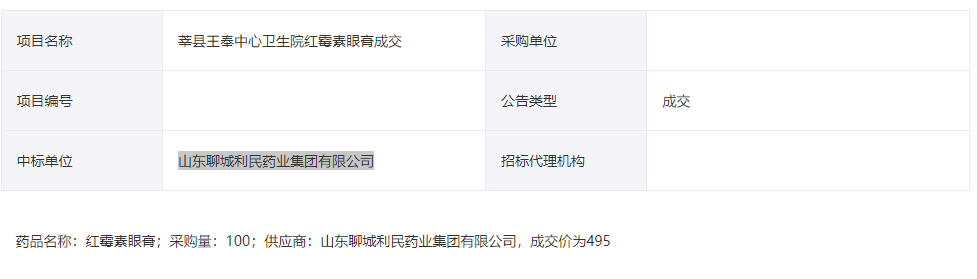
安装测试过程
建立虚拟环境:python -m venv 目录
启用虚拟环境:
linux下:source 目录/bin/activate;
windows下:cd Scripts–>activate.bat
安装tensorflow:pip install tensorflow
警告:Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
忽略警告:
1 | import os |
测试是否安装成功:
1 | import tensorflow as tf |