Simplify the Usage of Lexicon in Chinese NER
Abstract
有很多工作尝试利用词汇信息提升中文NER的性能,例如LatticeLSTM, 但是它有一个复杂的网络结构,速度也比较慢;
在这项工作中,我们提出了一个将词汇信息融入字符表示的简单而有效的方法,这个方法没有设计复杂的序列模型结构,对于任何神经NER模型,它只需要对字符表示层进行细微的调整就可以引入词典信息.
实验表明与之前最优的各种方法相比,我们的方法速度更快且效果更好,而且也比较方便配合预训练模型如BERT一起使用.
Introduction
中文不像英文一样,单词之间有自然分割,所以中文NER很多研究者会先进行分词,再进行NER,但是分词可能会存在错误,从而影响NER任务的准确率,其他研究者直接干脆基于字符进行中文NER,也被证明直接基于字符的NER效果会比基于分词的效果好.
但是基于字符的NER确实没有利用词汇信息,基于这一思想,LatticeLSTM提出了融入词汇信息的字符NER方法,当一个字符匹配多个词语时,作者提出要保留所有词汇而不是启发式的为这个字符选择一个词语,然后让后续的NER模型来选择哪一个词更合适,为了实现这一想法,他们对LSTM-CRF模型的序列建模层进行了详细的修改.实验结果也确实表明在4个中文NER数据集上,LatticeLSTM是有改进的.
然而,Lattice LSTM的模型体系结构相当复杂。为了引入词典信息,Lattice LSTM在输入序列中不相邻的字符之间添加了几个额外的边,这显著降低了其训练和推理速度。此外,很难将Lattice LSTM的结构转移到其他可能更适合某些特定任务的神经网络架构(例如,卷积神经网络和transformer)。
我们的工作贡献:
- 我们提出了一种简单而有效的方法来将词语词典纳入中文NER的字符表示中。
- 所提出的方法可以转移到不同的序列标记体系结构,并且可以很容易地与BERT等预训练的模型相结合
实验结果表明,当用单层Bi-LSTM实现序列建模层时,我们的方法在推理速度和序列标记性能方面都比现有技术的方法有了很大的改进
Background
Soft word feature
Softword技术最初用于将分词信息合并到下游任务中,它通过嵌入相应的分割标签来增强字符表示
LatticeLSTM
关于LatticeLSTM的原理,我们在别的地方已经记录的比较清楚了,这里就略了
Approach
我们试图保留Lattice LSTM的优点并克服其缺点,为此,我们提出了一种新的方法,通过简单地调整NER模型的字符表示层来引入词汇信息。我们称这个方法为: SoftLexicon, 首先,将输入序列的每个字符映射到密集向量中。接下来,构建SoftLexicon功能,并将其添加到每个字符的表示中, 最后输入到序列模型层(如LSTM网络)中.
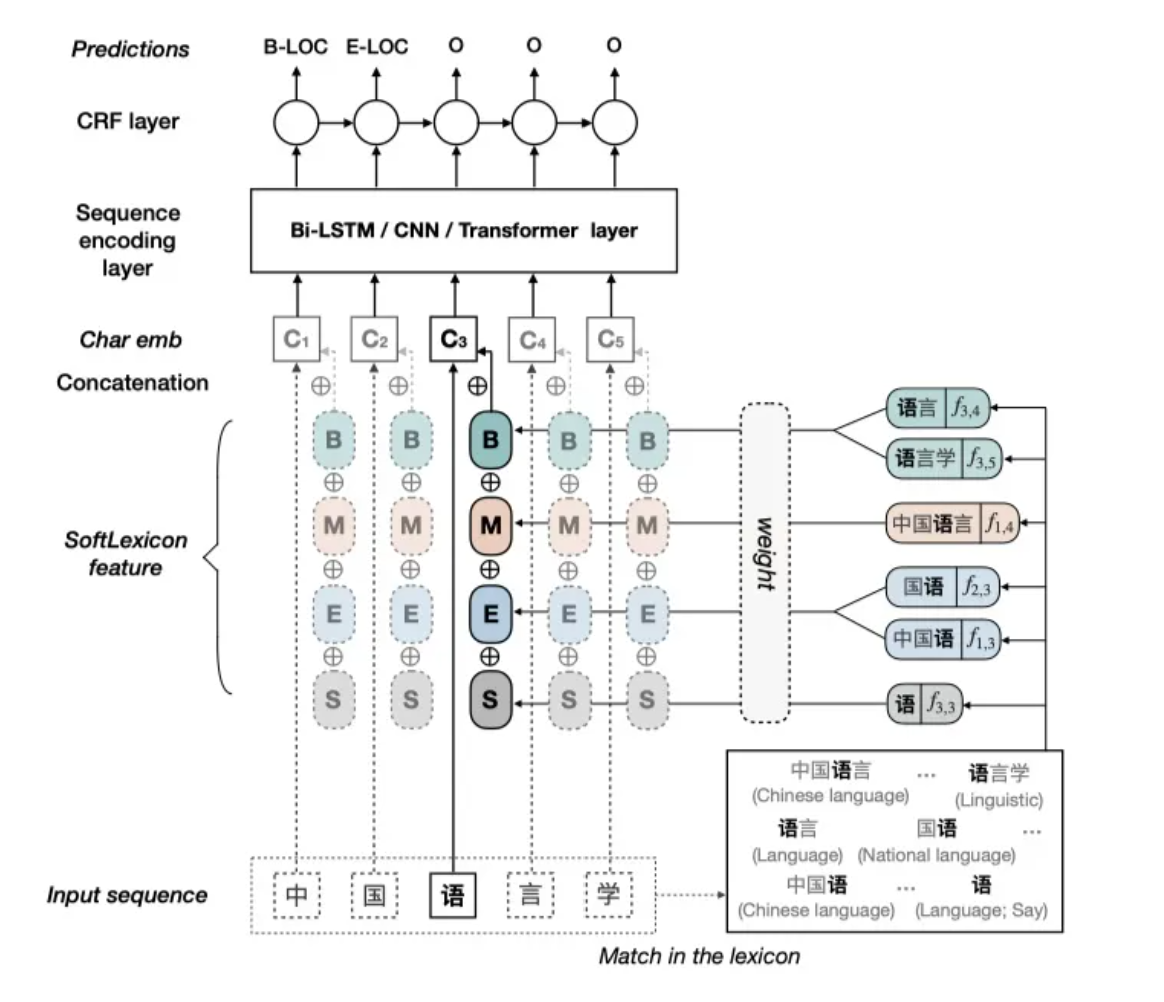
Character Representation Layer
对于基于字符的中文NER模型来说,输入序列可以看作是字符序列, s = {c1, c2, c3, …, cn} ∈ Vc , Vc是字符表(词表,叫做字典更贴切), 每个字符ci用向量表示
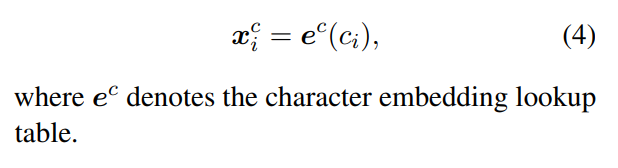 )
)
char + bichar: char bigrams被证明对字符表示是有效的, 特别是那些没有使用词汇信息的方法, 所以使用bigram embeddings加强字符表示是很常见的操作
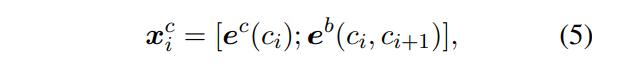
eb表示bichar的词向量表
Incorporating Lexicon Information
融合词汇信息有两种方式
ExSoftword Feature
这种方式保留所有的分割结果,而不是为每个字符只选择一种分割结果
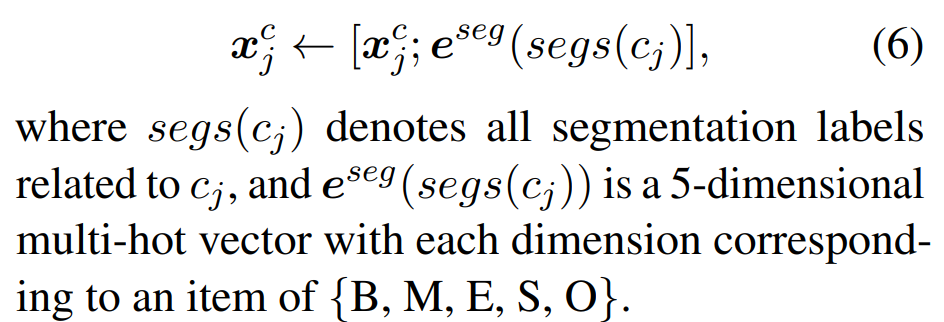
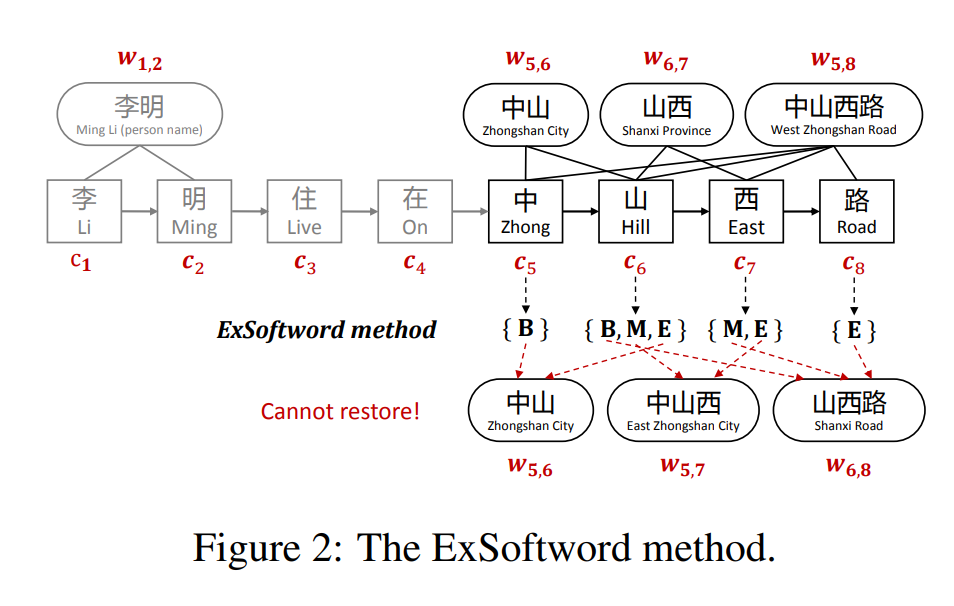
这里以西举例,分割结果里有 山西(西是end),中山西路(西是middle),所以eseg的五维one-hot编码中,第2,3维是1,其他维度是0。
但是这一方法的缺点是没有完全继承LatticeLSTM的两个优点,第1没有引入预训练词向量,第2它依然丢失了匹配结果的部分信息;如figure2中,针对{c5, c6, c7, c8} 的Exsoftword特征是{{B}, {B, M, E}, {M, E}, {E}},以西字举例,虽然知道存在的匹配结果中西可能是E或者M,但是作为M,可能的词有”中山西路”和”山西路”,作为E可能的词有”山西”和”中山西”,所以我们无法判断哪一个是要恢复的正确结果。
SoftLexicon
这种方法主要分为三个步骤:第1步: 每个字符的所有匹配的分割结果都会被分到四个集合中,即BMES,如果没有的话,则集合中包含特殊标记None,如figure3所示;这样不仅可以引入词向量,而且因为所有的匹配结果都保存在四个集合中,所以没有信息丢失
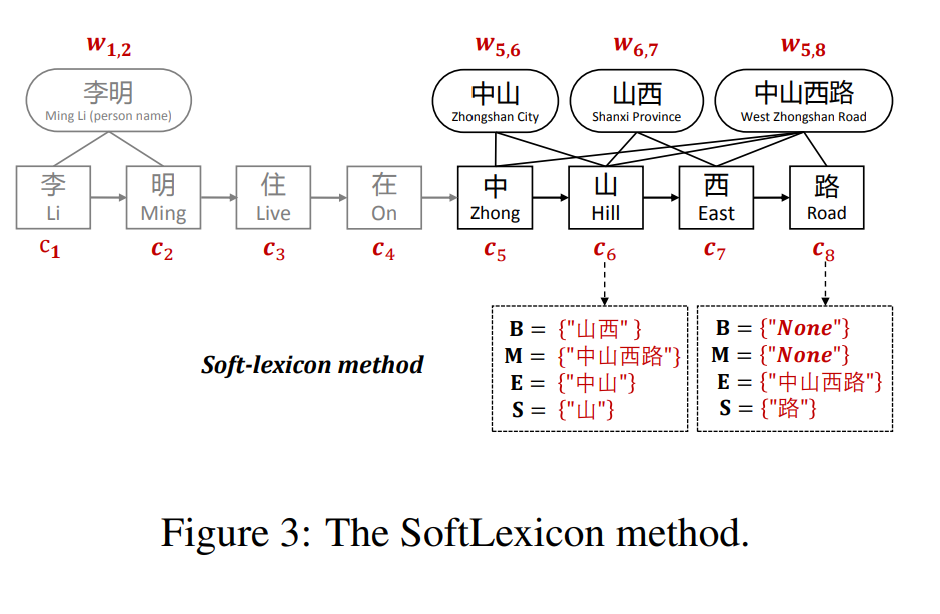
第2步:针对得到的集合,每个集合都会被转化成一个固定维度的向量,我们提出了两种将集合转化为向量的方法,第1种:

但是如table8所示,实验结果表明这种方式效果并不是太理想,所以我们提出一个权重算法用于利用词信息,为了保持计算效率,我们没有采用类似注意力机制的动态权重算法,相反,我们建议使用每个单词的频率作为其权重的指示。由于单词的频率是一个可以离线获得的静态值,这可以大大加快每个单词权重的计算。

这里,对四个集中的所有词语执行权重归一化,以进行整体比较。
在这项工作中,统计数据集是由任务的训练和验证数据集相结合构建的。当然,如果任务中存在未标记数据,则未标记数据集可以作为统计数据集。此外,请注意,如果w被与词典匹配的另一个子序列覆盖,则w的频率不会增加。这防止了较短单词的频率总是小于覆盖它的较长单词的频率的问题。(这里的表述有点疑问?)
第3步:最后一步就是将这四个集合的表示合并到一个固定维度的表示,然后加到每个字符的表示, 为了保留尽可能多的信息,我们选择将四个单词集的表示连接起来,每个字符的最终表示:
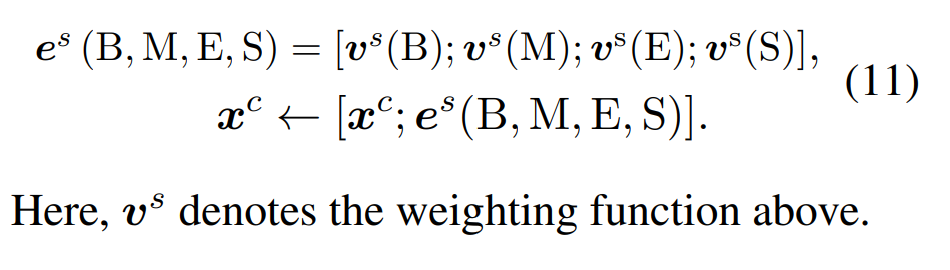
Sequence Modeling Layer
一般可选的模型有BiLSTM,CNN和Transformer,我们这里选择的是一个单层的BiLSTM
Label Inference Layer
CRF模型
Experiments
实验配置与Lattice LSTM是一致的, 包括测试数据集、比较基线、评估指标(P、R、F1)等;
甚至连词典(5.7k个单个字符的词,291.5k个两个字符的词,278.1k个三个字符的词以及129.1k个其他词)和预训练的词向量也是用的和Lattice LSTM一样的
Computational Efficiency Study
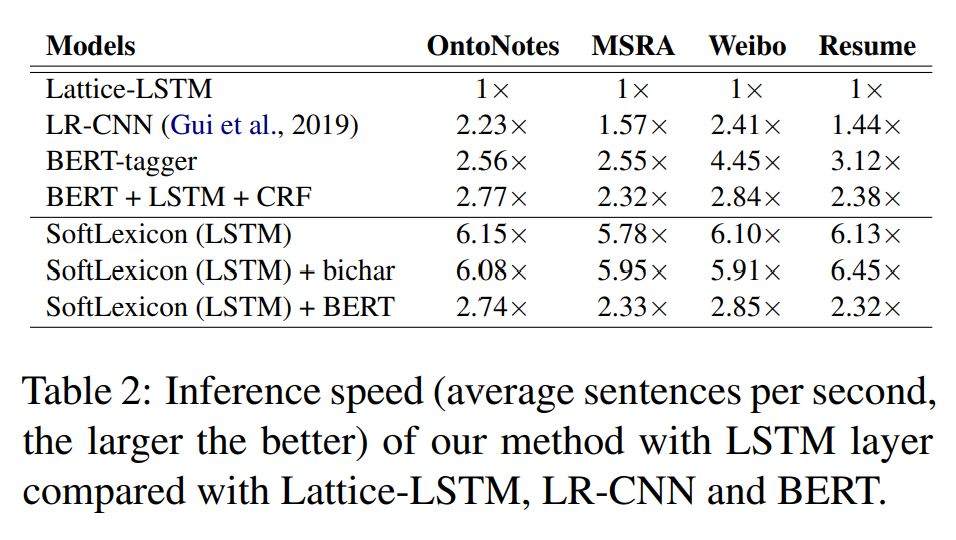
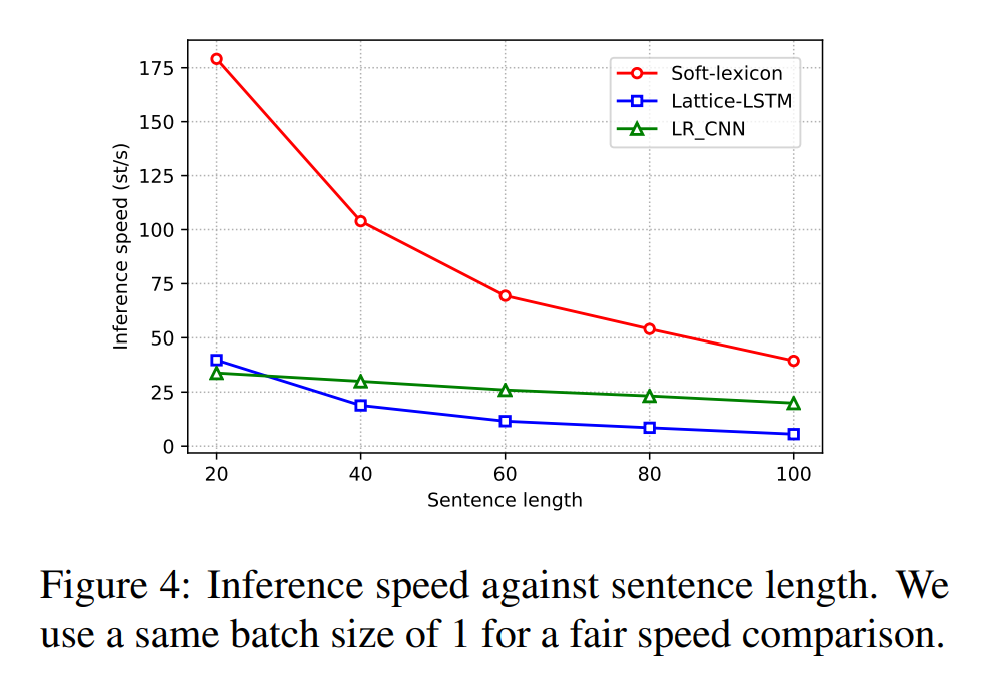
为了进一步说明Soft-Lexicon方法的有效性,我们还进行了一个实验来评估它对不同长度句子的推理速度,为了确保公平,我们将所有的对比方法batchsize均设置为1,对比结果如图4
Effectiveness Study
表3-6显示了我们的方法相对于比较基线的性能
Transferability Study
表7显示了SoftLexicon方法在实现具有不同神经架构的序列建模层时的性能。从表中,我们首先可以看到,基于LSTM的架构比基于CNN和transformer的架构表现更好。此外,我们具有不同序列建模层的方法始终优于其相应的ExSoftword基线。这证实了我们的方法在不同的神经NER模型中建模词典信息的优越性。
Combining Pre-trained Model
我们还在四个数据集上进行了实验,以进一步验证SoftLexicon与预训练模型相结合的有效性,结果如表3-6所示。在这些实验中,我们首先使用BERT编码器来获得每个序列的上下文表示,然后将它们连接到字符表示中。从表中我们可以看出,带有BERT的SoftLexicon方法在所有四个数据集上都优于BERT标记器。这些结果表明,SoftLexicon方法可以有效地与预先训练的模型相结合。此外,结果还验证了我们的方法在利用词典信息方面的有效性,这意味着它可以补充从预先训练的模型中获得的信息。
Ablation Study(消融研究)
- 在Lattice LSTM中,每个字符只接收以其开头或结尾的单词的单词信息。因此,包含字符内部的单词的信息被忽略。然而,SoftLexicon通过合并“中间”单词组来防止这些信息的丢失。在“-‘M’ group”实验中,我们删除了SoftLexicon中的“中间”组,就像Lattice LSTM中一样。所有四个数据集的性能下降表明了“M”字组的重要性,并证实了我们方法的优势。
- 我们的方法建议对四类“BMES”匹配词进行明确区分。为了研究这种设计的相对贡献,我们进行了实验来消除这种区别,即我们简单地将所有加权词相加,而不考虑它们的类别。表现的下降验证了对不同匹配单词进行明确区分的重要性。
- 我们在第3.2节中提出了两种汇集四个集合的策略。在“- weighted pooling”实验中,加权池策略被平均池取代,这降低了性能。与均值池相比,该加权策略不仅成功地根据不同词语的重要性对其进行了加权,而且还引入了统计数据中每个词语的频率信息,这被证明是有帮助的。
- 尽管现有的基于词典的方法(如Lattice LSTM)也使用单词加权,但与所提出的SoftLexicon方法不同,它们无法在所有匹配的单词之间执行权重归一化。例如,Lattice LSTM仅对“B”组或“E”组内的权重进行归一化。在“- Overall weighting”实验中,我们像Lattice LSTM一样在每个“BMES”组内进行了权重归一化,发现结果性能下降。这一结果表明,在所有匹配单词之间执行整体权重归一化的能力也是我们方法的优势。