使用Transformer Encoder进行NER任务
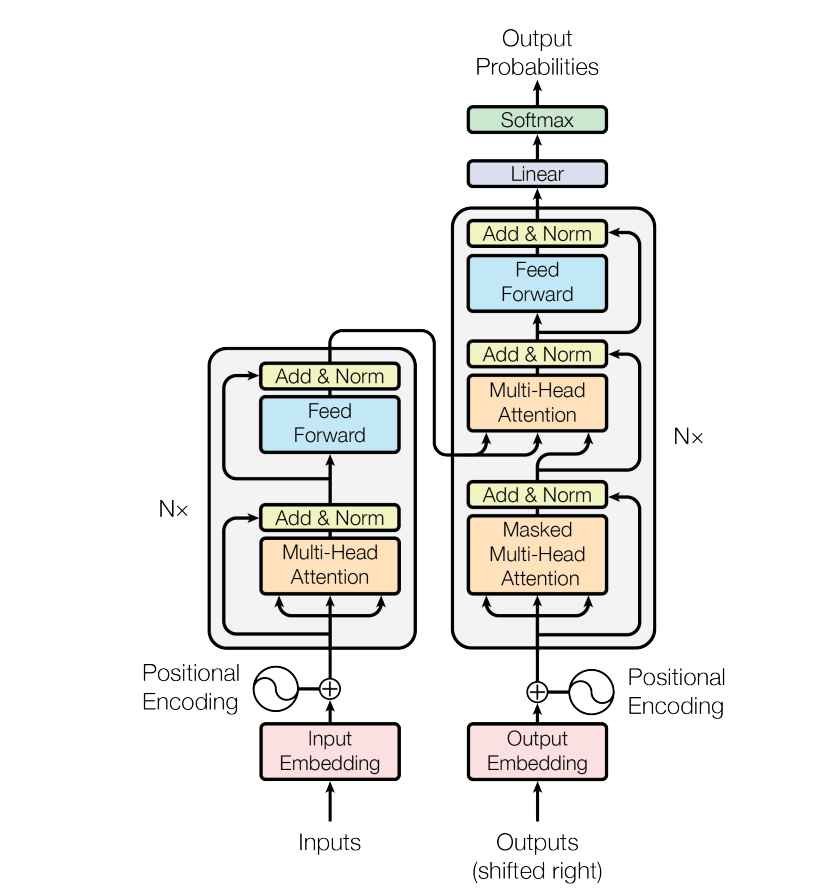
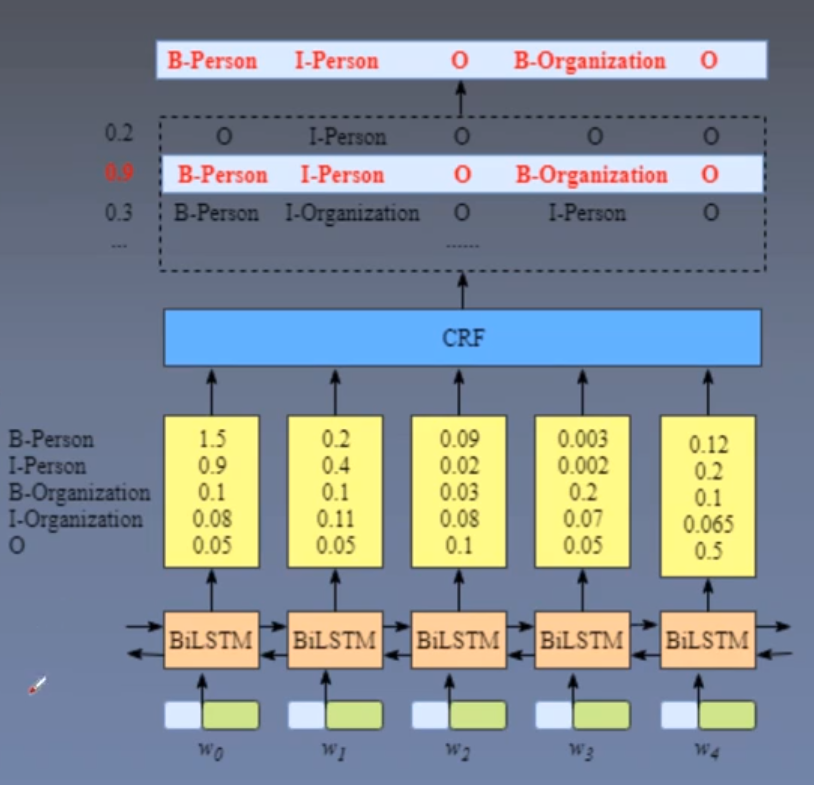
我们都知道命名实体识别任务最常用的网络结构是BiLSTM + CRF的结构,在transformer被提出之后,transformer也被用于命名实体识别任务,但是一般是使用Transformer的Encoder模块作为特征提取器,后面还是使用softmax、线性层或CRF层,也就是说Transformer的Decoder模块是不使用的(例如预训练模型BERT也是仅堆叠transformer encoder)。
那么为什么在命名实体识别任务中不使用Decoder模型呢?
其实答案是比较容易理解的,我们都知道Decoder是利用Encoder得到的memory和当前的输出,自回归的不断给出下一个概率最高的输出,所以Decoder是一个主要用于生成的模型,也是目前最火热的大模型如GPT最主要的核心结构,即主要用于生成大段的文本,而命名实体识别任务本质上是一个序列标注任务,其并不需要根据输入文本去生成其他文本,它只需要判断给定文本每个字是否属于实体以及实体的类型,所以并不需要Decoder模块,同样的序列的分类任务也不需要Decoder模块。
当然不需要不等于不能用,你也可以把序列标注、序列分类任务转变成生成任务,但是这样会使得你的模型结构变得更加复杂,效率会下降,效果也并不一定能得到提升。
在Transformer一步步实现一文中我们已经理解了transformer的实现过程,在这一篇中我们要将transformer的encoder部分应用于命名实体识别任务。