flat lattice transformer
论文解读
论文《FLAT: Chinese NER Using Flat-Lattice Transformer》
解读略
环境安装
Windows环境
python和pytorch版本可以根据自己的环境情况,其他包按照官网的说明安装
numpy包,安装1.16.4版本需要C++环境,安装不上
安装超过1.24的版本会因为fitlog库中使用了np.str而报错,虽然1.20之后就废弃了np.str之后,但是安装<1.24的版本还是能跑的
我这里安装了1.23.5
pytorch,项目要求安装版本为1.2.0,但是因为我的cuda版本是12.0,安装不上1.2.0的版本,一开始安装的是2.0.1的版本,但是因为版本太新,在torch.optim.lr_scheduler中其LambdaLR(以及其他类型的调度器)均继承的是LRScheduler类,
而在fastNLP中,其要求为:
1 | if isinstance(lr_scheduler, torch.optim.lr_scheduler._LRScheduler): |
所以就会导致报错,我将pytorch的版本降低至1.7.1.解决了此问题
在此版本中,所有的调度器继承的是:_LRScheduler1
2class LambdaLR(_LRScheduler):
def __init__(self, optimizer: Optimizer, lr_lambda: Union[Callable[[int], float], List[Callable[[int], float]]], last_epoch: int=...) -> None: ...
服务器环境(centos或Linux)
python3.8的版本,安装不了FastNLP==0.5.0
python3.6.9的版本,所有的包可以安装和flat lattice transformer项目完全一致的版本
PyTorch: 1.2.0
FastNLP: 0.5.0
Numpy: 1.16.4
fitlog: 0.9.13
pytz: 2024.2
但是11G的显存还是没法跑我的数据集(batch_size=10),上4090D吧
conda 可以直接创建需要的python版本的虚拟环境,而无需预先安装指定的python版本
使用conda先创建了python3.7.3的环境,实践证明安装不上FastNLP==0.5.0
之后将python改为3.6.9,可以安装(并且注意FastNLP只能用pip安装)
fitlog也只能用pip安装
cuda 12.4版本,安装pytorch==1.2.0(cuda=10.0),运行不了代码:RuntimeError: cublas runtime error : the GPU program failed to execute at /tmp/pip-req-build-p5q91txh/aten/src/THC/THCBlas.cu:331
这个错误大概就是pytorch安装的cuda版本和现在cuda版本不匹配(差距太大)导致的
果然重新安装pytorch=1.7.1的版本,cuda=11.0就可以运行了
代码剖析
项目代码:https://github.com/LeeSureman/Flat-Lattice-Transformer
flat参考了transformer-XL中的相对位置编码:
https://zhuanlan.zhihu.com/p/271984518
flat瘦身日记:https://zhuanlan.zhihu.com/p/509248057
发现simple lexicon和flat都是忽略空白字符的,空白字符按说肯定是有意义的:
venv/Lib/site-packages/fastNLP/io/file_reader.py,改动125行以及下面几行
原来的代码是:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17for line_idx, line in enumerate(f, 1):
line = line.strip()
if line == '':
if len(sample):
try:
res = parse_conll(sample)
sample = []
yield line_idx, res
except Exception as e:
if dropna:
logger.warning('Invalid instance which ends at line: {} has been dropped.'.format(line_idx))
continue
raise ValueError('Invalid instance which ends at line: {}'.format(line_idx))
elif line.startswith('#'):
continue
else:
sample.append(line.split())
改为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23for line_idx, line in enumerate(f, 1):
line = line.strip()
if line == '':
if len(sample):
try:
res = parse_conll(sample)
sample = []
yield line_idx, res
except Exception as e:
if dropna:
logger.warning('Invalid instance which ends at line: {} has been dropped.'.format(line_idx))
continue
raise ValueError('Invalid instance which ends at line: {}'.format(line_idx))
elif line.startswith('#'):
continue
else:
pairs = line.split() # 有改动
if len(pairs) == 1:
word = ' '
else:
word = pairs[0]
label = pairs[-1]
sample.append([word, label])
数据处理部分
load_xxx_ner()方法
内部主要使用了from fastNLP.io.loader import ConllLoader来加载数据集,应该是在内部封装了一些操作,其实不太用关注实现细节。
这个方法返回三个结果,并且将结果保存到缓存文件,如果下载运行时缓存文件存在,就直接加载缓存文件就好了,无需重复执行这一方法。
datasets:字典类型,包含三个key(train、test和dev),每个key对应的value都是DataSet类型(fastNLP中定义的),DataSet中有个fields_array字段,其也为字典类型,对应一系列key、value。
包括chars:size为(样本数量, 每个句子的字符数量)
target:size为(样本数量, 每个句子的字符数量)
bigrams:size为(样本数量, 每个句子中的所有二元词的数量),其实二元词的数量与句子的字符数量一致,二元词就是每个位置的字符+下一个位置的字符组合,如果是最后一个字符,那就加上\\
seq_len:size为(样本数量, 1),其中存储的时chars的长度vocab:字典类型,包含三个key(char、label和bigram),每个key对应的value都是Vocabulary类型(fastNLP中定义的),char是训练集、测试集和验证集中所有的字符,label是所有的标签(包括一个\<pad>和一个\<unk>),bigram是三个数据集中所有的二元词。
- embedding:字典类型,包含两个key(char、bigram),每个key对应的value都是StaticEmbedding类型(fastNLP中定义的),embedding[‘char’]是根据vocab中的char从预训练的单个字向量文件(gigaword_chn.all.a2b.uni.ite50.vec)中读取的后续会用到的字预训练向量;embedding[‘bigram’]是根据vocab中的bigram从预训练的二元词向量文(gigaword_chn.all.a2b.bi.ite50.vec)件中读取的后续会用到的二元词预训练向量。
equip_chinese_ner_with_lexicon()方法
针对上一方法中得到的datasets、vocab和embedding进一步处理,首先根据传入的w_list参数构建w_trie,w_list中保存了从ctb.50d.vec文件中读取的所有长度大于等于2的词,w_trie以Trie的数据结构保存(详见Lattice LSTM中的代码),然后利用Trie数据结构方便获取字的可选词的特性,获取datasets中所有char的可选词1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def get_skip_path(chars, w_trie):
sentence = ''.join(chars)
result = w_trie.get_lexicon(sentence)
# print(result)
return result
for k, v in datasets.items():
# 这里使用了 functools.partial 来固定 get_skip_path 函数的 w_trie 参数。这个处理函数将被应用于 chars 字段,并将结果存储在 lexicons 字段中。
v.apply_field(partial(get_skip_path, w_trie=w_trie), 'chars', 'lexicons')
v.apply_field(copy.copy, 'chars', 'raw_chars')
v.add_seq_len('lexicons', 'lex_num')
#start index
v.apply_field(lambda x: list(map(lambda y: y[0], x)), 'lexicons', 'lex_s')
# end index
v.apply_field(lambda x: list(map(lambda y: y[1], x)), 'lexicons', 'lex_e')
关于第一步增加lexicons字段的步骤举个例子,假设输入的某一条样本chars为:['被', '告', '(', '反', '诉', '原', '告', ')', ':', '噢', '斯', '曼', '·', '阿', '木', '克', ';', '原', '告', '(', '反', '诉', '被', '告', ')', ':', '喀', '什', '纳', '迪', '尔', '农', '业', '科', '技', '有', '限', '公', '司', ';']
得到的result为:[[0, 1, '被告'], [2, 3, '(反'], [3, 4, '反诉'], [5, 6, '原告'], [6, 7, '告)'], [7, 8, '):'], [13, 14, '阿木'], [15, 16, '克;'], [16, 17, ';原'], [17, 18, '原告'], [19, 20, '(反'], [20, 21, '反诉'], [22, 23, '被告'], [23, 24, '告)'], [24, 25, '):'], [26, 27, '喀什'], [28, 29, '纳迪'], [28, 30, '纳迪尔'], [29, 30, '迪尔'], [31, 32, '农业'], [31, 33, '农业科'], [33, 34, '科技'], [34, 35, '技有'], [35, 36, '有限'], [37, 38, '公司'], [38, 39, '司;']]
关于raw_chars和lex_num字段从代码中很简单就能看得懂,重点是’lex_s’和’lex_e’,因为这两个字段是以lexicons字段为基础,而lexicons的例子就是上面的result,y[0]就是这个词的开始索引,y[1]是这个词的结束索引(索引是指这个字在原始句子的位置索引)。这里就跟原论文的扁平lattice思想挂钩了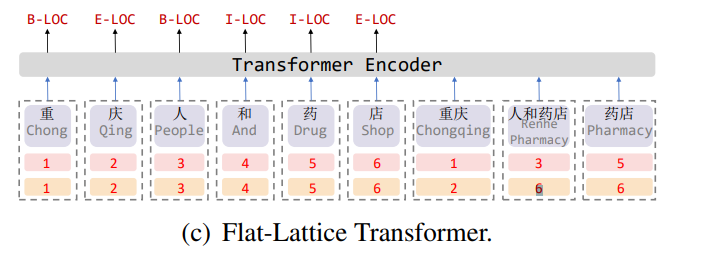
例如这里”重庆”的”重”开始索引为1,结束索引为2,”人和药店”的”人”开始索引为3,结束索引为6,当然论文中的这张图索引下标是从1开始的,而实际程序中下标从0开始。
原论文中还提到,会将句子中所有匹配的可选词,都放到句子的最后(就像上图中一样),代码就是下面这部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def concat(ins):
chars = ins['chars']
lexicons = ins['lexicons']
result = chars + list(map(lambda x: x[2], lexicons)) # 就是把lexicon中的词拼接到char列表的最后
# print('lexicons:{}'.format(lexicons))
# print('lex_only:{}'.format(list(filter(lambda x:x[2],lexicons))))
# print('result:{}'.format(result))
return result
def get_pos_s(ins):
lex_s = ins['lex_s'] # 这里进来每次只会针对一条数据执行,实际上apply方法里有个循环,会针对每条数据都执行
seq_len = ins['seq_len']
pos_s = list(range(seq_len)) + lex_s # 词的索引放在字的最后面,这是开始索引(对应图中的第1行)
return pos_s
def get_pos_e(ins):
lex_e = ins['lex_e']
seq_len = ins['seq_len']
pos_e = list(range(seq_len)) + lex_e # 词的索引放在字的最后面,这是结束索引(对应图中的第2行)
for k, v in datasets.items():
v.apply(concat, new_field_name='lattice') # 调用concat方法,输入结果存放到新字段lattice
v.set_input('lattice') # 作为模型的输入,目前为止,v中的10个字段,只有lattice是输入(is_input=True)
v.apply(get_pos_s, new_field_name='pos_s')
v.apply(get_pos_e, new_field_name='pos_e')
v.set_input('pos_s', 'pos_e') # 开始索引和结束索引也作为输入
这里继续使用一个例子来解释lattice字段的生成过程(concat方法):
chars:['被', '告', '(', '反', '诉', '原', '告', ')', ':', '噢', '斯', '曼', '·', '阿', '木', '克', ';', '原', '告', '(', '反', '诉', '被', '告', ')', ':', '喀', '什', '纳', '迪', '尔', '农', '业', '科', '技', '有', '限', '公', '司', ';']
lexicons:[[0, 1, '被告'], [2, 3, '(反'], [3, 4, '反诉'], [5, 6, '原告'], [6, 7, '告)'], [7, 8, '):'], [13, 14, '阿木'], [15, 16, '克;'], [16, 17, ';原'], [17, 18, '原告'], [19, 20, '(反'], [20, 21, '反诉'], [22, 23, '被告'], [23, 24, '告)'], [24, 25, '):'], [26, 27, '喀什'], [28, 29, '纳迪'], [28, 30, '纳迪尔'], [29, 30, '迪尔'], [31, 32, '农业'], [31, 33, '农业科'], [33, 34, '科技'], [34, 35, '技有'], [35, 36, '有限'], [37, 38, '公司'], [38, 39, '司;']]
得到result:['被', '告', '(', '反', '诉', '原', '告', ')', ':', '噢', '斯', '曼', '·', '阿', '木', '克', ';', '原', '告', '(', '反', '诉', '被', '告', ')', ':', '喀', '什', '纳', '迪', '尔', '农', '业', '科', '技', '有', '限', '公', '司', ';', '被告', '(反', '反诉', '原告', '告)', '):', '阿木', '克;', ';原', '原告', '(反', '反诉', '被告', '告)', '):', '喀什', '纳迪', '纳迪尔', '迪尔', '农业', '农业科', '科技', '技有', '有限', '公司', '司;']
pos_s和pos_e分别是开始索引和结束索引,对应图中的第1行和第2行
pos_s: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 0, 2, 3, 5, 6, 7, 13, 15, 16, 17, 19, 20, 22, 23, 24, 26, 28, 28, 29, 31, 31, 33, 34, 35, 37, 38]
pos_e: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 1, 3, 4, 6, 7, 8, 14, 16, 17, 18, 20, 21, 23, 24, 25, 27, 29, 30, 30, 32, 33, 34, 35, 36, 38, 39]
vocab增加两个key分别为”word”和”lattice”,”word”是w_list中的所有词,”lattice”是datasets三个数据集中所有的chars+lexicons。
embedding也增加两个key分别为”word”和”lattice”,分别对应vocab[“word”]的预训练词向量(ctb.50d.vec)和vocab[“lattice”]的预训练词向量(yangjie_word_char_mix.txt,这个是融合了ctb.50d.vec+gigaword_chn.all.a2b.uni.ite50.vec)。
不过据我现在来看,vocab[“word”]和embedding[“word”]没啥用,毕竟vocab[“lattice”]已经是出现的所有字和词了。
模型部分
以上数据处理完成之后,就开始将数据输入到模型中进行计算,按照层级模型分为以下几个:
- Lattice_Transformer_SeqLabel
- TransformerEncoder
- Four_Pos_Fusion_Embedding
- Transformer_Encoder_Layer (默认1层)
- MultiHead_Attention_Lattice_rel_save_gpumm
- Positionwise_FeedForward
- TransformerEncoder
Lattice_Transformer_SeqLabel
首先传入Lattice_Transformer_SeqLabel的forward函数的参数如下:
lattice:size(batch_size, max_seq_len_and_lex_num)
bigrams:size(batch_size, max_seq_len)
seq_len:size(batch_size),这一批次每个句子的长度(原始字符数量)
lex_num:size(batch_size),这一批次每个句子匹配的词语个数
pos_s:size(batch_size, max_seq_len_and_lex_num),开始索引
pos_e:size(batch_size, max_seq_len_and_lex_num),结束索引
target:size(batch_size, max_seq_len),标签序号
max_seq_len_and_lex_num = char_num + lex_num(这一批次加和最大的)
max_seq_len = char_num (这一批次句子长度最长的)
lattice通过lattice_embedding得到raw_embed,size为(batch_size, max_seq_len_and_lex_num, 50)
如果使用bigram,bigram通过bigram_embedding得到bigrams_embed,size为(batch_size, max_seq_len, 50),因为bigrams的长度比lattice短,所以给bigrams_embed后面补零,最后size变为(batch_size, max_seq_len_and_lex_num, 50);然后将raw_embed和bigrams_embed拼接在一起:raw_embed_char = torch.cat([raw_embed, bigrams_embed], dim=-1)
得到的raw_embed_char,size为(batch_size, max_seq_len_and_lex_num, 100);
如果使用bert的预训练词向量,因为bert只有单个字的词向量,所以只能为lattice中的字符部分初始化词向量bert_embed,得到的size为(batch_size, max_seq_len, 768),虽然这里的bert_embed是根据这一批次中每个句子的实际长度(即mask过了)来初始化的,但是因为一开始的raw_embed并没有mask,所以后面还会再mask一次。得到bert_embed之后,与bigrams_embed一样也是在后面补零,最后size变为(batch_size, max_seq_len_and_lex_num, 768)。
然后将raw_embed_char与bert_embed拼接在一起,size为(batch_size, max_seq_len_and_lex_num, 868)。
现在raw_embed_char中既包含字符向量也包含词语向量,将字符向量是单独拿出来,这时候就需要知道句子的实际长度了1
2
3
4
5
6
7# 这里先过一个线性层,将size变为(batch_size, max_seq_len_and_lex_num, 160),868-->160
embed_char = self.char_proj(raw_embed_char)
# char_mask的size为(batch_size, max_seq_len_and_lex_num),但是只有句子的实际位置为True,其他位置为False
char_mask = seq_len_to_mask(seq_len, max_len=max_seq_len_and_lex_num).bool()
# 得到实际的字符向量
embed_char.masked_fill_(~(char_mask.unsqueeze(-1)), 0)
然后再获取词语向量,直接从最开始的raw_embed中获取1
2
3
4
5
6
7# 这里先过一个线性层,将size变为(batch_size, max_seq_len_and_lex_num, 160),50->160
embed_lex = self.lex_proj(raw_embed)
# 因为词语是在句子字符的后面,seq_len+lex_num得到每个句子实际的字符数量+词语数量
# mask之后与字符区域的mask取异或,就得到了纯词语区域的mask
lex_mask = (seq_len_to_mask(seq_len+lex_num).bool() ^ char_mask.bool())
# 得到实际的词语向量
embed_lex.masked_fill_(~(lex_mask).unsqueeze(-1), 0)
异或举例:
假设原始句子字符数量6,词语数量3,max_seq_len_and_lex_num=11
那么char_mask = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0]
seq_len_to_mask(seq_len+lex_num)得到的是
lex_mask_temp = [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]
char_mask ^ lex_mask_temp即得到:
lex_mask = [0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0]
将字符向量和词语向量加和在一起,作为最终的输入embeddingembedding = embed_char + embed_lex
传入encoder就是TransformerEncoder,其又分为Four_Pos_Fusion_Embedding和Transformer_Encoder_Layer两个部分
Four_Pos_Fusion_Embedding
这里计算四种相对位置(与论文与对应)1
2
3
4
5# pos_ss 计算head与head的相对位置,self.max_seq_len是所有数据中的最大句子长度
pos_ss = pos_s.unsqueeze(-1)-pos_s.unsqueeze(-2) + self.max_seq_len
pos_se = pos_s.unsqueeze(-1)-pos_e.unsqueeze(-2) + self.max_seq_len # head与tail相对位置
pos_es = pos_e.unsqueeze(-1)-pos_s.unsqueeze(-2) + self.max_seq_len # tail与head相对位置
pos_ee = pos_e.unsqueeze(-1)-pos_e.unsqueeze(-2) + self.max_seq_len # tail与tail的相对位置
这里相对位置的计算结合上面提到的“重庆人和药店”举例来理解,借用flat瘦身文章的图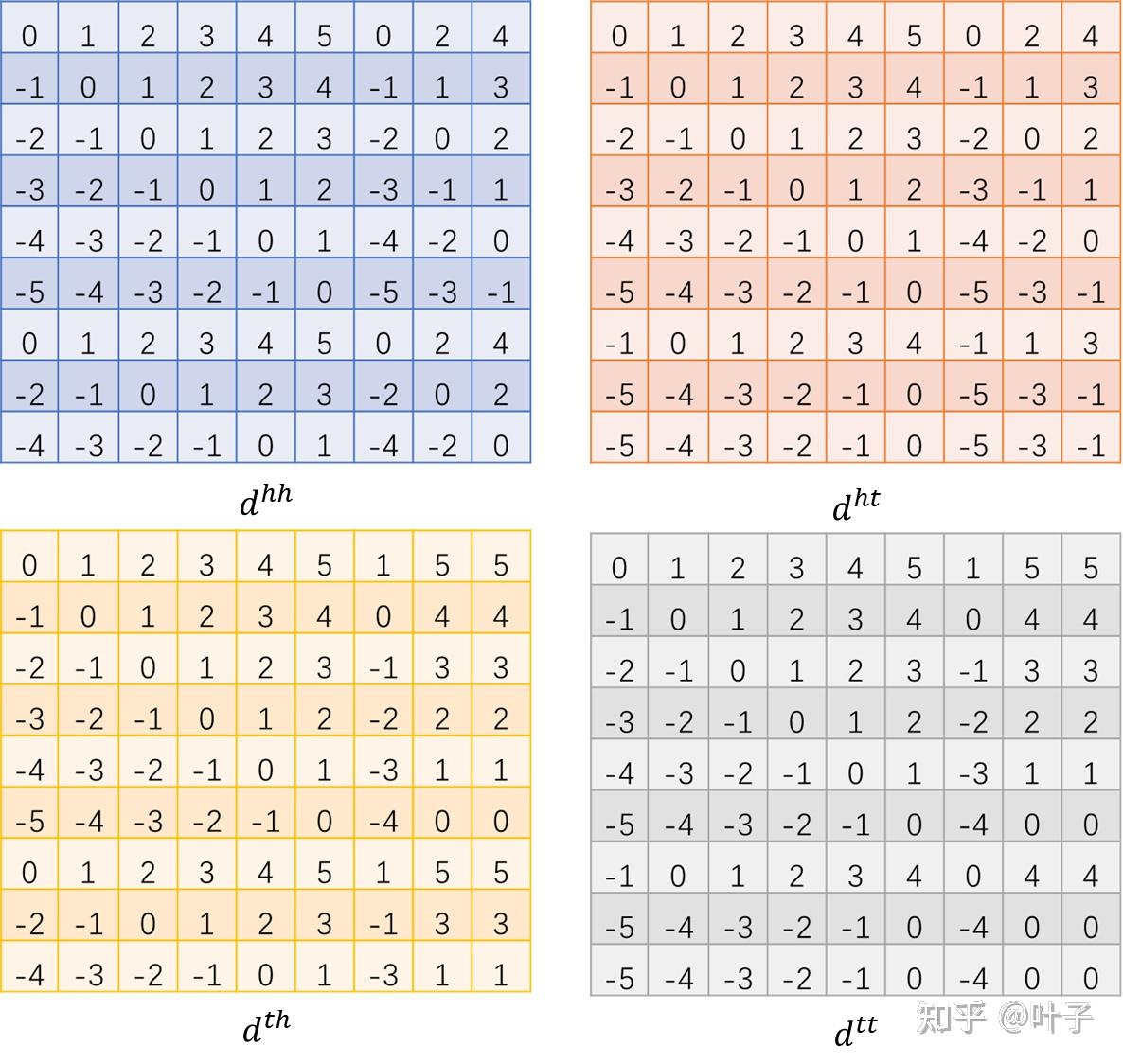
“重庆人和药店”加上可选词语组装成的句子,
开始索引为:[0, 1, 2, 3, 4, 5, 0, 2, 4]
结束索引为:[0, 1, 2, 3, 4, 5, 1, 5, 5]
左上角表格是代表head与head,以第1列为例,代表0号位置与[0, 1, 2, 3, 4, 5, 0, 2, 4]的相对位置(在其后面就是负值),所以得到第1列的值为[0, -1, -2, -3, -4, -5, 0, -2, -4],类似地,后面每一列代表其位置与其他所有的开始索引的相对位置,就是相当于上面代码中的:pos_s.unsqueeze(-1)-pos_s.unsqueeze(-2)
右上角表格是head与tail的相对位置,以第1列为例,代表0号位置与[0, 1, 2, 3, 4, 5, 1, 5, 5]的相对位置,所以得到第1列的值为[0, -1, -2, -3, -4, -5, -1, -5, -5],类似地,后面每一列代表其位置与其他所有的结束索引的相对位置,就是相当于上面代码中的:pos_s.unsqueeze(-1)-pos_e.unsqueeze(-2)
其他两个表格同理。
这里正好解释一下flat瘦身里提到的点,这里得到的四个相对位置size为(batch_size, max_seq_len_and_lex_num, max_seq_len_and_lex_num),后面还要再经过位置embedding层,变为(batch_size, max_seq_len_and_lex_num, max_seq_len_and_lex_num, hidden_dim)
这样计算下来占用的显存是非常高的(详细看flat瘦身文章就好了)
而仔细观察这四个相对位置编码可以发现,其实有重复的部分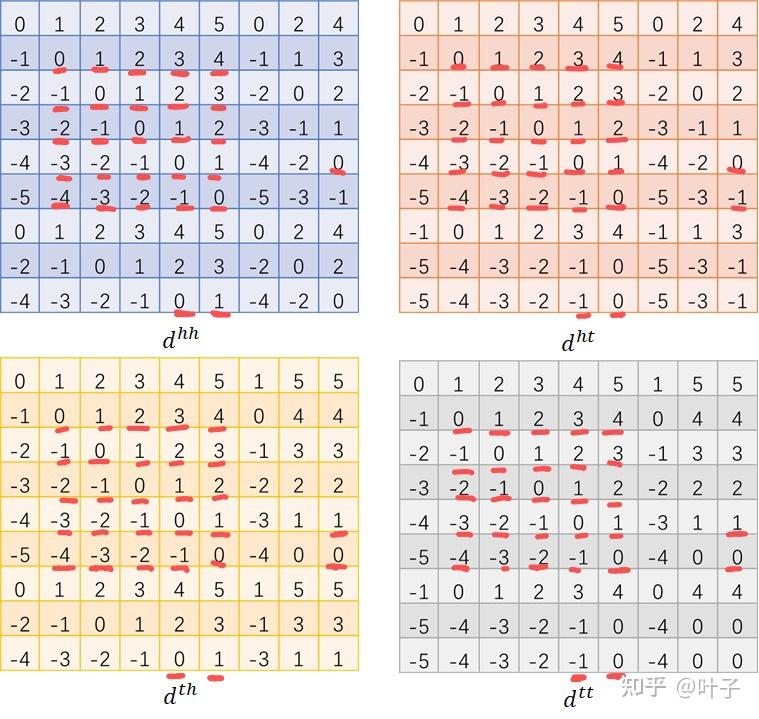
就是所有的句子的字符部分,因为句子的字符部分开始索引和结束索引是相等的,所以四种相对位置计算出来也是完全相同的,按照flat-瘦身中采用的方法就是进行去重操作(V2版本中):
1 | pe_4 = torch.cat([pe_ss, pe_se, pe_es, pe_ee], dim=-1) |
这里的其实我没太理解这里的思路,其实最终得到的相对位置编码还是这样的size,区别就是原本有4个这种size的张量,现在只有1个,因为这里本身走了一个线性层将size缩小了,那如果我直接将原来的位置编码的hidden_dim就设置为40,不就好了?不就同样从可以缩小size嘛?(后面可以自行尝试一下)
另外上面在计算相对位置时,在最后统一都加了max_seq_len(最长句子的字符数),这样可以确保所有的相对位置落在区间[0, 2*max_seq_len],因为self.pe也是计算的[0, 2*max_seq_len]这一区间的位置编码。
这部分操作其实对应原论文中的四种相对位置的拼接以及使用Transformer-XL中的相对位置编码将得到的相对位置(Rij)加到Attention机制中:
上面已经完成了四种相对位置的拼接(虽然这里是考虑到直接拼接占用显存过大,所以使用了一定的技巧)得到了Rij,这里的self.pos_fusion_forward层就是公式最外面的可学习参数W和ReLU激活1
self.pos_fusion_forward = nn.Sequential(nn.Linear(self.hidden_size*4, self.hidden_size),nn.ReLU(inplace=True))
那么接下来就是下一个公式的计算了
Transformer_Encoder_Layer
将输入和相对位置编码传入Transformer_Encoder_Layer的forward之后,接下来要传入MultiHead_Attention_Lattice_rel_save_gpumm,也就是在这一层将相对位置编码融合到Attention中。
输入参数有:
key、query、value都是之前字符向量+词语向量得到的最终embedding(Exi),
seq_len:这一批次中每个句子长度
lex_num:这一批次中每个句子匹配的词语个数
rel_pos_embedding:上一步骤中得到的相对位置编码
给query、key增加一个线性层Wq和Wk得到的是就是公式中的:WqExi、ExiWk,E(W在前在后没有区别,因为不改变size),但是这里的源代码中并没有给key增加线性层(可学习参数W),目前暂不确定原因1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if self.k_proj: # 源代码这里是False
if self.mode['debug']:
print_info('k_proj!')
key = self.w_k(key)
if self.q_proj: # True
if self.mode['debug']:
print_info('q_proj!')
query = self.w_q(query)
if self.v_proj: # True
if self.mode['debug']:
print_info('v_proj!')
value = self.w_v(value)
if self.r_proj: # True
if self.mode['debug']:
print_info('r_proj!')
rel_pos_embedding = self.w_r(rel_pos_embedding)
注意看公式中的A和C的部分,其后面一项都是key,所以可以先将queryT和uT先加和,然后一起做运算,就可以直接得到A_C
公式中的u和V是啥呢1
2
3
4
5
6
7self.w_k = nn.Linear(self.hidden_size, self.hidden_size)
self.w_q = nn.Linear(self.hidden_size, self.hidden_size)
self.w_v = nn.Linear(self.hidden_size, self.hidden_size)
self.w_r = nn.Linear(self.hidden_size, self.hidden_size)
self.w_final = nn.Linear(self.hidden_size, self.hidden_size)
self.u = nn.Parameter(torch.Tensor(self.num_heads, self.per_head_size))
self.v = nn.Parameter(torch.Tensor(self.num_heads, self.per_head_size))
计算A_C:1
2
3
4
5
6
7
8
9
10
11
12
13# batch * n_head * seq_len * d_head
key = key.transpose(1, 2)
query = query.transpose(1, 2)
value = value.transpose(1, 2)
# batch * n_head * d_head * key_len
key = key.transpose(-1, -2) # 这里是把K转置了,跟公式不太一样,但是本质差不多
# u_for_c扩充之后,第1维和第3维与query一致
u_for_c = self.u.unsqueeze(0).unsqueeze(-2)
query_and_u_for_c = query + u_for_c
A_C = torch.matmul(query_and_u_for_c, key)
虽然无论是转置query还是转置key,本质一样,但是queryT x key和query x keyT我认为不一样,得到得size不一样,按照公式是前者,但是代码里是后者,暂不明确这其中的原因。
接下来计算 B项和D项,这两项的后面都是RijWk,R,这个就是将相对位置编码过一层线性层就可以了,前面分别是queryT和VT,那么同样可以先加和,再一起计算:1
2
3
4
5
6
7
8# B
rel_pos_embedding_for_b = rel_pos_embedding.permute(0, 3, 1, 4, 2)
# after above, rel_pos_embedding: batch * num_head * query_len * per_head_size * key_len
query_for_b = query.view([batch, self.num_heads, max_seq_len, 1, self.per_head_size])
query_for_b_and_v_for_d = query_for_b + self.v.view(1, self.num_heads, 1, 1, self.per_head_size)
B_D = torch.matmul(query_for_b_and_v_for_d, rel_pos_embedding_for_b).squeeze(-2)
# att_score: Batch * num_heads * query_len * key_len
attn_score_raw = A_C + B_D
这里在计算B_D时,也是转置了后一项,并没有转置query和V,很奇怪啊,搞不懂。
如果按照原公式来进行计算,最后得到的A_C和B_D的size不一致,而且与预期的size也有差别,所以这里应该是为了调整得到的结果size,所以与原来的公式略有差别,但是整体参与计算的每一项都是一致的。最后再补充一下关于Transformer-XL相对位置编码的介绍
至此所有比较核心的代码都剖析完了,剩下的代码也都比较简单易懂,详细看源代码就好了。
实验测试
我是先跑了Resume数据,看一下是否可以跑到论文中记录的效果,
Resume数据集,batch_size=10, 最长句子长度187(左右吧),V1本地8G显存跑不了,前20轮可以跑,因为前20轮bert的预训练权重处于冻结状态,20轮之后显存就不够用了;V2进行显存瘦身之后,可以跑;
Resume:第45轮,测试集f1= 0.962759,论文中是:0.9586(比论文还高)
我的数据集:
因为我的数据集中的最长句子长度是276,batch_size=10,需要的显存超过了8G,本地跑不了(前20轮可以跑)
在4090D上运行,V2:flat+bert_unique(),最长句子长度276,句子+词语的最大长度是447,batch_size=10,占用显存14G,感觉这个占用显存大小和瘦身文章写的差别有点大,瘦身文章中写的seq_len应该是指字符数+词语数,在seq_length=300,且batch_size=10时,V2只占用4585MB,为啥seq_length只从300增加到447,就占用增加到了14G?
目前发现在训练自己的数据集时,在第21轮,开始调整bert的预训练权重时,准确率骤降为0。
尝试步骤:
- 在第0轮直接允许bert embedding进行更新,训练第6轮时,f1还是突然降为0;
- 因为目前使用的sdg优化器,weight_decay=0,考虑是不是过拟合问题,将weight_decay调整为1e-4再次训练,在前5轮f1逐步提升,在第6开始下降,第10轮时下降为0;
- 推测是不是随机梯度下降导致无法有效学习,将优化器改为adam,weight_decay依然是1e-4,可以有效学习了,可以学习到一个比较高的f1值,但是每一轮f1值的波动会有点大,但是没有达到或者接近其他模型如(simple lexicon)可以达到的f1值;
- 使用adam优化器,然后重新在前20轮将bert embedding的更新冻结;首先从前20轮的效果来看,实际上还不如直接解冻bert embedding的效果;后面训练可以达到的最优结果是:f=0.979477, pre=0.979083, rec=0.979871。与simple lexicon达到的最优(不使用bert, f1=0.985, 使用bert, f1=0.9875)已经比较接近了;
- 因为simple lexicon没有使用bigram,而flat这里是默认使用bigram的,我认为在没有可靠的词语分割只有字符信息时,二元词可以带来一定的效果提升,但是如果已经有了可选词的情况下, 二元词的用处不大,所以我在flat中的不再使用二元词进行训练测试,达到的最优结果是:f=0.983528, pre=0.981556, rec=0.985507。相比使用Bigram,确实有约0.4%的提升;
- 在将相对位置编码融合进attention的部分,根据transformer-XL的计算公式,k_proj按照道理应该设置为True,Flat中默认为FALSE,所以设置True进行尝试发现f1只能达到0.965,所以关于k_proj的参数设置情况可能还需要进一步研究;
- Flat使用的bert预训练权重为chinese_bert_wwm,后来有一些项目使用的bert预训练权重版本为chinese_bert_wwm_ext,所以也可以在Flat中使用ext版本来测试一下,测试结果没有明显的提升,且还有下降:f=0.979887, pre=0.9791, rec=0.980676。
大模型的embedding是否可以来优化Flat,因为Flat只是把向量最后加在一起。