Seq2Seq
encoder & decoder
Seq2Seq结构用于多个输入和多个输出的模型,但是输入和输出的大小可能并不一致,其本质上也是RNN网络的一个扩展,常见的应用场景包括:机器翻译、语音识别、文本摘要等。
常见的seq2seq的输出的计算方法包括以下两种:
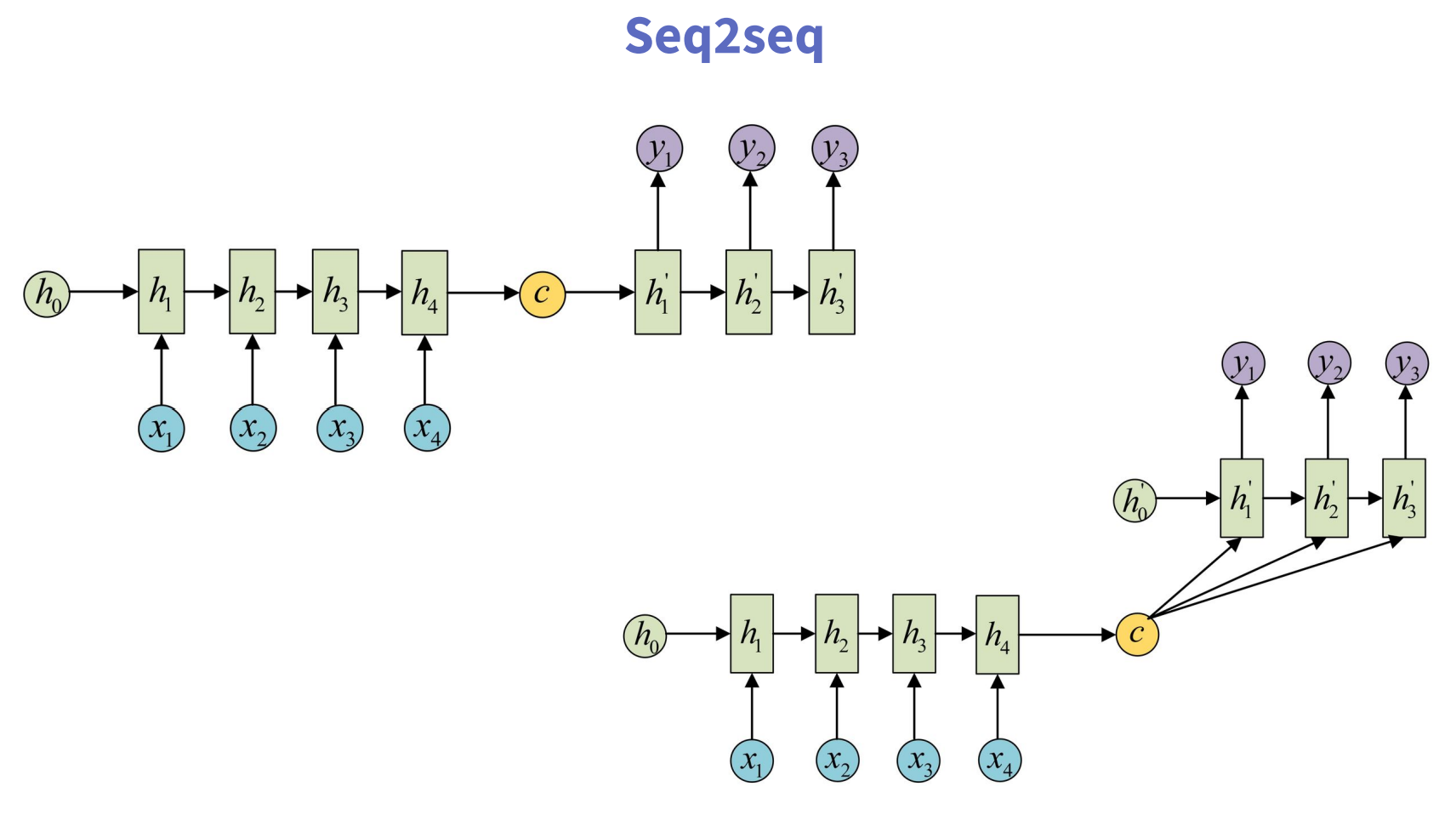
注意这里C到y1、y2、y3的计算,虽然有两种方式,但是C本质上是前半部分的最终输出状态,并非每个时间步的输出,这里搞清楚对于后续的注意力机制的理解也有帮助。
在seq2seq结构中,通常将整个模型分为encoder和decoder两个核心组件,连接两个组件的就是context vector,即Encoder组件生成的上下文向量。