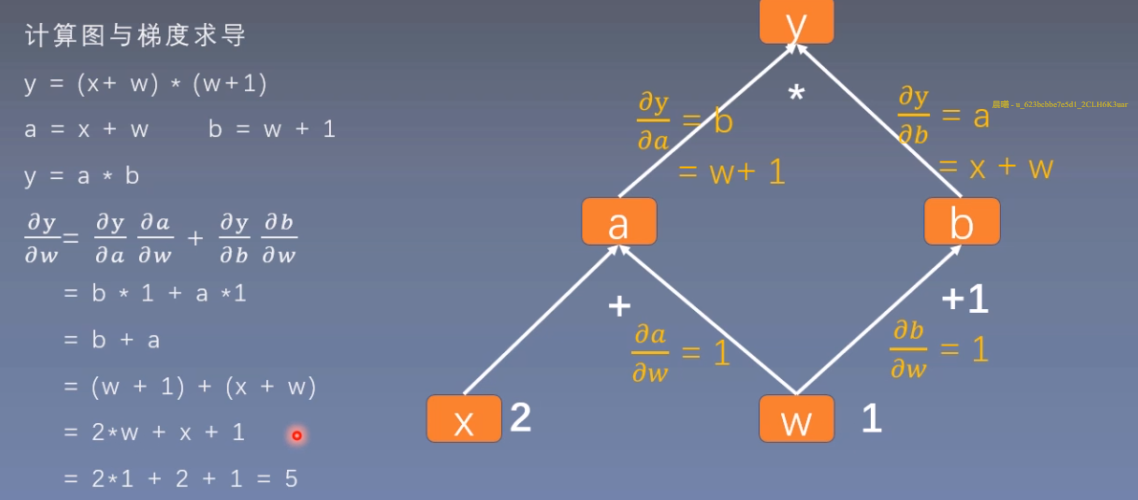
在计算图中,y对w求导,就是找到所有y到w的边,然后分别进行求导。
1 | w = torch.tensor([1.], requires_grad=True) |
叶子节点:用户创建的结点成为叶子结点,如X与W
is_leaf:指示张量是否为叶子结点
叶子结点的作用:节省内存,非叶子结点的梯度会被释放
1 | print("is_leaf:\n", w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf) |
如果想要保存非叶子结点的梯度,需要在反向传播前前,使用a.retain_grad()(以张量a为例)
grad_fn:记录创建该张量时所用的方法(函数)
1 | print("grad_fn:\n", w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn) |
这里w和x是用户创建的,所以grad_fn为None,a、b、y都是有grad_fn的,其grad_fn的作用主要是在求导时,可以知道其是使用哪种计算方式得到的,以便确认求导法则。
动态图 VS 静态图
根据计算图搭建方式,可将计算图分为动态图和静态图
动态图:运算和搭建同时进行,特点:灵活,易调解,以pytorch为代表
静态图:先搭建图,后运算,特点:高效,但不灵活,以tensorflow为代表
autograd–自动求导系统
torch.autograd.backward方法介绍
torch.autograd.backward:自动求取梯度,参数
- inputs:用于求导的张量,如loss
- retain_graph:保存计算图
- create_graph:创建导数计算图,用于高阶求导
- gradient:多梯度权重
tensor.backward()调用的就是torch.autograd.backward()
在梯度求导之后,计算图会被释放,无法执行两次backward(),要想执行两次backward(),就需要将retain_graph设置为True。
一般中间结点会遇到需要多次backward的情况
下面代码解释多梯度权重1
2
3
4
5
6
7
8
9
10
11
12w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a ,b)
y1 = torch.add(a, b) # dy1/dw = 2
loss = torch.cat([y, y1], dim=0)
grad_tensors = torch.tensor([1, 1])
loss.backward(gradient=grad_tensors)
print(w.grad)
tensor([7.])
这里同时求了dy/dw和dy1/dw,w.grad=(1 x dy/dw) + (1 x dy1/dw) = 5+2
1 | grad_tensors = torch.tensor([1, 2]) |
w.grad = (1 x dy/dw) + (2 x dy1/dw) = 5 + 2x2 = 9
torch.autograd.grad()方法介绍
torch.autograd.grad():求取梯度
- outputs:用于求导的张量,如loss
- inputs:需要梯度的张量
- create_graph:创建导数计算图,用于高阶求导
- retain_graph:保存计算图
- grad_outputs:多梯度权重
1 | # x需要设置requires_grad=True才可以后续求导 |
autograd小贴士:
- 梯度不会自动清零(比如w会一直叠加),手动清零:
w.grad.zero_(); - 依赖于叶子结点的结点(比如a, b, y),其requires_grad=True;
- 叶子结点不可以执行in-place操作(原地操作,在原始内存地址中改变数据)。
自动求导系统实现
torch.Tensor 是包的核心类。如果将其属性 .requires_grad 设置为 True,则会开始跟踪针对 tensor 的所有操作。完成计算后,您可以调用 .backward() 来自动计算所有梯度。该张量的梯度将累积到 .grad 属性中。
如果你想计算导数,你可以调用 Tensor.backward()。如果 Tensor 是标量(即它包含一个元素数据),则不需要指定任何参数backward(),但是如果它有更多元素,则需要指定一个gradient 参数 来指定张量的形状。
这两段话非常重要,我们借助下面这个例子来帮助理解
1 | import torch |
每个张量都有一个 .grad_fn属性保存着创建了张量的 Function 的引用,(如果用户自己创建张量,则grad_fn 是 None )。
针对y做更多的操作
1 | z = y*y*3 |
这里的重点是x.grad的计算

通过这个例子,理解上面的两段话就是,这里x的requires_grad 属性为True,后续跟踪针对x的所有操作,之后调用backward自动计算所有梯度,x的梯度累积到.grad属性中。
接下来我们再看一个pytorch自动微分的例子,如果对于张量手动计算梯度的话,代码是这样的:
1 | import torch |
这段代码最核心的点在于Backprop部分,首先根据
loss=(y_pred-y)^2
容易到loss对于y_pred的偏导数,即grad_y_pred
而loss对于w2的偏导数,即grad_w2就稍复杂一些,涉及到矩阵求导、雅可比矩阵和链式法则。
根据在网上查阅资料得到,查到一个矩阵求导相关的文章:
https://blog.sina.com.cn/s/blog_51c4baac0100xuww.html
说实话没怎么看懂,以前没有学过矩阵求导。
关于雅可比矩阵和链式法则:

上面的内容简而言之,雅可比矩阵是一阶偏导数以一定方式排列成的矩阵,根据求导的链式法则,(y对x的偏导)x(l对y的偏导) = (l对x的偏导)。
现在可以想到
1 | grad_w2 = y_pred对w2的偏导 x loss对y_pred的偏导 |
同理对于loss对于w1的偏导
1 | grad_w1 = h_relu对于w1的偏导 x y_pred对h_relu的偏导 x loss对y_pred的偏导 |
现在我们已经理解了上述求导和反向传播的过程,如果使用pytorch的自动求导,则可以利用下述方式来实现。
1 | import torch |