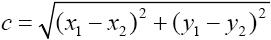KNN分类算法
KNN是机器学习种最简单的分类算法,而图像分类也是图像识别种最简单的问题,所以这里使用KNN来做图像分类,帮忙大家初步了解图像识别算法。
KNN(K-NearestNeighbor),即K-最近邻算法,顾名思义,找到最近的k个邻居,在前k个最近样本(k近邻)中选择最近的占比最高的类别作为预测类别。
KNN算法的计算逻辑:
- 给定测试对象,计算它与训练集中每个对象的距离;
- 圈定距离最近的k个训练对象,作为测试对象的邻居;
- 根据这k个近邻对象所属的类别,找到占比最高的那个类别作为测试对象的预测类别。
在KNN中,有两个方面的因素会影响KNN算法的准确度:一个是距离计算,另一个是k的选择。
一般使用两种比较常见的距离公式计算距离:
- 曼哈顿距离:
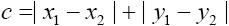
- 欧式距离: