LatticeLSTM原理解读与模型实现
深入剖析文章:一文详解中文实体识别模型 Lattice LSTM - 知乎 (zhihu.com)
最容易想到同时也是最简单的词信息利用方法就是直接拼接词表征与字向量或者直接拼接词表征与LSTM的输出。16年的论文《A Convolution BiLSTM Neural Network Model for Chinese Event Extraction》就采用了这样的方法构建了中文事件抽取模型。
Lattcie LSTM的实现方式是怎么样的呢?
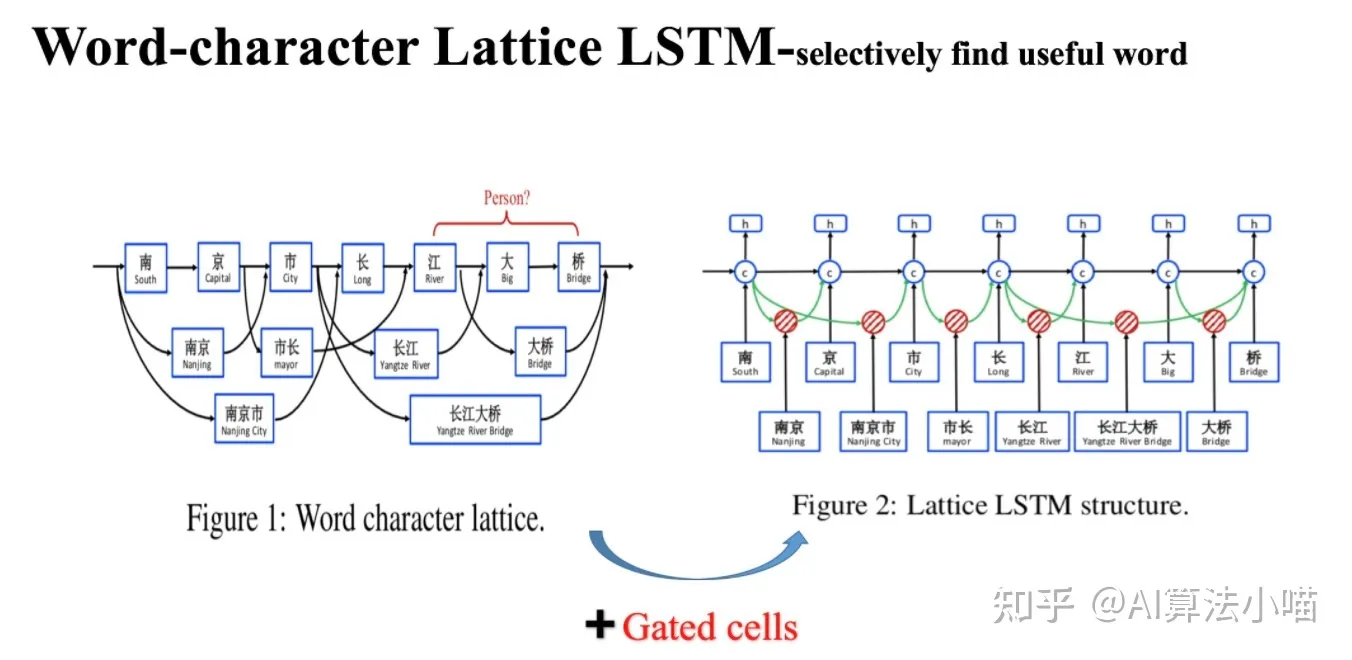
Lattice LSTM 模型结构如上图右侧所示。在正式开始介绍 Lattice LSTM 前,我们先来看看上图左半部分。
(1) Lattice LSTM 名字来由
我们可以发现在上图左侧所示网络中,除主干部分 基于字的LSTM 外,还连接了许多「格子」,每个「格子」里各含有一个潜在的词,这些潜在词所含有的信息将会与主干LSTM中相应的 Cell 融合,看起来像一个「网格(Lattice)」。所以论文模型的名字就叫做 Lattice LSTM,也就是有网格结构的LSTM模型。
(2) 词典匹配获得潜在词
网格中的这些潜在词是通过匹配输入文本与词典获得的。比如通过匹配词典, “南京市长江大桥”一句中就有“南京”、“市长”,“南京市”,“长江”,“大桥“,“长江大桥”等词。
疑问一:词典是哪里来的呢?
解疑问:从预训练的词向量文件中读取(Lattice LSTM中是ctb.50d.vec文件)
(3) 潜在词的影响
首先,“南京市长江大桥” 一句的正确结果应当是 “南京市-地点”、“长江大桥-地点”。如果我们直接利用 Character-based model 来进行实体识别,可能获得的结果是:“南京-地点”、“市长-职务”、“江大桥-人名”。现在利用词典信息获得了文本句的潜在词:“南京”、“市长”,“南京市”,“长江”,“大桥“,“长江大桥” 等潜在词。其中,“长江”、“大桥” 与 “长江大桥” 等词信息的引入有利于模型,可以帮助模型避免犯 “江大桥-人名” 这样的错误;而 “市长” 这个词的引入却可能会带来歧义从而误导模型,导致 “南京-地点”,“市长-职务” 这样的错误。
换句话说,通过词典引入的词信息有的具有正向作用,有的则不然。当然,人为去筛除对模型不利的词是不可能的,所以我们希望把潜在词通通都丢给模型,让模型自己去选择有正向作用的词,从而避免歧义。Lattice LSTM 正是这么做的:它在Character-based LSTM+CRF的基础上,将潜在词汇信息融合进去,从而使得模型在获得字信息的同时,也可以有效地利用词的先验信息。
模型细节
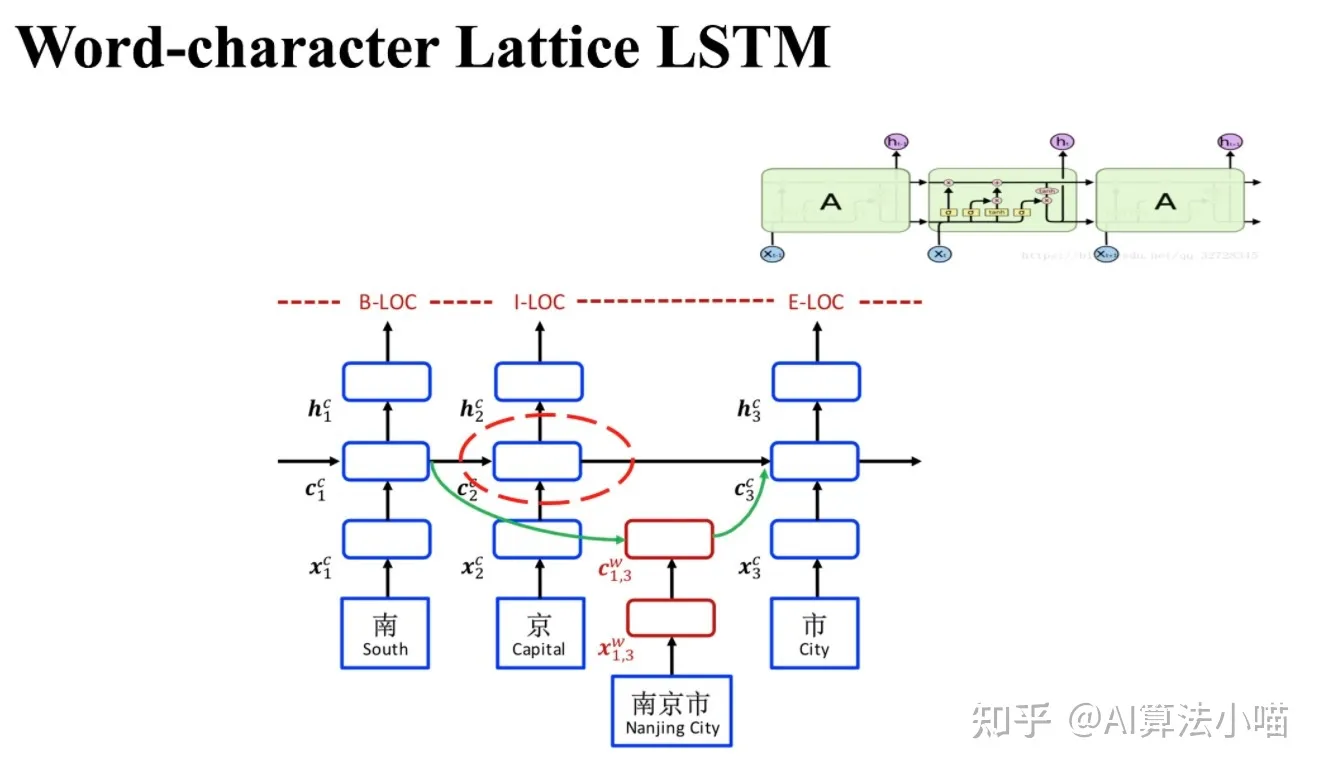
如上图所示,Lattice LSTM模型的主干部分是基于字的LSTM-CRF(Character-based LSTM+CRF):
- 若当前输入的字在词典中不存在任何以它结尾的词时:主干上Cell之间的传递就和正常的LSTM一样。也就是说,这个时候Lattice LSTM退化成了基本LSTM。
- 若当前输入的字在词典中存在以它结尾的词时:需要通过红色Cell引入相关的潜在词信息,然后与主干上基于字的LSTM中相应的Cell进行融合。
接下来,我们先简单展示下 LSTM的基本单元,再介绍 红色Cell,最后再介绍信息融合部分。
LSTM的基本单元
略
红色cell
前面我们提过「如果当前字在词典中存在以它结尾的词时,需要通过红色Cell引入相关潜在词信息,与主干上基于字的LSTM中相应Cell进行融合」。以下图中 “市” 字为例,句子中潜在的以它结尾的词有:”南京市”。所以,对于”市”字对应的Cell 而言,还需要考虑 “南京市” 这个词的信息。
红色Cell的内部结构与主干上LSTM的Cell很类似。接下来,我们具体来看下 红色Cell 内部计算过程。
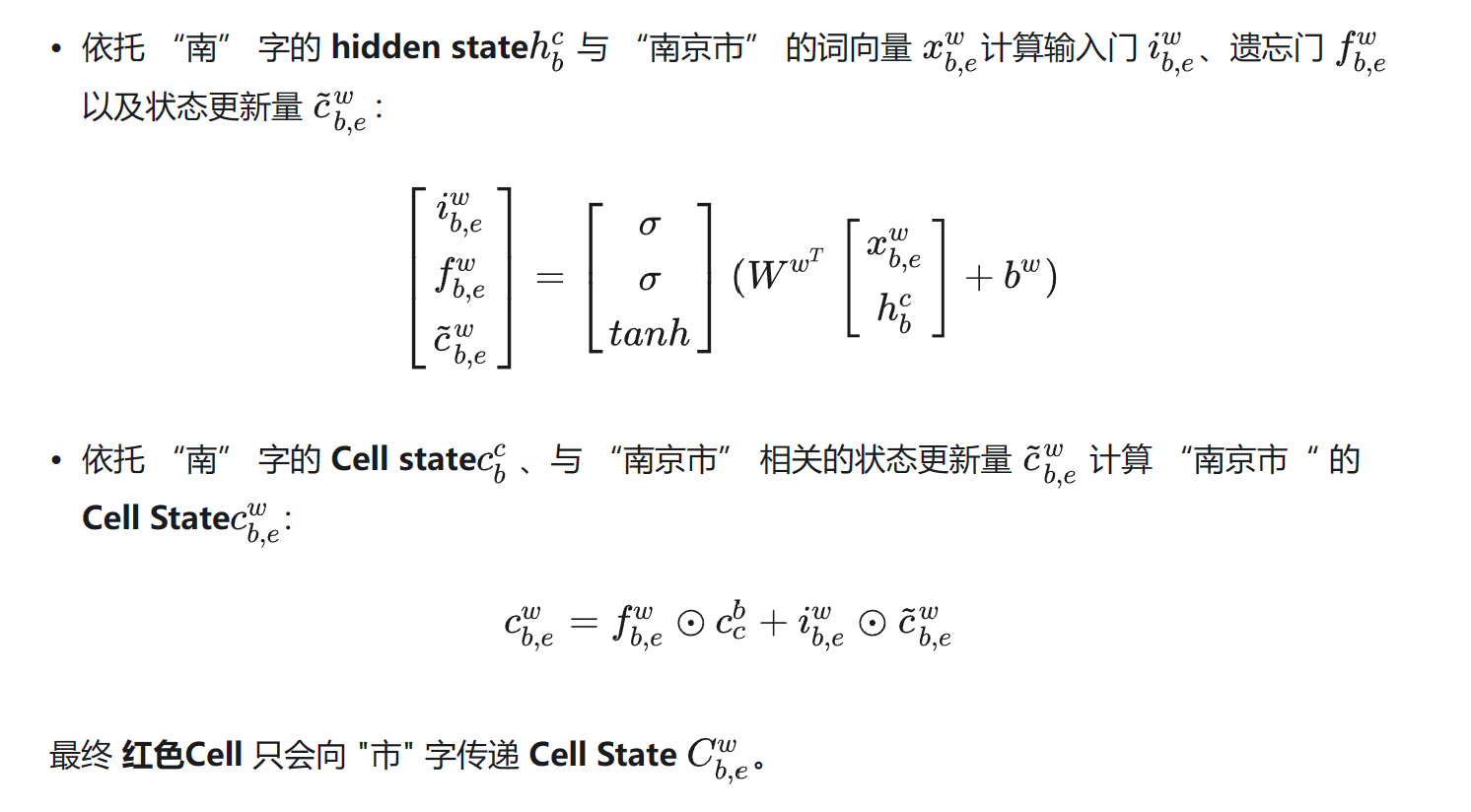
(1) 红色Cell 的输入
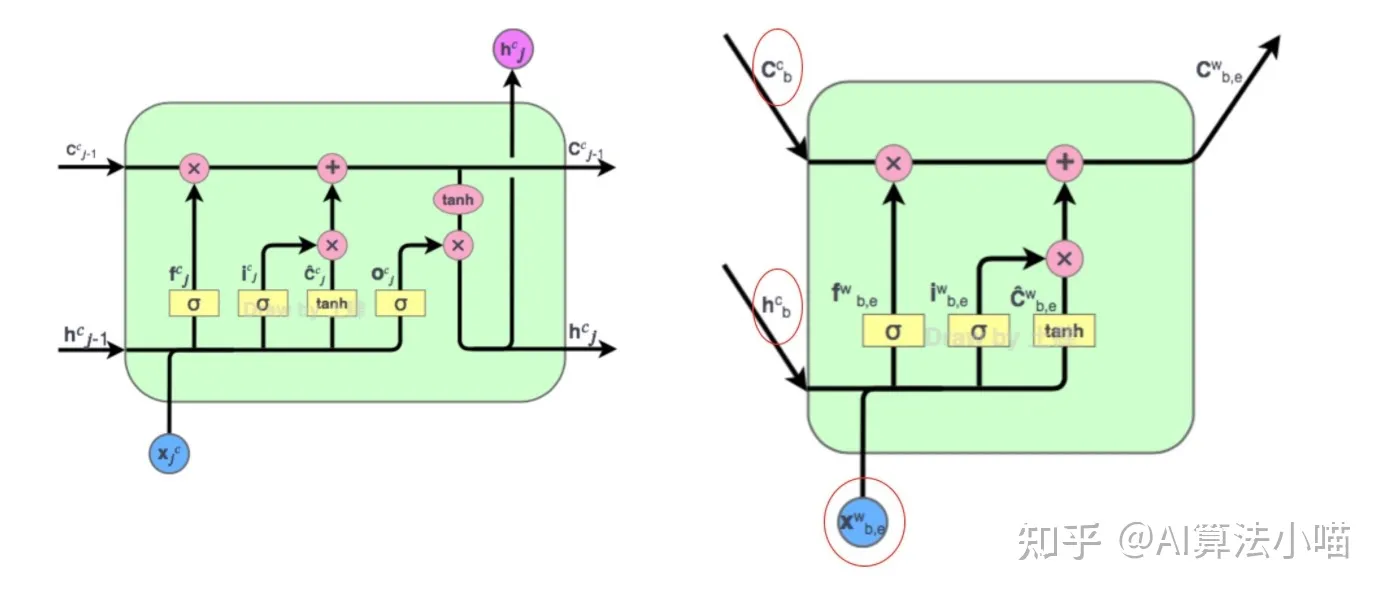
与上图左侧LSTM的Cell对比,上图右侧 红色Cell 有两种类型的输入:
- 潜在词的首字对应的LSTM单元输出的Hidden State(上图右侧h) 以及Cell State(上图右侧c)
- 潜在词的词向量(上图右侧x)。
(2) 红色Cell 的输出
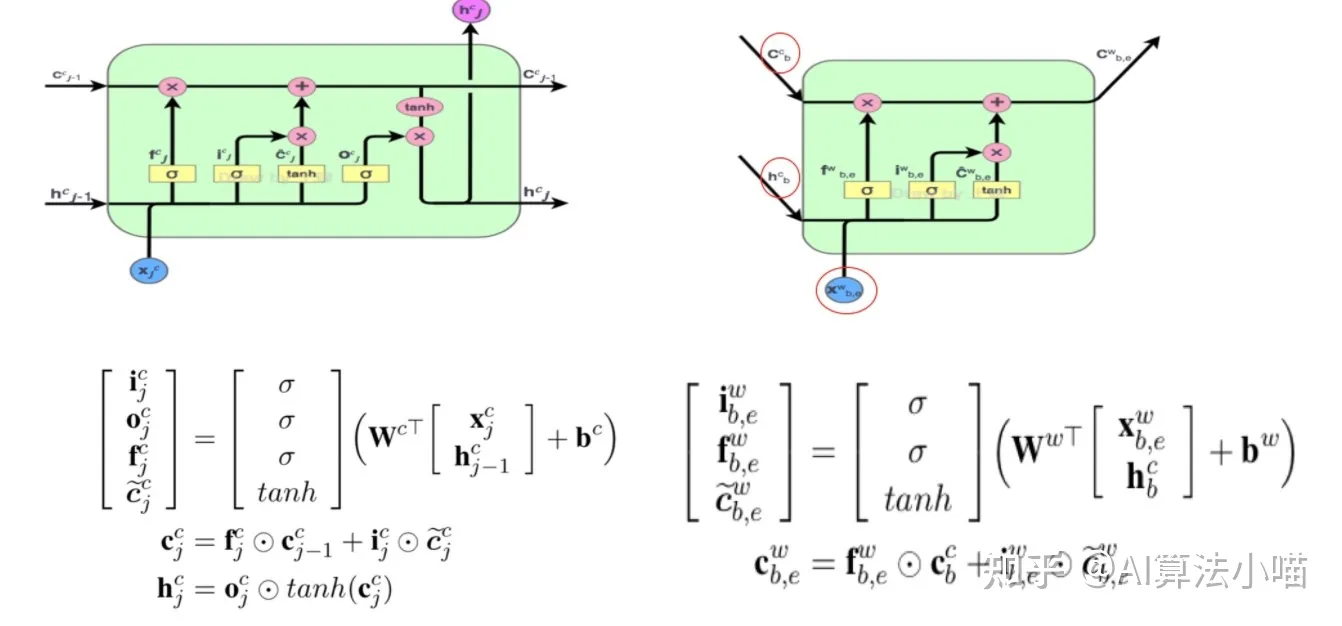
可以发现,因为序列标记是在字级别,所以与左侧 LSTM 的 Cell 相比,红色Cell 没有输出门,即它不输出hidden state。以“市”字为例,其潜在词为“南京市“,所以 ℎ、c来自于”南”字, x 代表“南京市”的词向量,红色Cell 内部具体计算过程如下所示:
信息融合

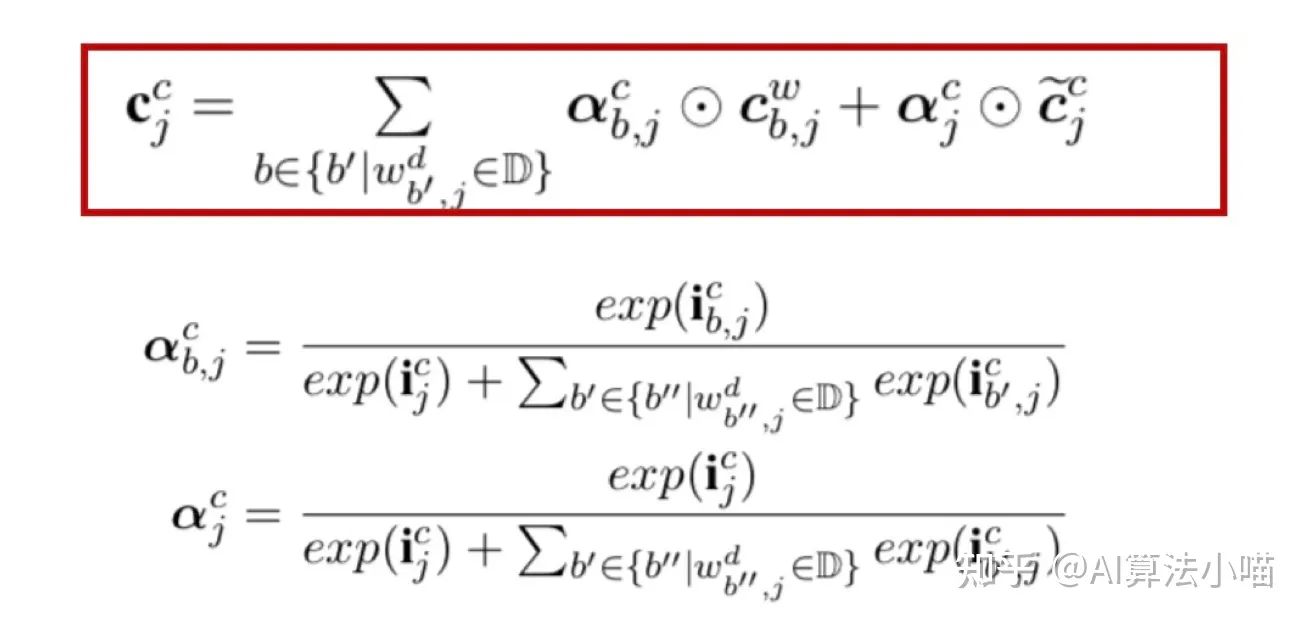
简单地说,就是当前字相应的输入门和所有以当前字为尾字的候选词的输入门做归一计算出权重,然后利用计算出的权重进行向量加权融合。

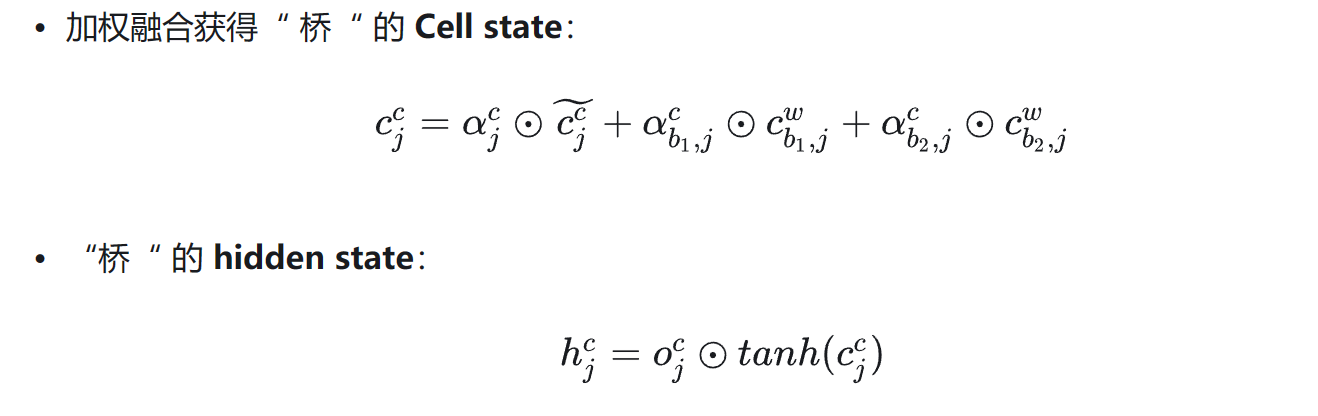
疑问二:所以原来LSTM cell中Ct的计算方法里的遗忘门已经不需要了?
解疑问:如果当前字存在潜在词,那么遗忘门部分确实不需要了,状态C的计算方式发生改变(因为不使用遗忘门,所以也没有使用上一个状态C,这里其实是Lattice LSTM的缺点,会造成信息丢失);如果当前字不存在潜在词,那么计算方式还是与LSTM Cell保持一致。
反过来理解这个公式:h的计算还是和LSTM的一致,输出门依然保持不变,只不过状态C的计算方式有所改变,首先C是由一系列输入门和其潜在词的Cell State C计算得到的。
其次,这个外部的输入门是额外定义的,由当前字的词向量和其潜在词的Cell State计算得到;
最后,潜在词的Cell State就是红色cell的输出(具体看红色cell输出部分)。
项目实战
LatticeLSTM项目地址:GitHub - jiesutd/LatticeLSTM: Chinese NER using Lattice LSTM. Code for ACL 2018 paper.
这个项目是python2.7写的,需要改成python3的版本;(或者是pytorch较低的版本,用法需要改为较高的版本)
如:
print函数语法规则
str类型不用加decode
open文件增加encoding参数
字典迭代使用items()替代iteritems()
xrange使用range替代
pickle.dump和pickle.load必须是二进制文件
修改张量,需要加with torch.no_grad(),并且删除.data,例如
1
2
3
4
5For example, change:
x.data.set_(y)
to:
with torch.no_grad():
x.set_(y)import _pickle as pickle
【琐碎】Python3安装/运行cPickle以及cPickle的使用-CSDN博客
下载character embedding(gigaword_chn.all.a2b.uni.ite50.vec)和word embedding(ctb.50d.vec)放到data目录
map方法的使用
1
2word_seq_lengths = torch.LongTensor(map(len, words))
max_seq_len = word_seq_lengths.max()这里应该是为了获取words中最长的句子,等价的写法是这样的(上述是简写)
1
word_seq_lengths = torch.LongTensor(map(lambda x: len(x), words))
但是这样写还是有问题,TypeError: new(): data must be a sequence (got map)
这就是python版本的问题,在python2.x版本,map返回列表,在python3.x版本,map返回迭代器,所以这里应该改为
1
word_seq_lengths = torch.LongTensor(list(map(lambda x: len(x), words)))
torch.split方法
1
torch.split(wh_b + wi, split_size=self.hidden_size, dim=1)
split_size参数已废弃
参数:
- tesnor:input,待分输入
- split_size_or_sections:需要切分的大小(int or list )
- dim:切分维度
- output:切分后块结构
- 当split_size_or_sections为int时,tenor结构和split_size_or_sections,正好匹配,那么ouput就是大小相同的块结构。如果按照split_size_or_sections结构,tensor不够了,那么就把剩下的那部分做一个块处理。
- 当split_size_or_sections 为list时,那么tensor结构会一共切分成len(list)这么多的小块,每个小块中的大小按照list中的大小决定,其中list中的数字总和应等于该维度的大小,否则会报错(注意这里与split_size_or_sections为int时的情况不同)。
next方法
1
2seq_iter = enumerate(scores)
_, inivalues = seq_iter.next()在python3.x中,.next()方法已废弃,可以改成next(seq_iter)
tensor.item()
1
2sample_loss += loss.data[0]
total_loss += loss.data[0]使用tensor.item()来处理只有1个元素的张量
1
2sample_loss += loss.item()
total_loss += loss.item()
data_initialization
build_alphabet(alphabet字母表): 根据数据集建立语料库,包括
label_alphabet:所有标签的集合,Alphabet类的实例,如[‘B-PER’, ‘E-PER’, …]
word_alphabet:所有文字的集合,Alphabet类的实例,如[‘\</unk>‘, ‘陈’, ‘元’, …]
biword_alphabet(两个连续的字组成的词,很多时候可能并不是真正意义上的的汉语词语):例如句子”陈元呼吁加强国际合作推动世界经济发展”,会得到以下二元词的词表
[‘\</unk>‘, ‘陈元’, ‘元呼’, ‘呼吁’, ‘吁加’, ‘加强’, ‘强国’, ‘国际’, ‘际合’, ‘合作’, ‘作推’, ‘推动’, ‘动世’, ‘世界’, ‘界经’, ‘经济’, ‘济发’, ‘发展’, ‘展-null-‘]
char_alphabet:在中文字符级别的NER任务中与word是一致的,因为word本来就是单个字;
Alphabet类中有一个列表用于保存得到的标签、文字和二元词等,还有一个字典保存了相应的文字在列表中的索引,还封装了一些方法方便对列表和词典的写入和读取;
build_gaz_file(Gazetteer地名录):加载预训练好的词向量(ctb.50d.vec,词向量维度=50,总共704368个字符或词语,按照论文中的记录其中单个字、两个字和三个字的词语数量分别是5.7k,分别为291.5k和278.1k,也就是说也包含更多字数的词语),并储存到self.gaz(这里应该理解为建立词典库)
self.gaz依赖Gazetteer类,其中有个trie属性(self.trie = Trie()),其中保存了TrieNode(保存了类似子词的东西,用于build_gaz_alphabet)
build_gaz_alphabet:建立gaz_alphabet,即找到了所有可能的词语(具体逻辑就是利用上面trie属性保存的词典,然后调用gaz.enumerateMatchList,这里面调用的又是trie.enumerateMatch方法)
这个Trie的类是Lattice LSTM中关于词这块的核心代码,所以单独拎出来研究下
1 | import collections |
Python中通过Key访问字典,当Key不存在时,会引发‘KeyError’异常。为了避免这种情况的发生,这里使用collections类中的defaultdict()方法来为字典提供默认值
defaultdict是内置数据类型dict的一个子类,基本功能与dict一样,只是重写了一个方法missing(key)和增加了一个可写的对象变量default_factory。
语法格式:
1 | collections.defaultdict([default_factory[, …]]) |
- 如果default_factory属性为None,就报出以key作为遍历的KeyError异常;
- 如果default_factory不为None,就会向给定的key提供一个默认值,这个值插入到词典中,并返回;
这里TrieNode类有两个属性,属性is_word是标记当前这个Node是否为词(准确的说应该是是否这个词会以这个Node为结束词),children属性就是一个defaultdict,并且默认值为类本身,即当children获取不到指定的key时,则插入这个key,且值为这个类,并返回这个key对应的类。
Trie类的root属性就是TrieNode类,insert时就是遍历一个word的每一个字符,然后存储到root中,如果是多个字符的,就形成了一种嵌套关系,例如中国人
“中”是最外层Node,这个Node的children是”国”这个Node,”国”的children是”人”,然后给”人”打上标记is_word=True。
gaz_alphabet也是Alphabet类的实例,例如句子”陈元呼吁加强国际合作推动世界经济发展”,根据gaz保存的预训练的词表,计算出这个句子中哪些可能是词,从而得到如下结果:
[‘陈元’, ‘呼吁’, ‘吁加’, ‘加强’, ‘强国’, ‘国际’, ‘合作’, ‘推动’, ‘世界’, ‘经济’, ‘发展’]
generate_instance_with_gaz
read_instance_with_gaz:最终生成两个列表instance_texts和instance_ids,其分别又包含5个列表
instance_texts.append([words, biwords, chars, gazs, labels])
instance_ids.append([word_Ids, biword_Ids, char_Ids, gaz_Ids, label_Ids])
即每句话的word、biword、char、词和标签以及对应的id
words、biwords、chars和labels倒是没啥特别的,逻辑与上面build alphabet是一致的,只不过上面是把训练集、测试集、验证集中所有句子得到的结果汇总到一起,而这里每个句子得到一个列表而已,重要的是gazs,部分核心代码如下
1 | w_length = len(words) |
enumeraterMatchList实现如下:
1 | def enumerateMatchList(self, word_list): |
根据代码可以理解,gazs首先是和句子长度(len(word))保持一致,然后每个元素是一个列表,这个列表的内容是以这个字为开始的所有可能的词(这个字在word中的索引,对应这个match_list在gaz中的索引);gaz_list的长度依然与句子长度一致,其每个元素也是一个列表,但是这个列表中,又包含两个列表,第1个列表是这些词在gaz_alphabet中的id,第2个列表是每一个词的长度。
例如句子:新华社华盛顿0月00日电(记者翟景升)
对应的word_list为:[‘新’, ‘华’, ‘社’, ‘华’, ‘盛’, ‘顿’, ‘0’, ‘月’, ‘0’, ‘0’, ‘日’, ‘电’, ‘(’, ‘记’, ‘者’, ‘翟’, ‘景’, ‘升’, ‘)’]
gazs为:[[‘新华社’, ‘新华’], [‘华社’], [‘社华’], [‘华盛顿’, ‘华盛’], [‘盛顿’], [], [‘0月’], [], [‘00’], [‘0日’], [], [], [], [‘记者’], [], [‘翟景升’, ‘翟景’], [‘景升’], [], []]
gaz_ids为:[[[13, 14], [3, 2]], [[15], [2]], [[16], [2]], [[17, 18], [3, 2]], [[19], [2]], [], [[20], [2]], [], [[21], [2]], [[22], [2]], [], [], [], [[23], [2]], [], [[24, 25], [3, 2]], [[26], [2]], [], []]
build_xx_pretrain_emb
build_pretrain_embedding:加载预训练好的embedding(’gigaword_chn.all.a2b.uni.ite50.vec’)
gigaword_chn.all.a2b.uni.ite50.vec每行是字符串(使用空格分隔,split之后size是embedding_dim+1),首号元素是字符或词,后面的embedding_dim个元素是表征这个字符或词语的向量;
最终转换成一个pretrain_emb(二维向量,size=(word数量, 相应word对应的embedding))
实际上word2vec模型训练完之后保存的直接就是这么一个二维向量
ps:不过build_biword_pretrain_emb时,bichar_emb是None,其词向量是随机初始化的
1 | np.random.uniform(-scale, scale, [1, embedd_dim]) |
build_gaz_pretrain_emb时,加载的词向量是’ctb.50d.vec’,不过格式与上面所说的是一致的
batchify_with_label
此方法传入的是generate_instance_with_gaz方法获取的instance_ids,不过并非全部,而是一个批次大小的instance_ids,其size为(batch_size, 5, sentence_length)。sentence_length是这一批次中最长句子的长度,其他的句子会自动补齐至这一长度。
返回以下参数:
- gaz_list:gaz_list其实没有什么改变,只不过在列表最外层保存了volatile参数,返回的gaz_list最外层包含两个元素,第一个还是词的ids,第二个元素是volatile的值(True or False),这个参数用于决定pytorch的Variable是否不需要保留记录用的参数(实际上已废弃,使用with torch.no_grad()代替,主要目的是在evaluate和predict时,不需要保留梯度,因为不需要反向传播),True表示不需要,False表示需要。
- batch_word:返回的size为(batch_size, sentence_length),句子中的字在词表中的id;
- batch_biword:返回的size为(batch_size, sentence_length),句子中的二元词在二元词表中的id;
- batch_wordlen:记录这一批次句子的长度(多少个字)
- batch_wordrecover:未知
- batch_char:返回的size为(sentence_length, batch_size)
- batch_charlen:
- batch_charrecover:未知
- batch_label:返回的size为(batch_size, sentence_length),句子中每个字的标签在所有类别中的id;
- mask :返回的size为(batch_size, sentence_length),为1的部分表示这个句子的实际有效部分
SeqModel
主模型:BiLSTM_CRF
主模型包含两个子模型:BiLSTM模型和CRF模型
BiLSTM子模型中又包含三个子模型:CharBiLSTM、CharCNN、LatticeLSTM 模型。
但是charBiLSTM和CharCNN只在use_char=True时,才会使用,当char_features=CNN时,会使用CharCNN,当char_features=LSTM时,会使用CharBiLSTM
1 | def neg_log_likelihood_loss(self, gaz_list, word_inputs, biword_inputs, word_seq_lengths, char_inputs, char_seq_lengths, char_seq_recover, batch_label, mask): |
模型在训练时,调用model.neg_log_likelihood_loss,里面分别调用BiLSTM的get_output_score、crf的neg_log_likelihood_loss和_viterbi_decode。
模型的预测时,调用model.forward(),其实里面就是去掉了crf.neg_log_likeihood_loss这一步骤,因为不需要计算损失进行反向传播。
outs的输出size为(batch_size, sentence_length, label_size)(label_size意思是标签的总数量)
这里计算损失是调用了CRF类里面自定义的neg_log_likelihood_loss方法,其本质上应该与我之前使用的torchcrf包一样
1 | loss = -self.crf(F.log_softmax(features, 2), targets, mask=targets_mask, reduction='mean') |
下一步骤的解码(预测)与我之前使用的torchcrf包的decode应该本质也是一样的
1 | pred = self.crf.decode(features, mask=targets_mask) |
BiLSTM
BiLSTM模型中包含两个embedding(biword_embedding只有在use_bigram=True时才有用)
1 | self.word_embeddings = nn.Embedding(data.word_alphabet.size(), self.embedding_dim) |
默认的embedding_dim是Word和char的embedding(测试时发现use_char=False,即char_hidden_dim=0)
lstm_input = self.embedding_dim + self.char_hidden_dim
如果使用bi-gram(测试时发现use_bigram=False)lstm_input += data.biword_emb_dim
BiLSTM模型中包含一个forward_lstm和一个backward_lstm,均是LatticeLSTM
1 | self.forward_lstm = LatticeLSTM(lstm_input, lstm_hidden, data.gaz_dropout, data.gaz_alphabet.size(), data.gaz_emb_dim, data.pretrain_gaz_embedding, True, data.HP_fix_gaz_emb, self.gpu) |
最后还有一个线性层
self.hidden2tag = nn.Linear(data.HP_hidden_dim, data.label_alphabet_size)
1 | def get_output_score(self, gaz_list, word_inputs, biword_inputs, word_seq_lengths, char_inputs, char_seq_lengths, char_seq_recover): |
这里get_lstm_features返回的lstm_out的size为(batch_size, sent_len, hidden_dim),是前向lstm的hidden_out和后向lstm的hidden_out拼接而成,单个方向的lstm的输出则为(sentence, hidden_dim/2)。
LatticeLSTM
LatticeLSTM中也有一个预训练的词向量
1 | self.word_emb = nn.Embedding(word_alphabet_size, word_emb_dim) |
这里的pretrain_word_emb在BiLSTM初始化LatticeLSTM时传入的是pretrain_gaz_embedding
LatticeLSTM模型中包含两个子层:WordLSTMCell、MultiInputLSTMCell
1 | self.rnn = MultiInputLSTMCell(input_dim, hidden_dim) |
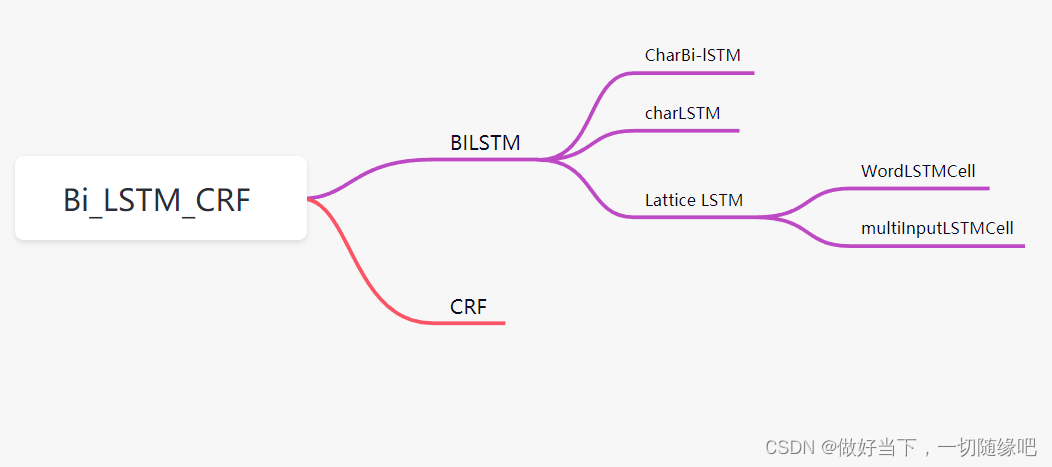
这里WordLSTMCell对应上面模型细节中的红色Cell部分;
MultiInputLSTMCell对应上面模型细节中的信息融合部分。
BiLSTM中的forward_lstm和backward_lstm都是LatitceLSTM,forward方法如下:
1 | def forward(self, input, skip_input_list, hidden=None): |
第一次进入forward方法时,hidden是None,hx, cx被初始化为(batch_size, hidden_dim)的张量,每个元素值均为0。后续hx, cx取自传入的hidden。
input对应的句子每个字的embedding,size为(batch_size, sentence_length, embedding_dim);
skip_input得到的就是generate_instance_with_gaz里gaz_ids,是一个三维的列表(函数注释里写的也很清晰)
input后续经过transpose(1, 0)的操作,变成(sentence_length, batch_size, embedding_dim),按照句子长度,每次输入到rnn中(batch_size, embedding_dim)大小
这里还有一个反向的backward lstm(其self.left2right=False),简单理一下他的计算原理,还是以这个句子举例
新华社华盛顿0月00日电(记者翟景升)
对应的word_list为:[‘新’, ‘华’, ‘社’, ‘华’, ‘盛’, ‘顿’, ‘0’, ‘月’, ‘0’, ‘0’, ‘日’, ‘电’, ‘(’, ‘记’, ‘者’, ‘翟’, ‘景’, ‘升’, ‘)’]
gazs为:[[‘新华社’, ‘新华’], [‘华社’], [‘社华’], [‘华盛顿’, ‘华盛’], [‘盛顿’], [], [‘0月’], [], [‘00’], [‘0日’], [], [], [], [‘记者’], [], [‘翟景升’, ‘翟景’], [‘景升’], [], []]
gaz_ids为:[[[13, 14], [3, 2]], [[15], [2]], [[16], [2]], [[17, 18], [3, 2]], [[19], [2]], [], [[20], [2]], [], [[21], [2]], [[22], [2]], [], [], [], [[23], [2]], [], [[24, 25], [3, 2]], [[26], [2]], [], []]
在反向lstm网络的计算时,首先将这里的gaz_ids(也就是skip_input)进行如下转换操作
1 | def convert_forward_gaz_to_backward(forward_gaz): |
[‘新华社’, ‘新华’]对应的id是[13, 14],在句子skip_input中的位置本来是”新”字的位置,即[0]号元素,经过转换后
[‘新华社’]换到了”社”字的位置,即[2]号元素,[‘新华’]则换到了”华”字的位置,即[1]号元素;
即现在的可选词的id所在的位置不是词的开始字位置了,而是词的结束字位置;
接下来按照句子顺序进行计算时,是逆序计算
1 | if not self.left2right: |
与前向计算的原理类似(这里先看一下后面WordLSTMCell的计算说明更好理解),前向计算时是在”新”字时,会计算出”新华社”和”新华”的Cell值,之后在计算到”华”时融合”新华”的Cell值,在计算到”社”时融合”新华社”的Cell值,这里反向计算时(句子逆序),是会先计算到”社”字,这时同样也会先计算出”新华社”的Cell值,等到计算”新”字时将Cell值融合计算。
这步操作猛地很难理解,一直在讲的是如果当前字在词典中存在以它结尾的词时,需要通过红色Cell引入相关潜在词信息,与主干上基于字的LSTM中相应Cell进行融合,这里”新”又不是词的末尾,”社”才是词的末尾,怎么计算逻辑不符合这一规则?这时候需要把脑子倒过来思考,毕竟句子是逆序的,在逆序情况下,其实是认为”社华新”是一个词,”新”就是词的末尾,是不是突然悟了!
最后返回时,再把逆序计算得到的结果反转过来
1 | if not self.left2right: |
MultiInputLSTMCell
self.rnn对应的MultiInputLSTMCell,其forward方法如下:
1 | def forward(self, input_, c_input, hx): |
wh_b = torch.addmm(bias_batch, h_0, self.weight_hh)
意思是h_0与weight_hh进行矩阵点乘,之后再加上bias_batch,与我们熟知的神经元计算方法一致;
torch.mm的功能是矩阵点乘,即左行乘右列
然后这里在计算时分两种情况:
c_input是空列表(每个句子的首字进去计算时肯定是空列表,或者不存在以这个字为末尾的词时也是空列表),就是进行正常的lstm网络的cell计算,但是这里的遗忘门(f)的计算方法是使用1-输入门(i),不确定这一原理是什么;(这种情况下LatticeLSTM的计算退化为基本的LSTM)
c_input是非空列表,其每一个元素是以这个字为结尾的词的embedding,其元素个数记为c_num,即这个句子中有c_num个以这个字为结尾的词,而每个元素的size为(batch_size, hidden_size);
在这里,首先利用input和c_input_var计算出alpha_wi和alpha_wh,然后两者相加进行sigmoid得到alpha(这几个步骤对应额外的输入门计算部分)
接下来要做的是加权所有可选词的输入门(alpha)和当前字的输入门(i),这里alpha的尺寸为(c_num, hidden_size),即有几个可选词,c_num则为几,所以下面这几个步骤是计算权重值
1
2
3
4alpha = torch.exp(torch.cat([i, alpha], 0))
alpha_sum = alpha.sum(0)
# alpha = softmax for each hidden element
alpha = torch.div(alpha, alpha_sum)再然后利用当前字的输入门权重(alpha中的一部分)*当前字的更新候选值(g)加上每一个可选词的输入门权重(alpha中的其余部分)*相应可选词的cell state(c_input_var,size(0)为可选词的个数),最终得到C_1
1
2merge_i_c = torch.cat([g, c_input_var], 0)
c_1 = merge_i_c * alpha最后得到h1的值(在c_input非空的情况下,c_0并没有使用,所以这里算信息丢失)
WordLSTMCell
self.word_rnn对应的是WordLSTMCell,其forward方法如下:
1 | def forward(self, input_, hx): |
这个里面的计算相对来说比较容易理解,对照红色cell部分的输出公式,基本就能理解;
但是需要注意的是输入参数的含义,input_并非是句子中当前字的embedding,而是以这个字为开始的所有可能词的embedding,hx中的h_0和c_0则来自这个字经过lstm之后的输出h和c。
前面我们提过如果当前字在词典中存在以它结尾的词时,需要通过红色Cell引入相关潜在词信息,与主干上基于字的LSTM中相应Cell进行融合,所以得到的输出c_1并不是用于这里输入的字(input_是以这个字为开始的所有可能词的embedding)的信息融合的,而是在这里先计算出来,保存到input_c_list中,当计算到这个词的末尾的字时,再拿出来进行信息融合。
例如”中国人”,这里输入的是”中国人”的embedding,hx中的h_0和c_0则是”中”字得到的状态值,所以这里计算得到的c_1并不是给”中”字用的,而是后续给”人”用的。
CRF模型
Lattice LSTM源代码中,CRF模型是自行实现的,其主要实现了以下方法:
_viterbi_decode:解码,其中有一行代码可能是错了
1 | # bat_size * to_target_size |
原来的代码是view成(batch_size, tag_size, 1),但是这样到最后会导致partition_history中首号元素的尺寸与其余元素的尺寸不一致,从而 torch.cat(partition_history, 0)会报错,这里这样改了一下就好了,但是不确定这样改对不对。
forward:方法定义错误,缺失了mask参数(不过在代码中倒是没有调用forward方法,而是直接调用了._viterbi_decode方法)
原来的代码是:
1 | def forward(self, feats): |
应该修改为:
1 | def forward(self, feats, mask): |
这样修改完之后,调用crf._viterbi_decode的地方可以改为self.crf()(即调用forward方法)
neg_log_likelihood_loss:计算损失,分别调用_calculate_PZ和_score_sentence
模型评估
acc:统计模型每一个字符的输出与真实标签之间的准确率,一般会得到一个比较高的值
p、r、f则是以一个实体作为基本单位评估模型
main.py中的main函数,status=”train”,表示训练,会同时针对训练集做训练,验证集和测试集做验证和测试;如果仅评估验证集或测试集,可以设置status=”dev”or”test”,如果需要将预测结果保存下来,status=”decode”,并设置–output,即要保存的文件地址和名称。
1 | python main.py --status decode --output data/predict.txt --loadmodel data/model/saved_model.lstmcrf.model --raw data/demo.test.char |
关于数据集的标注规范问题
Lattice LSTM项目支持两种标注规范的数据集训练,BIO和BIOES(GitHub主页上写推荐使用BIOES),其实关于这两种标注规范没啥可说的,领域内的人都非常清楚,但是这个项目还涉及到BMES的问题,所以简单介绍下更好理解:
BIO标注法:B-begin,I-inside,O-outside,B-X 代表实体X的开头, I-X代表实体的结尾 O代表不属于任何类型的;
BIOES标注法:B-begin,I-inside,O-outside,E-end,S-single,B 表示开始,I表示内部, O表示非实体 ,E实体尾部,S表示该词(当然如果中文字符NER的话,就是单个字)本身就是一个实体;
但是通过看LatticeLSTM的源代码和训练数据样例是区分两种标注schema,即BMES和BIO
BMES实际上是一种中文分词的标注方法:
B表示一个词的词首位值,M表示一个词的中间位置,E表示一个词的末尾位置,S表示一个单独的字词。
训练数据样例的标签也是采用的M而并非I,而且有O的出现,所以可以理解采用的标注方法为BMOES,只是用M代替了I,本质上与BIOES是一样的(网上经常会有人问BMES标注能不能做NER,我的答案是能做,但是要做思想上的转化即M代替I,并引入O标签,BMOES和BIOES本质一样,只不过命名不一样而已,但是和分词的BMES有一定的区别)
1 | 中 B-ORG |
研究表明,BIO和BIOES标注方法对训练效果的影响不大,我首选了BIO标注方法进行训练,如果有必要的话,我会切换BIOES标注方法再进行测试.
关于LatticeLSTM的缺点
在剖析了LatticeLSTM的源码之后,我们在其源代码中发现两点问题
- LatticeLSTM只能支持batch_size=1;
- 当前字符有词汇融入时,则进行融合计算;如当前字符没有词汇时,则采取原生的LSTM进行计算。当有词汇信息时,Lattice LSTM并没有利用前一时刻的记忆向量C ,即不保留对词汇信息的持续记忆。
所以LatticeLSTM存在一些缺点:
- 计算性能低下,不能batch并行化。究其原因主要是每个字符之间的增加word cell(看作节点)数目不一致;
- 信息损失:1)每个字符只能获取以它为结尾的词汇信息,对于其之前的词汇信息也没有持续记忆。如对于「药」,并无法获得‘inside’的「人和药店」信息。2)由于RNN特性,采取BiLSTM时其前向和后向的词汇信息不能共享。
- 可迁移性差:只适配于LSTM,不具备向其他网络迁移的特性。
但是不可否认的是LatticeLSTM作为中文字符NER融入词汇信息进行增强的开山之作,其在当时的提升以及对这一领域的贡献是巨大的.
关于LatticeLSTM的实践
关于Lattice LSTM的一些超参数设置,学习率是一个递减(初始值0.015)的方式,优化空间不大,优化器源码使用的SGD,我尝试使用Adam/AdamW效果均没有SGD好(有点疑惑),SGD优化器设置的weight_decay=0.05,momentum=0,我尝试将momentum设置为0.9,效果比较差,经过几十轮的学习,F1值只有20%~30%.
源代码中LSTM的层数设置为1,我本来想设置为2测试,后发现并不生效,通过查看源代码发现这个配置其实并没有用到,因为将LSTM改写成了LatticeLSTM,且作者只实现了一层的代码,所以如果想设置更多的层,需要自己改源代码,难度较大.
数据和模型同步到GPU的代码可能还有地方需要改进,因为训练的时候,发现基本上是占用的CPU,GPU基本没有使用
还有模型的预测部分有bug(status=test),在status=test时,模型加载了两次,每次都将标签数+2,所以导致第二次加载模型后,总的标签数量对应不上…
模型不支持训练句子中包含空格(有空格的处理有问题,虽然不影响训练,但是从逻辑上得到的句子不正确),可以增加逻辑处理句子包含空格的情形
模型默认会将数字全部转换成0训练,可以更改参数配置(number_normalized=False)
词汇增强的中文NER方法
中文NER模型对比评测:https://zhuanlan.zhihu.com/p/142615620
loujie0822/DeepIE: DeepIE: Deep Learning for Information Extraction (github.com)
近年来,基于词汇增强的中文NER主要分为2条主线:
- Dynamic Architecture:设计一个动态框架,能够兼容词汇输入;
- Adaptive Embedding :基于词汇信息,构建自适应Embedding;
本文按照上述2条主线,将近年来各大顶会的相关论文归纳如下:

接下来可以研究:
Simple-Lexicon和Flat