PyTorch的自动微分(autograd)
计算图
计算图是用来描述运算的有向无环图
计算图有两个主要元素:结点(Node)和边(Edge)
结点表示数据,如向量、矩阵、张量
边表示运算,如加减乘除卷积等
用计算图表示:y = (x + w) (w + 1)
令 a = x + w,b = w + 1
则 y = a b
用计算图来表示这一计算过程: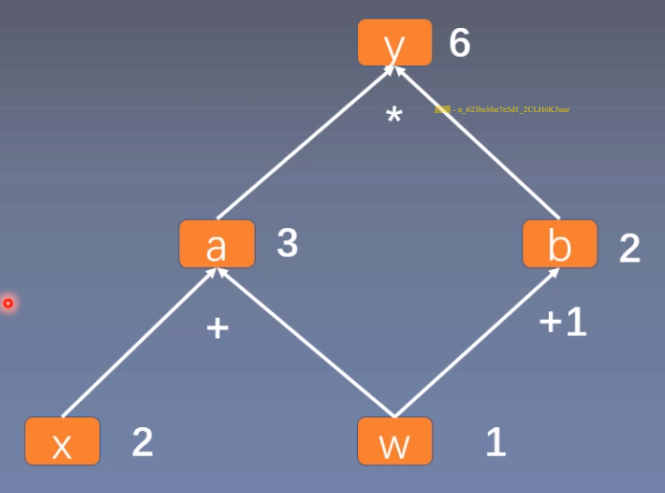
使用计算图可以更方便的求导
Pytorch中的张量学习Tensor是pytorch中非常重要且常见的数据结构,相较于numpy数组,Tensor能加载到GPU中,从而有效地利用GPU进行加速计算。但是普通的Tensor对于构建神经网络还远远不够,我们需要能够构建计算图的 tensor,这就是 Variable。Variable 是对 tensor 的封装,主要用于自动求导。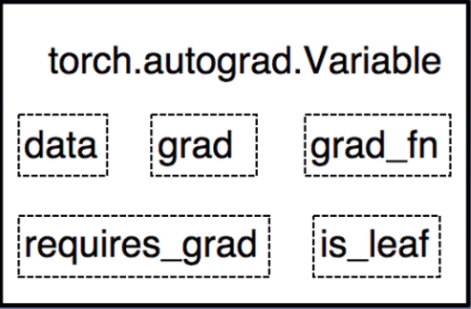
grad:data的梯度grad_fn:创建tensor的function,是自动求导的关键 pwd:显示当前目录
git init:把这个目录变成git可以管理的仓库
git clone: 从现有 Git 仓库中拷贝项目(类似 svn checkout)。
克隆仓库的命令格式为:
1 | git clone <repo> |
如果我们需要克隆到指定的目录,可以使用以下命令格式:
1 | git clone <repo> <directory> |
参数说明:
git config --list:显示当前的git配置信息
编辑 git 配置文件:
1 | git config -e # 针对当前仓库 |
或者:
1 | git config -e --global # 针对系统上所有仓库 |
设置提交代码时的用户信息:
1 | git config --global user.name "runoob" |
本篇文章主要是自己刚接触NER领域时,研读这篇《 A Survey on Deep Learning for Named Entity Recognition 》NER综述论文时翻译的中文版,这篇综述时间是2020年,可能近两年的部分成果暂未包含,很多内容是通过百度翻译直接翻的,部分内容进行了一定的调整。有少部分内容省略了,具体可以参考原论文,所有涉及的文献引用也请参考原论文。
命名实体识别(NER)是从属于预定义语义类型(如人、地点、组织等)的文本中识别固定指示符的任务;NER常作为问答系统、文本摘要和机器翻译等许多自然语言应用的基础;早期的NER系统通过消耗人力设计特定领域的特征和规则取得了巨大的成功,近年来,由连续实值向量表示和通过非线性处理的语义合成所支持的深度学习已被应用于NER系统,并产生了最先进的性能。在本文中,我们全面回顾了现有的面向NER的深度学习技术。 我们首先介绍现有的NER资源,包括已标记的NER语料库和现成的NER工具。然后,我们将NER现有的工作分为三类来进行系统的介绍:输入的分布式表示、上下文编码器和标记解码器。接下来,我们调研了在新的NER问题设置和应用上最具代表性的深度学习技术。最后,我们向读者介绍了NER系统面临的挑战和未来的研究方向。
将上次的问题全部解决之后,并且增加了一些特定法院名称和案由的训练数据,并且兼容了劳动仲裁开庭公告的抽取,模型的训练日志如下:1
2
3
4
5
6
7
8
9
10[2022-10-15 09:09:03,601 INFO] Epoch id: 5, Training steps: 1900, Avg loss: 0.000
[2022-10-15 09:09:25,614 INFO] Epoch id: 5, Training steps: 2000, Avg loss: 0.001
[2022-10-15 09:09:47,766 INFO] Epoch id: 5, Training steps: 2100, Avg loss: 0.000
[2022-10-15 09:10:09,830 INFO] Epoch id: 5, Training steps: 2200, Avg loss: 0.001
[2022-10-15 09:10:31,829 INFO] Epoch id: 5, Training steps: 2300, Avg loss: 0.001
[2022-10-15 09:10:53,881 INFO] Epoch id: 5, Training steps: 2400, Avg loss: 0.001
[2022-10-15 09:11:15,982 INFO] Epoch id: 5, Training steps: 2500, Avg loss: 0.001
[2022-10-15 09:11:38,139 INFO] Epoch id: 5, Training steps: 2600, Avg loss: 0.000
[2022-10-15 09:13:33,811 INFO] Report precision, recall, and f1:
[2022-10-15 09:13:33,812 INFO] 0.994, 0.994, 0.994
测试的结果如下:1
2
3
4
5
6correct/total: 2567/2600
accuracy: 0.9873076923076923
correct/total: 2570/2600
precision: 0.9884615384615385
correct/total: 2567/2600
precision: 0.9873076923076923
再接着上篇博客,本次依然采用自己生成训练数据的方式来训练,经过上一次的实验和优化,本次生成的训练数据标注错误的问题将会大大减少,因为很多实体是根据已有数据进行收集的,没有耗费大量的人力去逐条核验,难免会存在噪音,这一次修复了上篇中存在的各种噪音问题,并且还做了较多优化,具体效果如何,继续来看看吧。
这一次在上一次的训练结果上做了以下优化点: