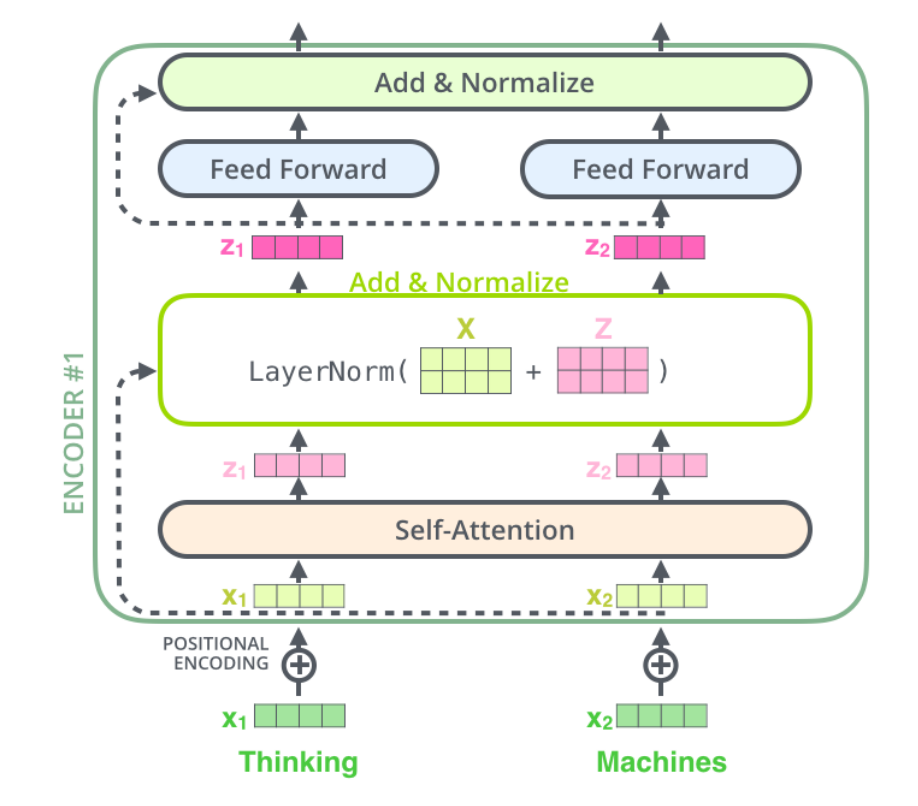
Transformer block
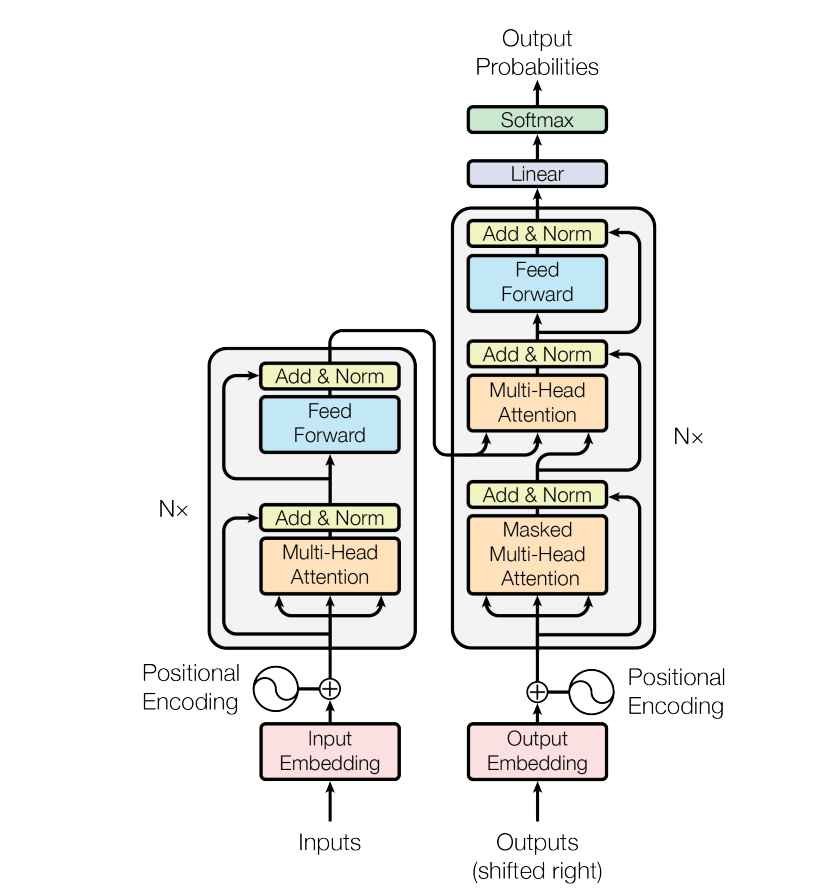
这个模型结构分为左右两个部分,因为原文中是用 Transtormer 来做翻译任务的,大家可能知道通常我们做翻译任务的时候,都使用 Encoder-Decoder 的架构来做。这里面的左侧对应着 Encoder ,右侧就是 Decoder。Encoder 本质目的就是对 input 生成一种中间表示,Decoder 目的就是对这种中间表示做解码,生成目标语言的 output。大家会发现两边的结构基本上是一致的,为了着重的研究 Transformer 结构,我们分别介绍Encoder和Decoder部分。
大家会在图中看到,这里有个 N× 的符号,这表示了左/右侧的结构可以被 N 次堆叠,这就像是我们在使用神经网络的时候,可以 N 次堆叠 layer 一样,通常我们把这样的一种由多个 layer 组成的模块叫做 block,这种 block 就是一种比 layer 更大规模的可复用单元。那么,接下来我们把重点放到 Transformer Block 上。
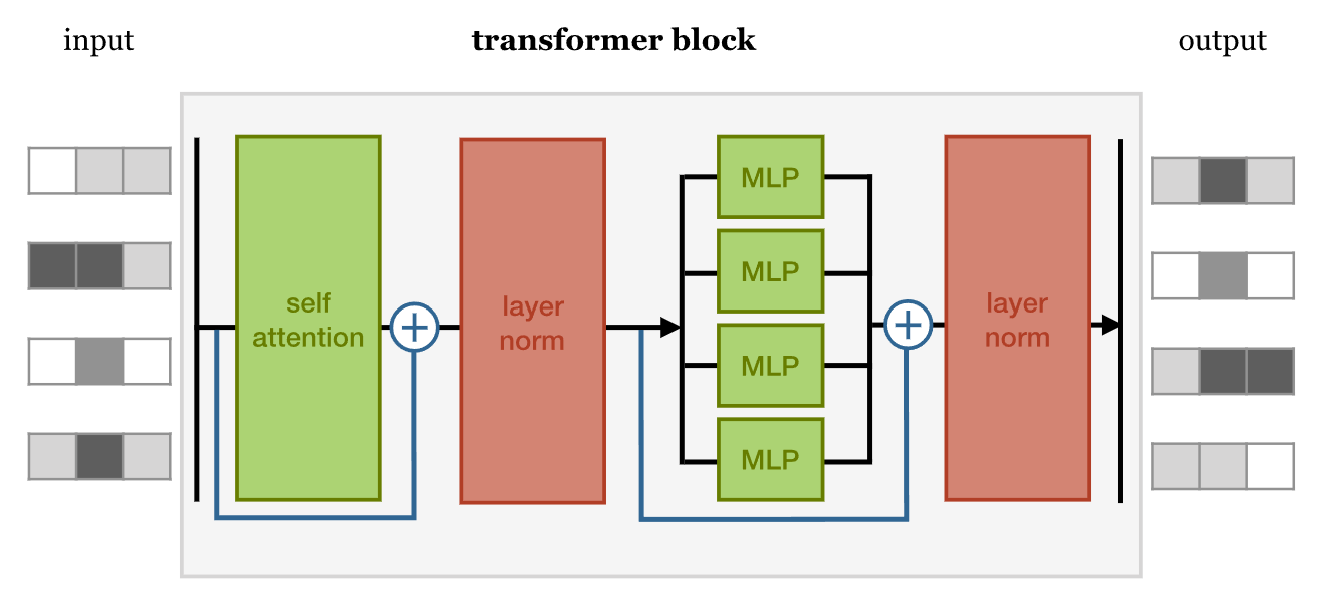
在这样一个block中,是由几个重要的组件构成的:
- Self-attention layer
- Normalization layer
- Feed forward layer
Another normalization layer
在这样四个组件中的两个 Normalization layer 之前,使用了残差网络(
Residula connections)进行了连接。实际上,这几个组件之间的顺序并没有被完全的定死,这里面最重要的事情是,要联合使用 Self-attention 和 Feed forward layer,并且要在它们之间增加 Normalization 和 Residual connections。
position encoding
通过使用 Transformer 我们可以得到一个对于输入信息的 embedding vector,但是这里大家可能也会发现,我们并没有利用好序列的输入顺序。比如说 we are happy 和 are we happy ,它们得到的 vector 是一样的。显然,这并不是希望看到的。所以,我们要给模型增加捕获序列顺序的能力。我们应该怎么做呢?
办法也很简单,我们创建一个和输入序列等长的新序列,这个序列里包含序列中的顺序信息,我们把这个序列和原有序列进行相加,从而得到输入到 Transformer 的序列。那应该怎样表示序列中的位置信息呢?
在transformer原论文中,作者借助编码学的知识,使用巧妙的数学公式直接计算序列的位置信息:
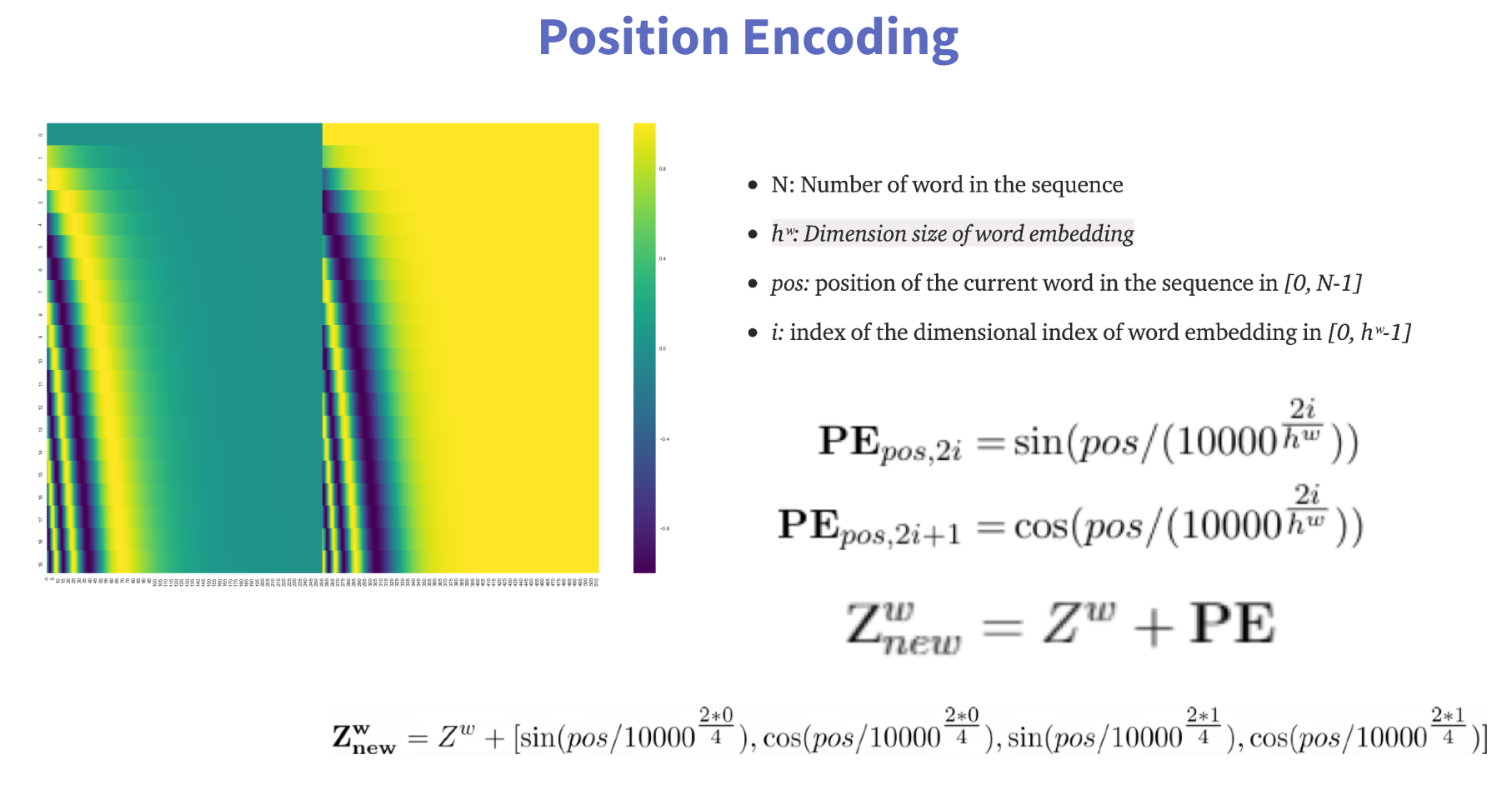
N: 序列中单词的数量;
hw:词嵌入的维度;
pos:当前单词在序列中的位置[0, N-1];
i:在词嵌入维度中的位置[0, hw-1]。
Zw是原来的词嵌入向量,将计算得到的位置向量与Zw相加得到新的Zw。
最后一行的例子假设词嵌入维度为4
词嵌入第0号位置(偶数),2i=0, i=0;
词嵌入第1号位置(奇数),2i+1=1,i=0;
词嵌入第2号位置(偶数),2i=2, i=1;
词嵌入第3号位置(奇数),2i+1=3, i=1。
为什么有效?
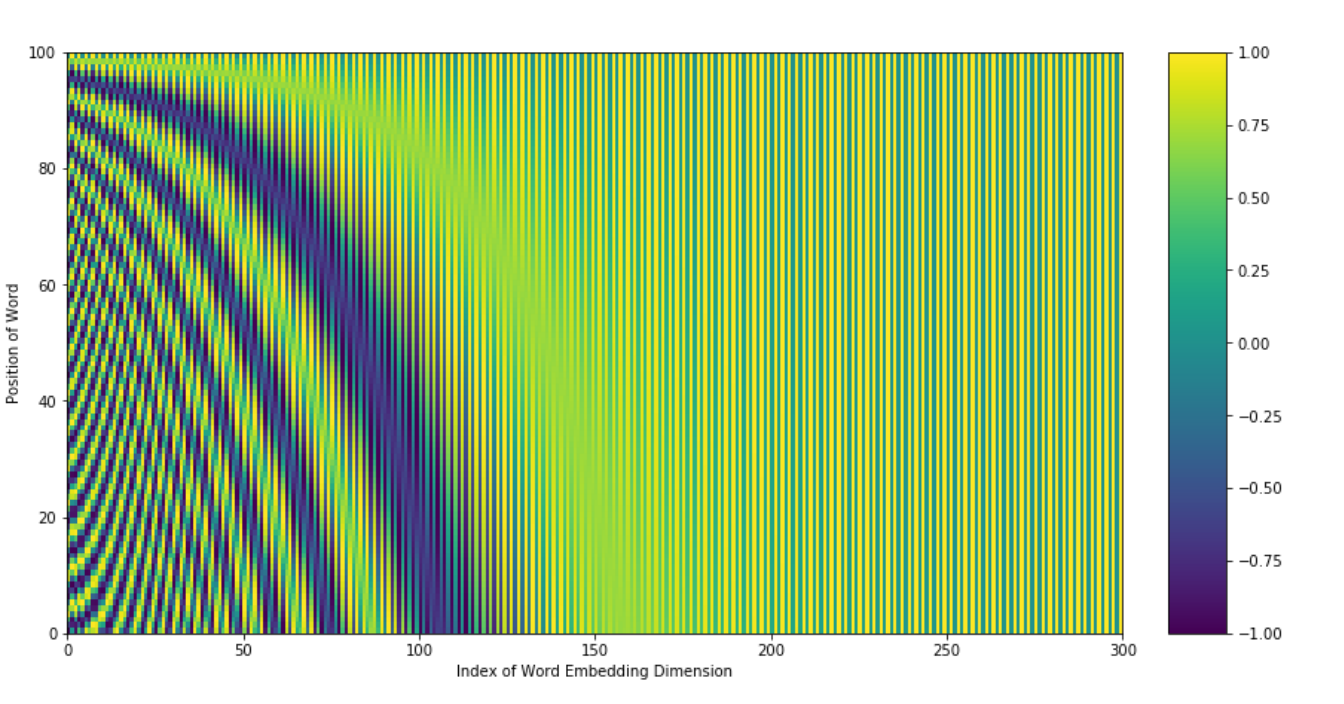
这张图是上述公式的可视化,横坐标是词嵌入维度位置,纵坐标是单词在句子中的索引位置。然后我们选取竖直方向的几个点位,即词嵌入维度分别为0、100、200和300的位置:
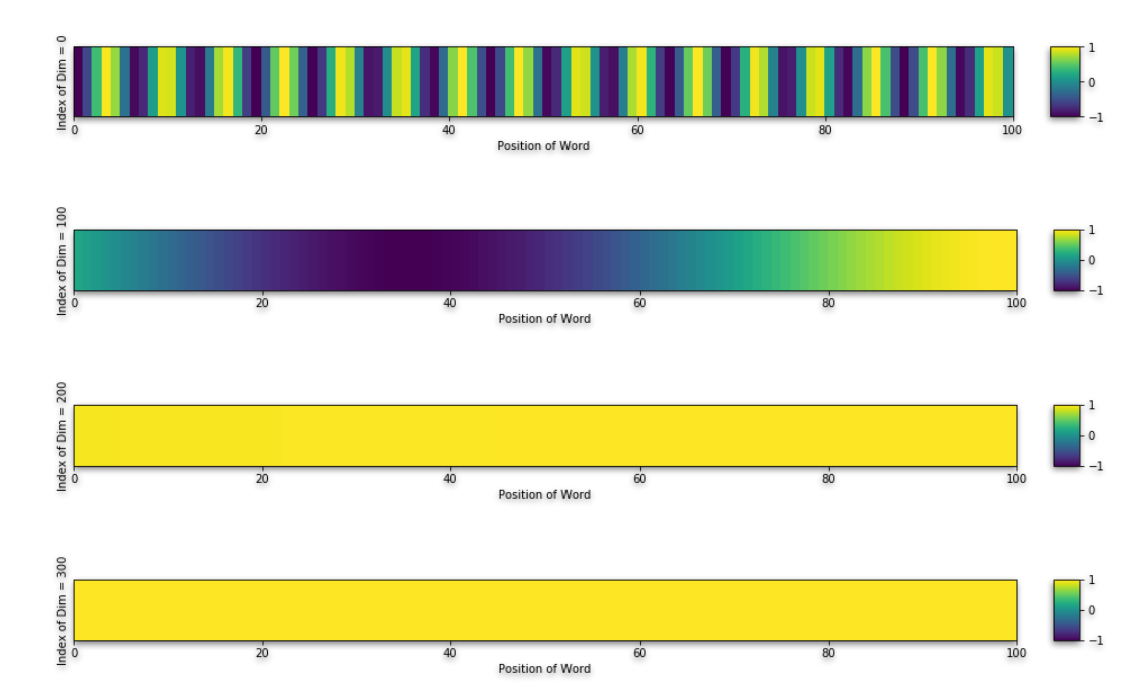
通过这样的对比结果我们发现,在词嵌入低维处,有更多位置相关的信息,维度越高,不同位置单词的值越趋于一致,即不改变高维处的值,高维处依然是用来表示语义相关的信息。
接下来在选取水平方向的几个点位,即单词在句子中0、25、50、75和100的位置:
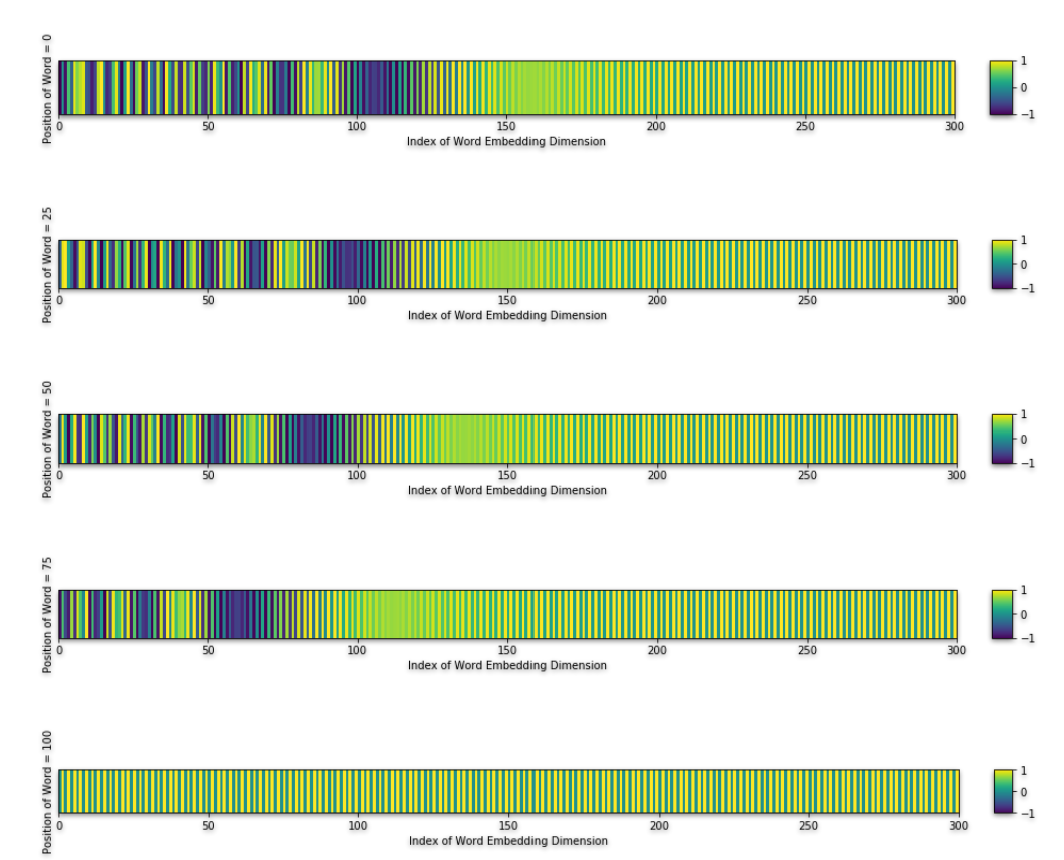
不同的位置其表示是不一样的,也就是说这个公式既满足了可以在低维中加入位置信息,也使得不同的位置有不同的表示。
position embedding

Residual Network
使用残差网络的原因:网络退化(network Degradation)
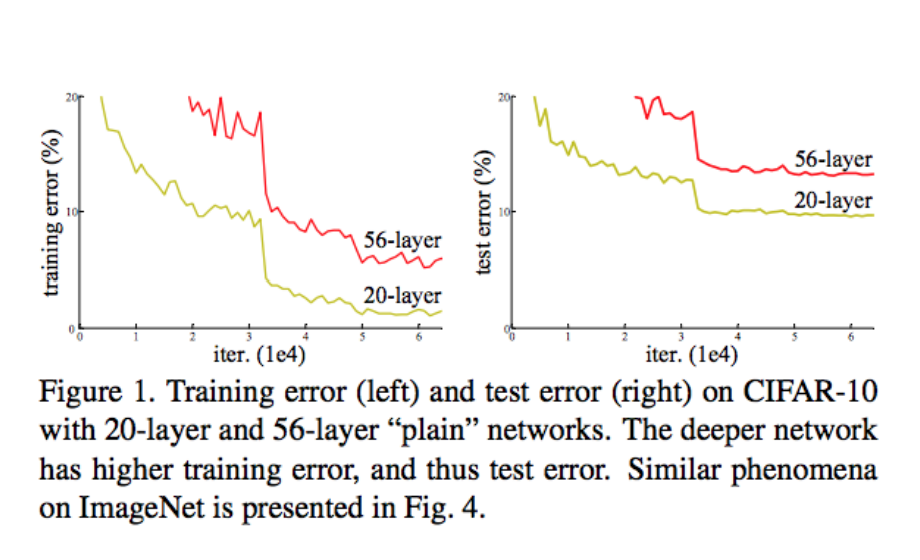
如果网络层数过多,会出现信息传递的衰减。
通过增加通道将前面的层和后面的层直接连接,使得前面层的相关信息可以直接传给后面的层就是残差网络的基本思想:
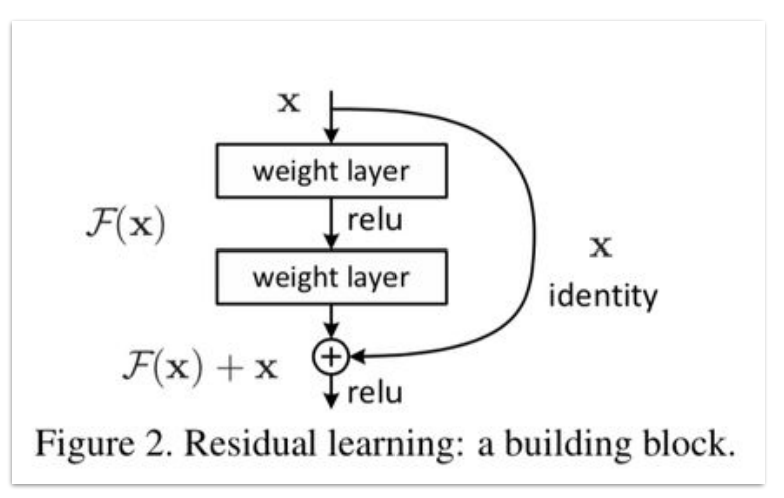
transformer中的残差连接
Layer Norm
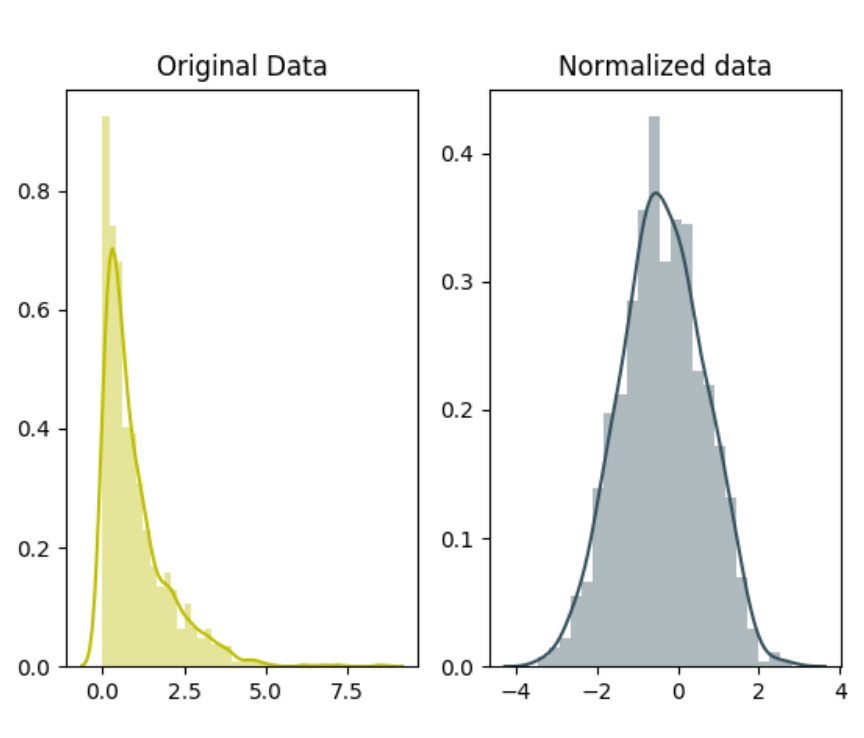
独⽴同分布(independent and identically distributed,简称为 i.i.d)
在把数据喂给机器学习模型之前,“⽩化(whitening)”是⼀个重要的数据预处理步骤。⽩化⼀般包含两个⽬的:
(1)去除特征之间的相关性 —> 独⽴;
(2)使得所有特征具有相同的均值和⽅差 —> 同分布。
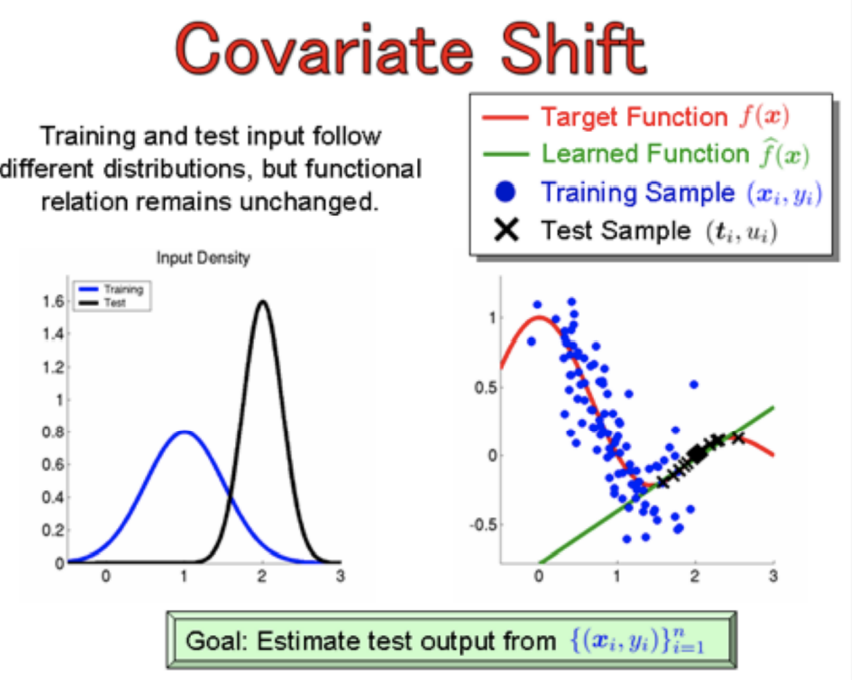
在机器学习中,训练集和测试集的数据分布不一致,就会出现Covariate Shift现象;而Internal Covariate Shfit是因为层与层之间的数据分布不一致。
ICS带来的问题:
其⼀,上层参数需要不断适应新的输⼊数据分布,降低学习速度。
其⼆,下层输⼊的变化可能趋向于变⼤或者变⼩,导致上层落⼊饱和区,使得学习过早停⽌。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
常见的解决办法就是Batch Normalization, BN ⽐较适⽤的场景是:每个 mini-batch ⽐较⼤,数据分布⽐较接近。 在进⾏训练之前,要做好充分的 shuffle,否则效果会差很多。
Layer Norm针对单个训练样本进⾏,不依赖于其他数据,因此可以避免 BN 中受 mini-batch 数据分布影响的问题,可以⽤于 ⼩mini-batch场景、动态⽹络场景和 RNN,特别是 ⾃然语⾔处理领域。此外,LN 不需要保存 mini-batch 的均值和⽅差,节省了额外的存储空间。
另外,因为自然语言处理中句子的长度不一致,存在较多的\
FFN(Feed Forward Network)
引入非线性