使用BiLSTM-CRF进行命名实体识别
BiLSTM-CRF网络结构
关于LSTM的原理以及其对比RNN的优势前面已经有多篇文章介绍了,这里就不再赘述。
使用BiLSTM-CRF进行命名实体识别任务时的步骤流程(粗略地):
- 先将句子转化为字词向量序列,字词向量可以在事先训练好或随机初始化,在模型训练时还可以再训练;
- 经BiLSTM特征提取,输出是每个单词对应的预测标签;
- 经过CRF层约束,输出最优标签序列。
使用BiLSTM-CRF进行命名实体识别任务时的步骤流程(细致地):
- 先将字词传入Embedding层获取词向量,然后传入BiLSTM层之后得到隐状态;
- 将完整的隐状态序列接入线性层,从n维映射到k维,其中k是标注集的标签数;
- 从而得到自动提取的句子特征,记作矩阵P = (p1, p2, …, pn),注意该矩阵是非归一化矩阵
其中pi表示该单词对应各个类别的分数; - 如果没有CRF层,预测输出根据每个词对应类别的最大值作为输出类别,最后通过多分类交叉熵计算损失进行反向传播;如果有CRF层,通过转移矩阵校正发射分数,然后接5、6;
- 通过维特比解码算法获取最优路径,即获取最优标签序列;
- 计算CRF Loss进行反向传播。
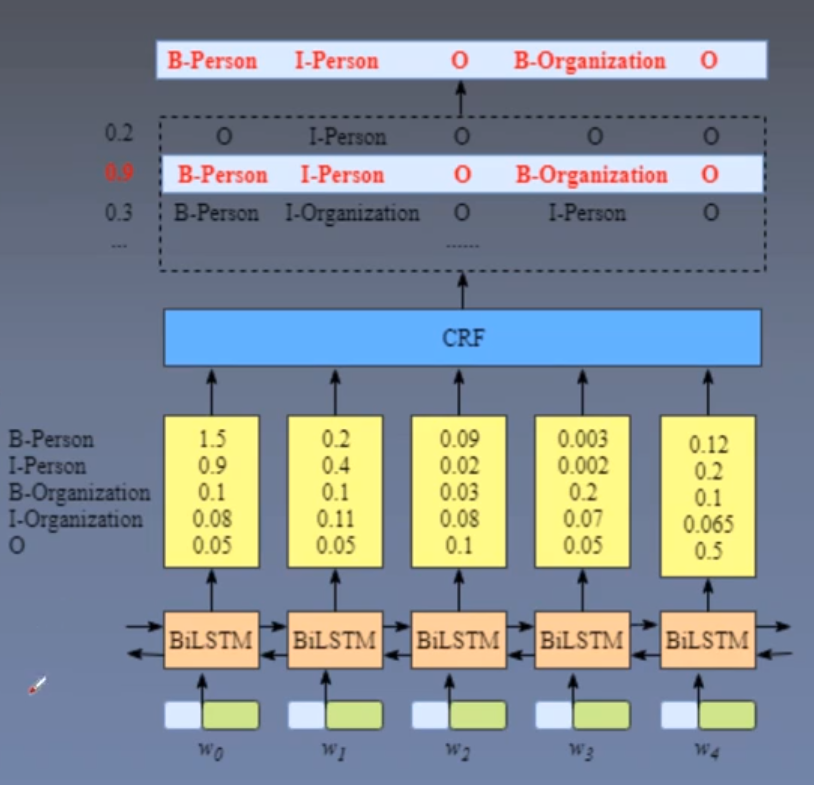
如上图中所示,BiLSTM的输出矩阵(第一列)1.5(B-Person), 0.9(I-Person), 0.1(B-Organization), 0.08(I-Organization),这些分数将是CRF层的输入。
该矩阵对应的值叫做发射分数,用Xiyj代表发射分数,i是单词的位置索引,yj是类别的索引。
例如这里Xi=1,yj=2代表w1单词的B-Organization的发射分数,即
X(w1,B-Organization=0.1)。
这里通过BiLSTM和全连接层已经得到了每个单词对应到各个类别的分数,那么不就取分数最高的类别不就可以了吗,正常情况下当然是可以的,但是会有一些非正常的情况,例如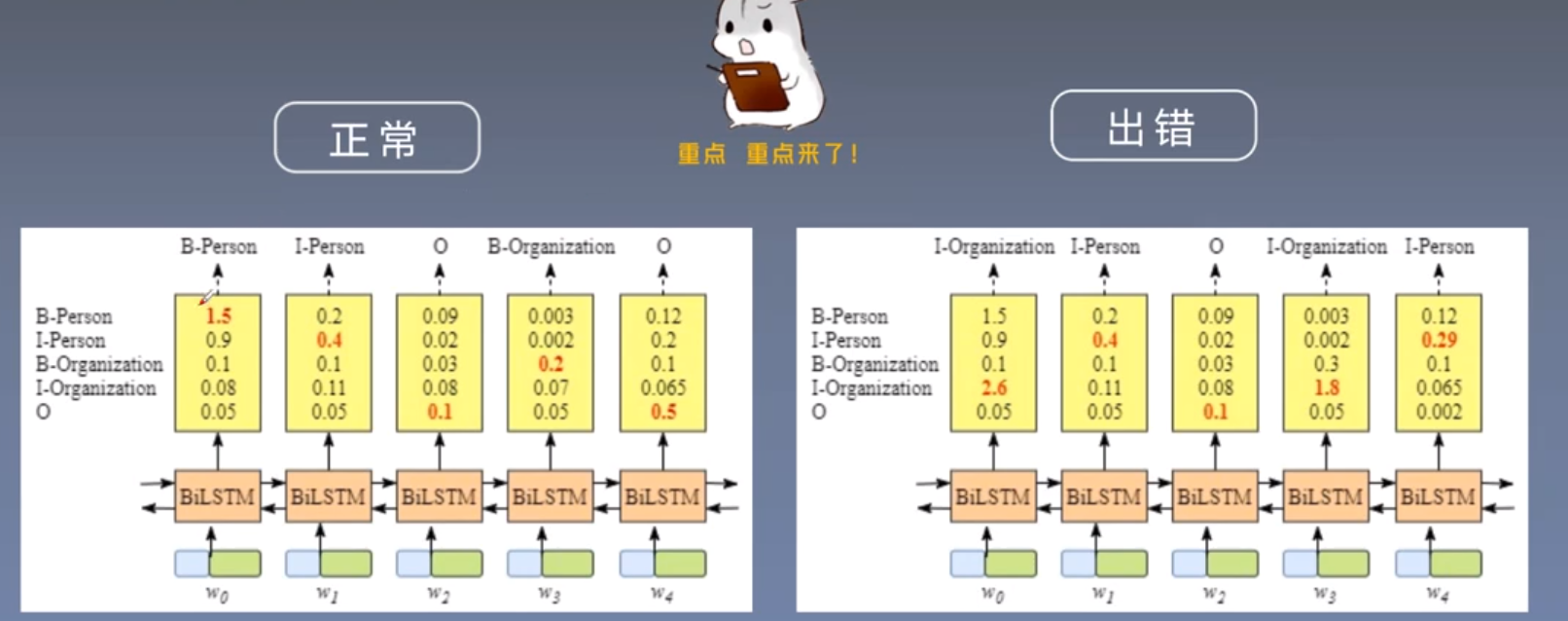
在上图的右侧部分,w0单词分数最大的类别是I-Organization,而I-Organization表示的是组织机构的内部,而w0是第一个单词,所以明显不合理,然后I-Person跟在I-Organization后面也是不合理的,根据BIO标注规则,可以得到以下结论:
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
如果不了解NER的标注规则,如BIO标注的,要先去学习下
但是这一结论,神经网络是不知道的,所以可能会出现图右侧的情况,这就是CRF约束层的作用。
CRF层通过转移分数来校正发射分数中不合理的地方,转移矩阵是BiLSTM-CRF模型的一个参数,可随机初始化转移矩阵的分数,然后在训练中更新。
![]()
图中每一行表示每个标签转移到其他标签的概率,例如第一行,Start转移到B-Person和B-Organization的概率分别为0.8和0.7,表示概率较大,转移到I-Person和I-Organization的概率分别为0.007和0.0008,概率较小(基本不可能),然后将发射分数+转移分数得到打分之和,然后再取最高的分数。
在具体实现时,还有一个叫做路径分数的东西,其就是发射分数+转移分数之和,我们取路径分数最大的一条路径就是最佳标签序列。
CRF损失函数&维特比解码(Viterbi算法)
算法定义:一种用以选择最优路径的动态规划算法,从开始状态后每走一步,记录到达该状态所有路径的最大概率值,最后以最大值为基准继续向后推进,最后再从结尾回溯最大概率,也就是最有可能的最优路径。
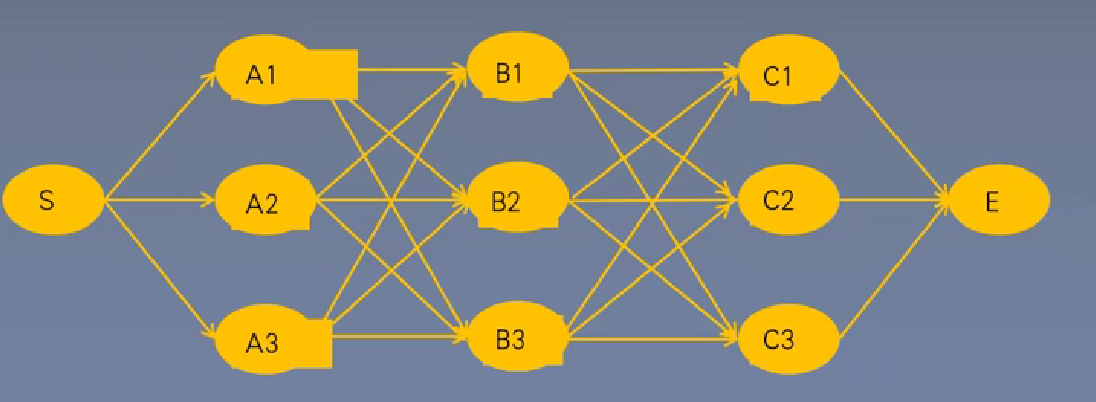
设有N个状态,序列长度为T,因为穷举法是每个时间步都有T种选择,而维特比只需要关注每两个时间步的选择(不需要关注前面的时间步)。
那么穷举法的时间复杂度为N的T次方,而维特比算法的时间复杂度为TxN的平方。
因为在实际任务种,T(序列长度)一般远大于N(类别数量),所以维特比算法的效率更高。
CRF Loss:计算真实路径得分与所有路径得分的比值,CRF损失函数由两部分组成,真实路径的分数和所有路径的总分数,真实路径的分数应该是所有路径中分数最高的。而损失函数是要求loss最小,所以使用负Log函数。

真实路径得分是指标注数据的路径分数
计算当前节点得分的方法
类似维特比解码算法,这里每个节点记录之前所有节点到当前节点的路径总和,最后一步即可得到所有路径的总和。

图中假设有共有两种类别(1和2),共有两个时间步(0时间步和1时间步),previous中的x01代表0时间步类别为1的值,x02代表1时间步类别为2的值,因为是previous可以想象成这个节点之前所有节点到当前节点的路径总和。
obs中的x11代表1时间步类别为1的值,x12代表1时间步类别为2的值,可以理解为发射分数。
而t11代表从上个时间步的1类别转移到当前时间步1类别的转移分数,t12,t21,t22同理。
计算所有路径得分的方法
这里计算从时间步0到时间步1的所有路径得分,因为previous本身就是计算到当前时间步的所有路径得分,所以最后更新previous。

预测

使用PyTorch实现BiLSTM-CRF
1 | # coding=utf-8 |
使用pytorch-crf包来增加CRF层
上面的BiLSTM-CRF的实现是Pytorch官网给出的一个实现方式,对于我们理解BiLSTM-CRF的原理是非常有帮助的,实际上当我们理解了原理之后还可以使用pytorch内置的包来增加CRF层,可以进一步精简代码
首选包安装:pip install pytorch-crf
如果安装后使用报错可以尝试卸载重新安装,或者使用国内镜像安装,我遇到过安装后使用报错,但是卸载重新安装就正常了的情况。
1 | # coding=utf-8 |
这里在模型的forward前向计算部分,其实是我从UER-py的框架代码里借鉴的,重点来看一下损失计算这部分
1 | loss = -self.crf(F.log_softmax(features, 2), targets, mask=tgt_mask, reduction='mean') |
先打印一下features和F.log_softmax(features, dim=2),看一下
1 | tensor([[[ 0.2056, -0.1778, 0.3660, 0.1293, -0.2844], |
features这里是一个(1, 11, 5)的张量,第0维是batch_size大小,第1维是句子长度,第2维是词向量维度。log_softmax是先进行softmax运算再取log,dim=2表示在第2维上进行log_softmax运算。
以[ 0.2056, -0.1778, 0.3660, 0.1293, -0.2844]举例,进行softmax运算
1 | import math |
这里targets和tgt_mask都是(batch_size, seq_length)的size,target就是对应的标签,比如在NER任务中,一个单词对应的是BIO哪个标签,tgt_mask则用来标记一个句子的有效部分,比如一条句子的长度为100个字,在传入模型之前需要统一成长度为300的张量,那么后两百个元素的值都是填充的句子结束标记,这部分在训练时是不需要计算损失的,预测的时候也是不需要关注这部分的值,这里就是通过mask参数来区分句子的有效部分;
另外如果batch_first=False,则mask的size应该为(seq_length, batch_size)。
还可以看到,我在这里加了use-crf参数,即可以通过该参数来指定是否增加CRF层,当没有CRF层时,取预测结果时就是直接对features中每个单词特征的最大值,损失函数也是采用了另外的计算方式(这里的计算方式时借鉴了UER-py中的NER模型,原理思想没怎么搞明白,我想的是应该是可以直接使用多分类交叉熵损失函数的,后面还会介绍使用多分类交叉熵损失函数的版本)。
但是注意,这里不使用CRF层训练,300轮后最后无法正确预测这两个样本的标签,但是通过将学习率由0.01增大至0.1,在300轮后则可以正确预测,推测是学习率太小,300轮并未得到充分学习。之后我将学习率设为0.01。然后将训练轮次增加至1000,顺利得到了正确的预测结果。
BiLSTM-CRF的实现V3版本
在这一版本的实现中,我进行了如下的优化:
- 变量的命名更易于理解;
- 在word_embedding后面增加LayerNorm层;
- 增加dropout层;
- 在训练demo中,采用了更贴近实际情况的方法,即将句子统一成seq_length长度的张量并按照批次传入模型;
- 无crf层的损失函数实现,直接使用nn.CrossEntropyLoss,但是依然要考虑到targets_mask的问题。
1 | # coding=utf-8 |
与V2版本相比,使用CRF层时模型学习的更快更好;不使用CRF层时,对超参数的设置要求更高了,比如损失函数的reduction='sum'时,在学习率0.01和300轮的训练后,模型可以正确预测出这两个样本的标签,而在设置reduction='mean'时,在学习率0.01的情况下,则需要更多的轮次才能正确预测,如果将学习率设置为0.1则可以更快地学习。
关于LSTM的Hidden初始化
通过v1版本的代码可以看到,官方实现时是给lstm网络的输入参数中显示地传入了初始化值,而我们在V2和V3版本中则省去了这一操作,下面就来详细解释一下这一区别是否重要,首先我们需要了解torch.nn.LSTM的主要参数及其含义:
input_size(必需参数):输入数据的特征维度大小。这是输入序列的特征向量的维度。hidden_size(必需参数):LSTM 单元的隐藏状态的维度大小。这决定了 LSTM 层的输出和内部隐藏状态的维度。num_layers(可选参数,默认为 1):LSTM 层的堆叠层数。你可以将多个 LSTM 层叠加在一起,以增加模型的容量和表示能力。bias(可选参数,默认为 True):一个布尔值,确定是否在 LSTM 单元中包含偏置项。batch_first(可选参数,默认为 False):一个布尔值,指定输入数据的形状。如果设置为 True,输入数据的形状应为(batch_size, sequence_length, input_size),否则为(sequence_length, batch_size, input_size)。dropout(可选参数,默认为 0.0):应用于除最后一层外的每个 LSTM 层的丢弃率。这有助于防止过拟合。bidirectional(可选参数,默认为 False):一个布尔值,指定是否使用双向 LSTM。如果设置为 True,LSTM 将具有前向和后向的隐藏状态,以更好地捕捉序列的上下文信息。device(可选参数):指定要在哪个设备上创建 LSTM 层,例如 CPU 或 GPU。dtype(可选参数):指定数据类型,例如torch.float32或torch.float64。return_sequences(可选参数,默认为 False):一个布尔值,指定是否返回每个时间步的输出序列。如果设置为 True,则返回完整的输出序列;否则,只返回最后一个时间步的输出。
通过以上参数来定义一个LSTM网络,在前向传播时需要传入输入数据进行计算

torch.nn.LSTM 层的输入通常是一个包含两个元素的元组 (input, (h_0, c_0)),调用方法为:
output, (h_n, c_n) = torch.nn.LSTM(input, (h_0,c_0))
其中:
(1) input 通常是一个三维张量,具体形状取决于是否设置了 batch_first 参数。输入张量包括以下维度:
批量维度(Batch Dimension):这是数据中的样本数量。如果
batch_first设置为 True,那么批量维度将是第一个维度;否则,批量维度将是第二个维度。序列长度维度(Sequence Length Dimension):这是时间步的数量,也是序列的长度。它是输入序列中数据点的数量。
特征维度(Feature Dimension):这是输入数据点的特征数量。它表示每个时间步的输入特征向量 xt 的维度。
根据上述描述,以下是两种常见的输入形状:
如果
batch_first为 True:- 输入张量的形状为
(batch_size, sequence_length, input_size)。 batch_size是批量大小,表示同时处理的样本数量。sequence_length是序列的长度,即时间步的数量。input_size是输入特征向量的维度。
- 输入张量的形状为
如果
batch_first为 False:- 输入张量的形状为
(sequence_length, batch_size, input_size)。 sequence_length是序列的长度,即时间步的数量。batch_size是批量大小,表示同时处理的样本数量。input_size是输入特征向量的维度。要注意的是,这只是输入的形状,LSTM 层的参数(例如
input_size和hidden_size)必须与输入形状相匹配。根据你的具体任务和数据,你需要将输入数据整理成适当形状的张量,然后将其传递给torch.nn.LSTM层以进行前向传播。
- 输入张量的形状为
(2) (h_0, c_0):是包含初始隐藏状态和初始细胞状态的元组。
h_0:是初始隐藏状态,其形状为(num_layers * num_directions, batch_size, hidden_size)。num_layers是 LSTM 层的堆叠层数,num_directions是 1 或 2,取决于是否使用双向 LSTM。c_0:是初始细胞状态,其形状也为 `(num_layers * num_directions
上面关于h_0、c_0的初始化size描述的非常清楚,如果你在网络计算时并未传入这两个参数,其实通过查看源代码会发现在lstm的内部同样会初始化这两个参数,区别是使用的是torch.zero,即都初始化为0,而v1版本中则是使用的torch.randn,所以说具体如何初始化效果会更好还是需要自行测试。
参考博文链接:https://blog.csdn.net/m0_48241022/article/details/132775071
应用到命名实体识别
上面对于BiLSTM模型的原理和实现我们已经基本掌握,接下来就是应用到命名实体识别的实际任务中。这部分内容会在后续的github项目中展示,其实整体是借鉴的UER-py这个项目,只不过改写了部分代码。
这里我仅将我的实验结果进行展示,对于模型的评估一共有两个指标,一种是根据实体数量评估,一种是根据单条数据评估(单条数据可能包含多个实体)。
实验数据一:
embedding_size=256, hidden_size=512(单向), use_crf=True, layer_nums=2
按照实体数量评估:F1=99.0%,按照单条数据评估:F1=95.7%
2600条测试数据,大约有26000个实体,1%的实体预测不准确,大概也有260个实体,最多可能导致260条数据提取不准确。
参数量:14,963,378,权重大小:57MB
实验数据二:
embedding_size=256, hidden_size=512(单向), user_crf=False, layer_nums=2
按照实体数量评估:F1=95.3%,按照单条数据评估:F1=78.4%
2600条测试数据,大约有26000个实体,4.7%的实体预测不准确,大概有1222个实体,最多可能导致1222条数据提取不准确。
可以看到效果相比使用CRF确实下降很多。
参数量:14,955,098,权重大小:57MB,与使用CRF几乎相同
实验数据三:
embedding_size=512, hidden_size=768(单向), use_crf=True, layer_nums=2
按照实体数量评估:F1=99.4%,按照单条数据评估:96.5%
2600条测试数据,大约有26000个实体,0.6%的实体预测不准确,大概也有156个实体,最多可能导致156条数据提取不准确。
参数量:33,009,842,权重大小:125MB
实验数据四:
embedding_size=512, hidden_size=768(单向), use_crf=False, layer_nums=2
按照实体数量评估:F1=96.8%,按照单条数据评估:F1=82.3%
2600条测试数据,大约有26000个实体,3.2%的实体预测不准确,大概有832个实体,最多可能导致832条数据提取不准确。
参数量:33,001,562,权重大小:125MB,与使用CRF几乎相同
实验数据五:
embedding_size=384, hidden_size=768(单向), use_crf=True, layer_nums=2
参数量:29,518,770,权重大小:112MB
按照实体数量评估:F1=99.4%,按照单条数据评估:96.9%
相比embedding_size=512,参数量略有减少,但是实际效果一致,甚至在以单条数据评估的基础上,取得了0.4%的提升。
batch_size=16可以再试一下
实验数据六:
embedding_size=256, hidden_size=512(单向), user_crf=True, layer_nums=3
参数量:21,263,026,权重大小:81MB
按照实体数量评估:F1=99.4%,按照单条数据评估:96.7%
单条数据预测速度:0.024s
后面更多的对比实验我以表格的形式展示更方便查看,就不再文字罗列,注意以下训练数据采用的优化器统一为SGD、学习率统一为0.001。
| num_layers | embedding_dim | hidden_size | use_crf | 参数量 | 权重大小/MB | F1 | F2 |
|---|---|---|---|---|---|---|---|
| 2 | 256 | 512 | False | 14,955,098 | 57MB | 95.3% | 78.4% |
| 2 | 256 | 512 | True | 14,963,378 | 52MB | 99.0% | 95.7% |
| 3 | 256 | 512 | True | 21,263,026 | 81MB | 99.4% | 96.7% |
| 2 | 384 | 768 | True | 29,518,770 | 112MB | 99.4% | 96.7% |
| 3 | 384 | 768 | True | 43,686,834 | 166MB | 99.3% | 96.1% |
| 2 | 512 | 768 | False | 33,001,562 | 125MB | 96.8% | 82.3% |
| 2 | 512 | 768 | True | 33,009,842 | 125MB | 99.4% | 96.5% |
| 2 | 512 | 1024 | True | 48,792,754 | 186MB | 99.4% | 96.7% |
| 2(use_pre) | 768 | 768 | True | 39,991,986 | 152MB | 99.3% | 96.1% |
| 2 | 768 | 768 | True | 39,991,986 | 152MB | 99.3% | 96.4% |
| 2(use_pre) | 384 | 768 | True | 23,311,794 | 89MB | 99.4% | 96.7% |
关于以上实验得到的结论:
- 根据实验一、二和实验三、四两组实验对比显示,使用CRF层可以得到大幅度的效果提升,并且参数量几乎不变,但是使用CRF的训练速度整体要比不使用CRF训练速度慢3~5倍,embedding_size=512,hidden_size=768的配置下,不使用CRF训练100轮大约需要23小时(单个2080Ti);
- 在一定范围内,增加embedding_dim、hidden_size和layers可以提高模型精度,但是代价是训练和预测速度的下降;embedding_size=512,hidden_size=768的配置下其平均单条数据的预测速度为:
use_crf=False, 0.011s;use_crf=True, 0.025s; - 当模型增大到一定程度之后,实际效果反而会下降,例如第4、5行的对比;
- 第9行特别注释的use_pre是使用的bert的预训练embedding,注意是仅使用embedding层,实际验证效果并不明显;
- 最后一行使用word2vec按照单个字符分割训练了一个词向量,因为词表大小变小了,所以embedding层的参数量减少了很多,最终模型大小也降低了。
这个项目其实还有一些待尝试的方法,例如采用分词的方式去训练词向量,然后输入到NER模型中训练,不过选取哪一种分词库效果更好是需要去对比的;此外,可能还需要根据业务特点,自己去建立一个业务词典,保证这些词不会被分词工具给切割;以及是否可以提出针对此业务的更好地分词方法也是一个可以深入研究的点。
下一个项目我会利用tranformer encoder作为NER的encoder来进一步实验。
补充一些实验数据
使用上述训练得到的模型在真实数据集上做测试时,发现一些抽取异常的问题(并不是因为自动生成数据的方法有问题,只是抽取有问题的情形并不包含在生成数据的模板内,即模型未见过此类数据,也可以理解为模型泛化能力还有所欠缺)。针对抽取异常的数据进行人工修正后作为训练数据参与训练,包括566条训练数据和59条测试数据。
合并到之前的训练集后重新训练,下面依然设置了两组对照实验:
使用BERT的词表且未对词向量进行训练:num_layers=2,embedding_dim=384,hidden_size=768,F1值为98.8%,F2值为93.6%(可以看到相比原来准确率有所下降,原因尚不清楚)。
如果单独评测上面标注的59条测试数据,其F1值为94.7%,F2值为48/59=81.4%
使用word2vec训练词向量并生成词表,num_layers=2,embedding_dim=384,hidden_size=768,F1值为99.3%,F2值为96.2%。
对59条标注的测试数据的评测结果为:F1=96.4%,F2值为50/59=84.7%。
现在可以看到通过word2vec学习词向量对准确率有明显提升,是否可以考虑:
- 扩充词向量学习的数据集;
- 使用BERT微调获取词向量,后续可能需要一定的放缩才能直接用;
- 使用GPT微调获取词向量。
作为消融实验:可以通过仅训练566条数据,对59条测试数据准确率来判断生成的数据是否对模型学习有积极效果。