MCP初步探索
MCP服务指南
MCP服务:https://mcpservers.org/
MCP 终极指南:https://guangzhengli.com/blog/zh/model-context-protocol
MCP与Function call的区别?
目前的理解就是,MCP是一堆方法调用声明放到一个MCP服务中,不同应用的方法可以分别定义在不同的MCP服务中,然后大模型根据需要自己去取;
而Function call就是把方法声明和大模型放在一起直接调。
MCP是一种客户端-服务器架构的通信协议,需要特定的客户端环境来接入。
单独的大模型本质上只是一个推理引擎,缺乏处理MCP协议所需的架构组件。
所以MCP的使用方式是搭配一些客户端如cursor使用,然后像cursor里面还可以选择驱动MCP服务的大模型(大脑)
而如果仅仅想给一个大模型赋予“行动”的能力,可以通过function call的形式。
但是这两种方式的共同前提是:需要大模型支持function call,因为大语言模型只具备文本生成能力,如果支持function call的大模型可以通过传参和返回特定参数明确告知用户此步骤是否调用工具,而如果不支持的大语言模型在这方面能力就有所缺失,不过依然可以通过控制大模型输出的格式,如果使用工具调用则返回特定格式,来达到这一目的,但是效果可能不如直接支持function call的大模型。
MCP服务配置
萌新指南|手把手教你Cherry Studio配置MCP,10分钟让大模型学会上网截图! https://mp.weixin.qq.com/s/a8XlAw4wrdJpKGVUWneaqg
萌新靠MCP实现RPA、爬虫自由?playwright-mcp实操案例分享!:https://mp.weixin.qq.com/s/8kh1bxotWDqIRRb0oz8RJQ
cursor配置MCP服务
第三方 playwright mcp服务:https://github.com/executeautomation/mcp-playwright
微软官方 playwright mcp服务:https://github.com/microsoft/playwright-mcp
cursor增加使用playwrite MCP服务
- 安装:npm install -g @executeautomation/playwright-mcp-server
- 在cursor中增加MCP服务:
配置:
{
“mcpServers”: {
“playwright”: {
“command”: “npx”,
“args”: [“-y”, “@executeautomation/playwright-mcp-server”]
}
}
} - Ctrl+L打开 chat模型,在对话中输入任务(需开启MCP服务)
在cursor中配置play wright mcp服务,使用Claude系列的模型调用,用来执行与浏览器进行交互的任务效果特别好(比在TRAE中使用豆包大模型+mcp服务效果好很多)。
但是目前的缺陷有:
- 一般可以配置的mcp方法不能超过40个,超过40个会对大模型使用工具的性能造成影响;
- 单次agent任务最多只能执行25次工具调用,达到次数限制任务就会终止,所以对于数据采集类任务需要大量的网页打开操作是不适用的。
其实不执行安装也可以,配置文件中配置的启动命令也会进行安装。
这种方式与我们自己驱动playwright的区别是什么?
大模型+MCP服务是大模型全面自动驱动,优势是,根据任务自行驱动,不需要写比较多的代码;劣势是:慢,费token,而且目前他很依赖于我们给他的任务描述粒度,且目前受限于上下文长度限制,可执行步骤有限。
所以想要速度快+省钱,最好某些步骤用大模型,某些步骤自行写代码驱动playwright。
cursor配置File System MCP服务
- 安装:npm install -g @modelcontextprotocol/server-filesystem
- 在cursor中增加MCP服务,配置:
“filesystem”: {
“command”: “npx”,
“args”: [
]"-y", "@modelcontextprotocol/server-filesystem", "E:/mcp_file_system"
}
E:/mcp_file_system表示允许模型通过MCP服务可以操作的目录,不能包含空格(亲自踩坑)
配置firecrawl mcp
在cursor的mcp配置文件中增加如下配置即可:1
2
3
4
5
6
7
8
9
10
11{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR-API-KEY"
}
}
}
}
api key需要在官网注册账号开通,会赠送免费额度:
https://www.firecrawl.dev/app?spm=5176.28197581.content.3.f5205a9eSod5cL
其支持哪些方法可以参考GitHub项目:
https://github.com/mendableai/firecrawl-mcp-server
Dify平台
本地化部署dify平台之后,可以自行在服务器部署mcp服务,然后通过dify平台的通过SSE发现和调用MCP工具来调用。
注意:dify平台上有一个play wright插件:https://marketplace.dify.ai/plugins/hjlarry/playwright
通过仔细看说明可以发现,这个是指将play wright工具部署成一个服务,给大模型调用,应该与常规理解的mcp服务有所区别。
在服务器上自行部署一个play wright mcp服务
- 使用node安装playwright
npm install playwright - 执行以下命令安装mcp服务:
npm install @playwright/mcp@latest - 以sse协议调用,增加启动端口
npx @playwright/mcp@latest --port 8931
可以使用nohup进行后台运行
在Linux服务器上启动mcp 服务的命令:npx @playwright/mcp@latest --port 8931 --executable-path /ms-playwright/chromium-1172/chrome-linux/chrome --headless --browser chromium --no-sandbox
–executable-path参数可以不加
关于具体有哪些参数在github项目上有详细说明(不过在此mcp刚发布时没有,导致我在调用mcp服务报错时不知道该如何解决)
例如
- –no-sandbox:禁用浏览器沙箱,仅建议在开发环境使用,生产环境存在安全风险。(这个参数不加,调用时会一直报错)
- –headless:以无头模式运行浏览器(无图形界面)。默认启用图形界面。在Linux环境下使用headless模式更优。
- –vision:使用截图而非默认的 Aria 快照,用于视觉测试或需要精确渲染的场景。
–no-sandbox 报错示例: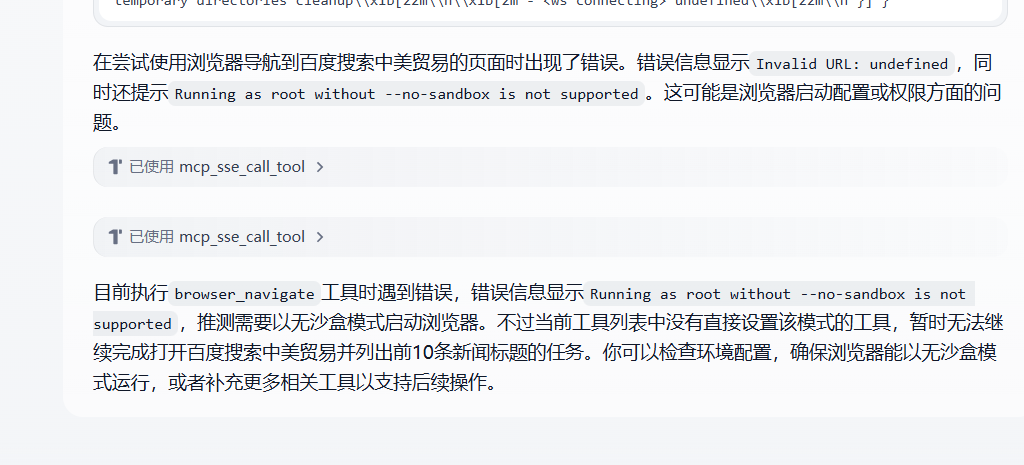
关于vision参数,官网给出以下解释,所有的工具有两种模式:
- Snapshot Mode (default): Uses accessibility snapshots for better performance and reliability
快照模式 (默认):使用辅助功能快照以获得更好的性能和可靠性 - Vision Mode: Uses screenshots for visual-based interactions
视觉模式 :使用屏幕截图进行基于视觉的交互
要使用 Vision 模式,请在启动服务器时添加 –vision 标志:1
2
3
4
5
6
7
8
9
10
11{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--vision"
]
}
}
}
这是我在非vision模式启动play wright mcp服务遇到的调用报错:
请求:1
{"mcp_sse_call_tool": {"tool_name": "browser_click", "arguments": "{\"element\": \"MENU button\", \"ref\": \"e7\"}"}}
响应:1
{"mcp_sse_call_tool": "Tool execution result: [{'type': 'text', 'text': 'Error: No current snapshot available. Capture a snapshot of navigate to a new location first.'}]"}
改为vision模式依然有这个问题,但是发现有所变化,能够截图了,但是截图的base64编码是空白页
然后大模型会认为是页面未完全加载,会执行等待的方法,等待结束之后还会报这个错误
请求:1
{"mcp_sse_call_tool": {"tool_name": "browser_wait_for", "arguments": "{\"time\": 5}"}}
响应:1
{"mcp_sse_call_tool": "Tool execution result: [{'type': 'text', 'text': 'Error: No current snapshot available. Capture a snapshot of navigate to a new location first.'}]"}
在Windows平台测试,无论是否使用有头模式还是无头模式,大模型均不需要截图轻松完成获取企业简介的工作,如果使用vision模式,则会使用截图,产生截图不全的问题。
将服务器上的服务改为非vision模式,目前在dify平台经过各种调试,依然面临的问题是点击操作或者截图操作无法正常进行,
点击需要依赖于snapshot(快照)和引用,总感觉大模型无法把它们串起来,包括上面执行wait操作也会报错,也是类似的道理。
想要通过Nginx转发在本地使用cursor调用服务器上的服务进行测试,但是在cursor中无法连通。
百炼平台
百炼平台也支持通过sse调用自己部署的mcp服务,或者将服务部署在他们的服务器给智能体调用
也有一个play wright服务:https://bailian.console.aliyun.com/?spm=5176.12818093_47.resourceCenter.2.57ea2cc988EIjt&tab=mcp#/mcp-market/detail/Playwright
查看文档可以发现虽然这个图标与dify平台的图标一致,但是这里是真正的mcp服务。
MCP进阶
可以学习一下MCP服务的源代码,自己写MCP服务
https://github.com/liaokongVFX/MCP-Chinese-Getting-Started-Guide
场景:例如目前的playwright方法会被部分检测严格的网站判断为自动化工具,然后无法打开网页;
这时候就需要编写一个自定义的方法,先进行一些预处理操作,再打开浏览器,就可以正常打开网页
与客户端+MCP+大模型可以实现类似能力的业内方案有:
- 智谱 autoGLM
- 火山引擎上面 OS Agent解决方案:Browser-use Playground、Computer Use Agent等,推测其也是依赖于
doubao-1.5-ui-tars模型; - 字节的 UI-TARS-desktop(桌面应用程序(https://github.com/bytedance/UI-TARS-desktop)),之前需要自己部署UI_TARS各种尺寸的模型,现在火山方舟平台上线了最新的`doubao-1.5-ui-tars`模型,可以直接作为后端模型;
- 百炼智能体应用,直接支持增加MCP服务,可以支持百炼云端部署的MCP,或者第三方MCP服务部署到阿里云的服务器,或者自己部署的MCP服务(将服务调用接口配置到上面,但是要注意外部可访问)
- dify平台构建工作流或智能体。
但是这些方案比较适合于不太会写代码的小白使用,去执行一些不太复杂的任务,当需要比较灵活的去控制大模型和方法调用时,可能需要使用类似langchain的框架去开发大模型应用。